
Příručka aplikace Base 7.3
Kapitola 3,
Tabulky
Tento dokument je chráněn autorskými právy © 2022 týmem pro dokumentaci LibreOffice. Přispěvatelé jsou uvedeni níže. Dokument lze šířit nebo upravovat za podmínek licence GNU General Public License (https://www.gnu.org/licenses/gpl.html), verze 3 nebo novější, nebo the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0/), verze 4.0 nebo novější.
Všechny ochranné známky uvedené v této příručce patří jejich vlastníkům.
|
Vasudev Narayanan |
Steve Fanning |
Olivier Hallot |
|
|
|
|
|
Robert Großkopf |
Pulkit Krishna |
Jost Lange |
|
Dan Lewis |
Hazel Russman |
Jochen Schiffers |
|
Steve Schwettman |
Jean Hollis Weber |
|
Jakékoli připomínky nebo návrhy k tomuto dokumentu prosím směřujte do fóra dokumentačního týmu na adrese https://community.documentfoundation.org/c/documentation/loguides/ (registrace je nutná) nebo pošlete e-mail na adresu: loguides@community.documentfoundation.org.
Poznámka
Vše, co napíšete do fóra, včetně vaší e-mailové adresy a dalších osobních údajů, které jsou ve zprávě napsány, je veřejně archivováno a nemůže být smazáno. E-maily zaslané do fóra jsou moderovány.
Vydáno Srpen 2022. Založeno na LibreOffice 7.3 Community.
Jiné verze LibreOffice se mohou lišit vzhledem a funkčností.
Některé klávesové zkratky a položky nabídek jsou v systému macOS jiné než v systémech Windows a Linux. V následující tabulce jsou uvedeny nejdůležitější rozdíly, které se týkají informací v této knize. Podrobnější seznam se nachází v nápovědě aplikace.
|
Windows nebo Linux |
Ekvivalent pro macOS |
Akce |
|
Výběr v nabídce Nástroje > Možnosti |
LibreOffice > Předvolby |
Otevřou se možnosti nastavení. |
|
Klepnutí pravým tlačítkem |
Control + klepnutí a/nebo klepnutí pravým tlačítkem myši v závislosti na nastavení počítače |
Otevře se místní nabídka. |
|
Ctrl (Control) |
⌘ (Command) |
Používá se také s dalšími klávesami. |
|
Alt |
⌥ (Option) |
Používá se také s dalšími klávesami. |
|
Ctrl+Q |
⌘ + Q |
Ukončí LibreOffice |
Databáze ukládají data do tabulek. Hlavní rozdíl oproti tabulkám v databázi a oblasti buněk v jednoduchém tabulkovém procesoru spočívá v tom, že datový typ polí musí být předem jasně definován. Databáze například neumožňuje, aby textové pole obsahovalo čísla pro použití ve výpočtech. Taková čísla se zobrazují, ale pouze jako řetězce, jejichž skutečná číselná hodnota je nula. Stejně tak nelze obrázky zahrnout do všech typů polí.
Podrobnosti o tom, které typy dat jsou k dispozici, lze získat v okně Návrh tabulky v programu Base. Typy dat jsou uvedeny v příloze A této knihy.
Jednoduché databáze jsou založeny pouze na jedné tabulce. Všechny datové prvky se zadávají nezávisle, což může vést k vícenásobnému zadávání stejných údajů. Tímto způsobem lze vytvořit jednoduchý adresář pro soukromé použití. Adresář školy nebo sportovního svazu však může obsahovat tolik opakujících se poštovních směrovacích čísel a míst, že je lepší umístit tato pole do jedné nebo dokonce dvou samostatných tabulek.
Ukládání dat do samostatných tabulek pomáhá:
Omezit opakované zadávání stejného obsahu
Předcházet pravopisným chybám v důsledku opakovaného zadávání
Zlepšit filtrování dat v zobrazených tabulkách
Při vytváření tabulky bychom měli vždy zvážit, zda se v tabulce může vyskytovat více opakování, zejména textu nebo obrázků (které spotřebovávají velké množství kapacity úložiště). Pokud ano, je třeba je exportovat do jiné tabulky. Jak to v zásadě udělat, je popsáno v kapitole 1, Úvod do programu Base, v části „Jednoduchá databáze – podrobný testovací příklad“.
Poznámka
Relační databáze je skupina tabulek, které jsou vzájemně propojeny společnými atributy. Účelem relační databáze je co nejvíce zabránit duplicitnímu zadávání datových prvků. Je třeba se vyvarovat nadbytečných dat.
Toho lze dosáhnout:
Rozdělením obsahu do co největšího počtu jedinečných polí (například místo jednoho pole pro kompletní adresu použijeme samostatná pole pro číslo domu, ulici, město a PSČ).
Zabráněním duplicitním údajům pro jedno pole ve více záznamech (například importem PSČ a města z jiné tabulky).
Tyto postupy se nazývají Normalizace databáze.
V této kapitole je řada těchto kroků podrobně vysvětlena na příkladu databáze pro knihovnu: Media_without_Macros. Sestavení tabulek pro tuto databázi je rozsáhlá práce, protože zahrnuje nejen přidávání položek do knihovny médií, ale také jejich následné půjčování.
Tabulky v interní databázi HSQLDB mají vždy charakteristické, jedinečné pole, primární klíč. Toto pole musí být definováno před zápisem jakýchkoli dat do tabulky. Pomocí tohoto pole lze vyhledat konkrétní záznamy v tabulce.
V některých případech je primární klíč tvořen kombinací několika polí. Tato pole musí být jedinečná, pokud jsou posuzována společně. To se nazývá složený primární klíč.
Poznámka
Kombinace polí ve složeném primárním klíči je jedinečná, pokud každý záznam tabulky obsahuje jedinečnou kombinaci hodnot těchto polí.
Předpokládejme, že existují dvě tabulky, Tabulka1 a Tabulka2. Tabulka 2 může obsahovat pole, které označuje záznam v tabulce 1. Zde je primární klíč tabulky 1 zapsán jako hodnota v poli tabulky 2. Tabulka 2 má nyní pole, které ukazuje na pole klíče jiné tabulky, známé jako cizí klíč. Tento cizí klíč existuje v tabulce 2 vedle jejího primárního klíče.
Čím více relací je mezi tabulkami, tím složitější je úloha návrhu. Obrázek 1 znázorňuje celkovou strukturu tabulek této příkladové databáze, zmenšenou tak, aby odpovídala velikosti stránky tohoto dokumentu. Chceme-li si přečíst obsah, zvětšíme stránku na 200 %.
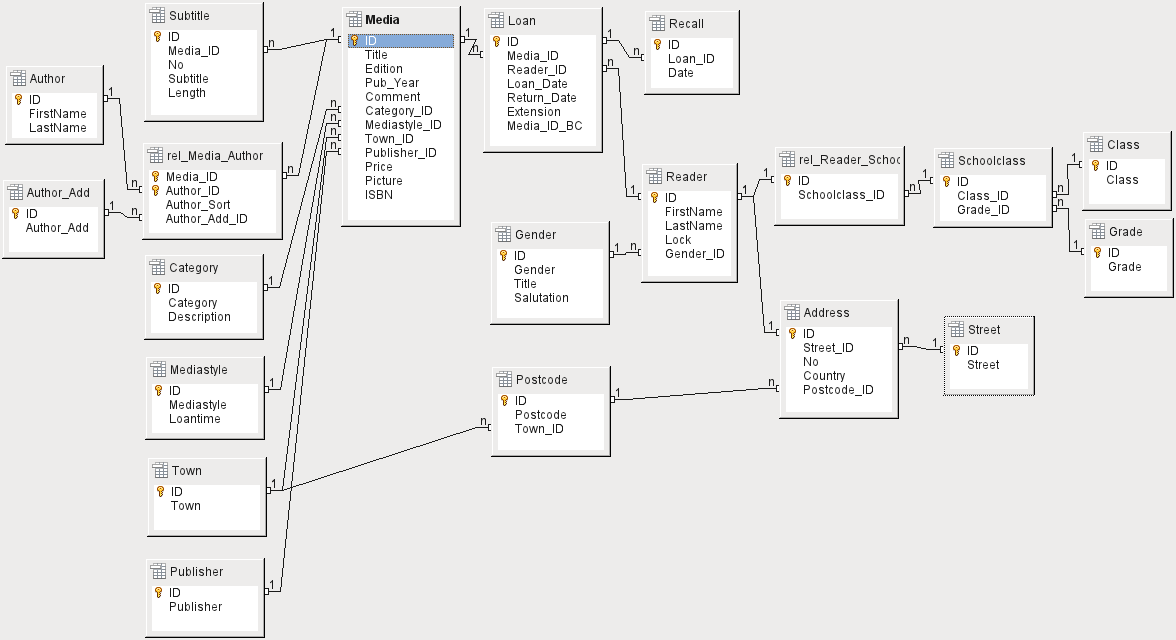
Obrázek 1: Diagram vztahů pro databázi Media_without_Macros
Databáze Media_without_Macros obsahuje názvy médií v jedné tabulce. Vzhledem k tomu, že tituly mohou mít více podtitulů nebo někdy vůbec žádné, jsou podtituly uloženy v samostatné tabulce.
Relace, ve kterém může mít pole více než jeden cizí klíč, se nazývá relací jeden k mnoha (1:n). Jednomu médiu může být přiřazeno mnoho podtitulů, například mnoho názvů skladeb na hudebním CD. Primární klíč pro tabulku Media je uložen jako cizí klíč v tabulce Subtitle. Většina relací mezi tabulkami v databázi jsou vztahy typu „jeden k mnoha“.
Databáze pro knihovnu může obsahovat tabulku se jmény autorů a tabulku s médii. Spojitost mezi autorem a například knihami, které napsal, je zřejmá. Knihovna může obsahovat více knih od jednoho autora. Může také obsahovat knihy s více autory. Tato relace , ve které mohou mít obě tabulky více než jeden cizí klíč, se nazývá mnoho k mnoha (n:m). Takové relace vyžadují tabulku, která funguje jako prostředník mezi oběma příslušnými tabulkami. To je na obrázku 2 znázorněno tabulkou rel_Media_Author.
V praxi se tedy relace n:m řeší tak, že se považuje za dvě relace 1:n. V mezitabulce se může pole Media_ID vyskytovat více než jednou, stejně jako pole Author_ID. Pokud je však použijeme jako pár, nedochází k duplikaci: žádné dva páry nejsou identické. Tato dvojice tedy splňuje požadavky na primární klíč pro mezi tabulku.
Obrázek 2: Příklad relace 1:n; relace n:m
Poznámka
Pro danou hodnotu Media_ID existuje pouze jeden název média a jedno ISBN. Pro danou hodnotu Author_ID existuje pouze jedno jméno a příjmení autora. Pro danou dvojici těchto hodnot tedy existuje pouze jedno číslo ISBN a pouze jeden autor. Díky tomu je tato dvojice jedinečná.
Obrázek 3: Příklad relace 1:1
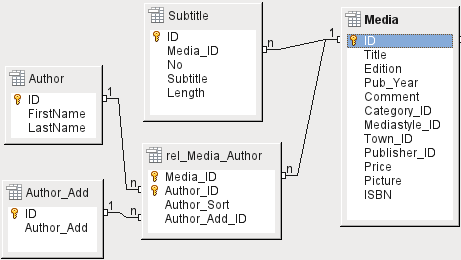
V tabulce Reader byla předem naplánována pouze pole, která jsou přímo nezbytná. Naše databáze však zahrnuje dva případy: školní a veřejnou knihovnu. U databáze školní knihovny je u čtenáře vyžadována také školní třída. Ve školních třídních výkazech můžeme v případě potřeby zjistit adresy dlužníků. Proto není nutné tyto adresy uvádět v databázi školní knihovny. Relace žáků ke třídě školy je rovněž oddělen od tabulky čtenářů, protože mapování na třídy není ve všech oblastech vhodné. Mezi čtenářem a adresou a čtenářem a třídou existuje vztah 1:1.
V databázi pro veřejnou knihovnu jsou vyžadovány adresy čtenářů. Pro každého čtenáře existuje jedna adresa. Pokud je na stejné adrese více čtenářů, bylo by nutné tuto strukturu zadat znovu, protože primární klíč tabulky Reader je zadán přímo jako primární klíč v tabulce Address. Primární klíč a cizí klíč jsou v tabulce Address jeden a tentýž. Jedná se tedy o relaci 1:1.
Relace 1:1 neznamená, že pro každý záznam v tabulce bude existovat odpovídající záznam v jiné tabulce. Nejvýše však bude existovat pouze jeden odpovídající záznam. Relace 1:1 tedy vede k tomu, že se exportují pole, která budou vyplněna obsahem pouze některých záznamů.
Příkladová databáze (Media_without_Macros) musí splňovat tři požadavky: přidávání a odebírání médií, výpůjčky a správa uživatelů.
Nejprve je třeba přidat média do databáze, aby s nimi knihovna mohla pracovat. Pro jednoduché shrnutí sbírky médií však můžeme vytvořit jednodušší databáze pomocí průvodce; to by mohlo být pro domácí použití dostačující.
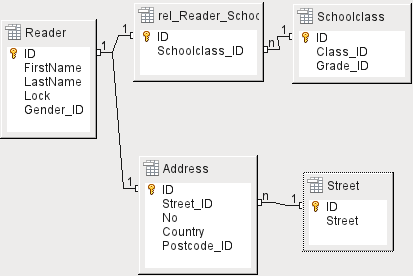
Centrální tabulkou pro přidávání médií je tabulka Media (viz obrázek 4).
V této tabulce se předpokládá, že všechna pole, která jsou přímo zadána, se nepoužívají také pro jiná média se stejným obsahem. Proto je třeba se vyhnout duplicitě.
Z tohoto důvodu jsou v tabulce plánována pole s názvem, ISBN, obrázkem obálky a rokem vydání. Seznam polí lze v případě potřeby rozšířit. Knihovníci tak mohou například chtít zahrnout pole pro velikost (počet stran), název série atd.
Tabulka Subtitle obsahuje podrobný obsah CD. Vzhledem k tomu, že CD může obsahovat několik hudebních skladeb, záznam jednotlivých skladeb v hlavní tabulce by vyžadoval mnoho dalších polí (Subtitle 1, 'Subtitle 2 atd.) nebo by se stejná položka musela zadávat mnohokrát. Tabulka Subtitle je tedy v relaci n:1 k tabulce Media.
Pole tabulky Subtitle jsou (kromě samotného podnadpisu) pořadové číslo podnadpisu a doba trvání stopy. Pole Length musí být nejprve definováno jako pole pro čas. Tímto způsobem lze vypočítat celkovou dobu trvání CD a v případě potřeby ji zobrazit v přehledu.
Autoři mají k médiím relaci n:m. Jedna položka může mít několik autorů a jeden autor může vytvořit několik položek. Tato relace je řízena tabulkou rel_Media_Author. Primárním klíčem této propojovací tabulky je cizí klíč vytvořený z tabulek Author a Media. Tabulka rel_Media_Author obsahuje dodatečné třídění autorů (Author_Sort), například podle pořadí, v jakém jsou v knize uvedeni. Kromě toho se v případě potřeby k autorovi přidá doplňující označení, jako je producent, fotograf apod.
Category, Mediastyle, Town a Publisher mají relaci 1:n.
Pro pole Category může malá knihovna použít hodnoty jako Art nebo Biology. Pro větší knihovny jsou k dispozici obecné systémy pro knihovny. Tyto systémy poskytují jak zkratky, tak úplné popisy. Obě pole se proto zobrazují v položce Category.
Mediastyle je spojen s výpůjční dobou Loantime. Například videodisky DVD se zásadně půjčují na 7 dní, ale knihy se mohou půjčovat na 21 dní. Pokud je výpůjční doba spojena s nějakým jiným kritériem, dojde k odpovídajícím změnám v naší metodice.
Tabulka Town slouží nejen k ukládání údajů o poloze z médií, ale také k ukládání polohy použité v adresách uživatelů.
Protože se Publishers (vydavatelé) také často opakují, je pro ně vytvořena samostatná tabulka.
Tabulka Media má celkem čtyři cizí klíče a jeden primární klíč, který se používá jako cizí klíč ve dvou tabulkách, jak ukazuje obrázek 4.
Obrázek 4: Přidání médií
Ústřední tabulkou je tabulka Loan (viz obrázek 5). Je to spojovací článek mezi tabulkami Media a Reader.
Po vrácení média lze většinu jeho dat smazat, protože již nejsou potřeba. Dvě z těchto polí by však neměla být pole: ID a Loan_Date. Prvním z nich je primární klíč. Druhá možnost je, když byl předmět zapůjčen. Slouží ke dvěma účelům. Nejprve je užitečné určit nejoblíbenější média. Za druhé, pokud je při vynášení předmětu zjištěno jeho poškození, zobrazí se v tomto poli informace o tom, kdo si předmět vypůjčil jako poslední. Kromě toho se při vrácení položky zaznamená údaj Return_Date.
Podobně jsou do výpůjčního procesu integrovány i Reminders (upomínky). Každá upomínka se zadává zvlášť do tabulky Recall, aby bylo možné určit celkový počet upomínek.
Kromě doby prodloužení v týdnech je v záznamu o výpůjčce další pole, které umožňuje vypůjčit médium pomocí snímače čárového kódu (Media_ID_BC). Čárové kódy obsahují kromě individuálního Media_ID také kontrolní číslici, podle které může skener určit, zda je naskenovaná hodnota správná. Toto pole čárového kódu je zde uvedeno pouze pro testovací účely. Bylo by lepší, kdyby primární klíč tabulky Media bylo možné zadat přímo ve formě čárového kódu nebo kdyby se před uložením použilo makro, které by ze zadaného čísla čárového kódu odstranilo kontrolní číslici.
Nakonec musíme připojit čtenáře k výpůjčce. V tabulce Reader je v plánu uveden pouze název, volitelný zámek a cizí klíč odkazující na tabulku Gender.
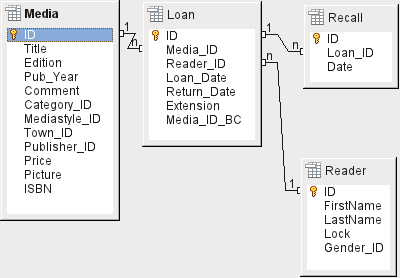
Obrázek 5: Relace v tabulce Loan
U tohoto návrhu tabulky se počítá se dvěma scénáři. Řetězec tabulek na obrázku 6 je určen pro školní knihovny. Zde není třeba uvádět adresy, protože žáky lze kontaktovat prostřednictvím školy. Upomínky není nutné rozesílat poštou, ale lze je distribuovat interně.
Řetězec adresy je nezbytný v případě veřejných knihoven. Zde je třeba zadat údaje, které budou potřebné pro vytvoření upomínacích dopisů. Viz obrázek 6.
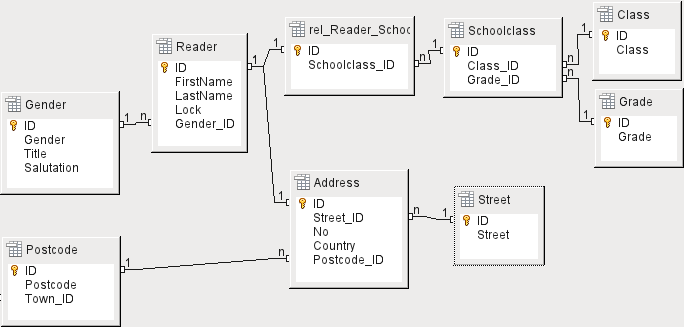
Obrázek 6: Čtenáři – řetězec školních tříd a řetězec adres
Tabulka Pohlaví zajišťuje, aby se v upomínkách používaly správné pozdravy. Psaní upomínek pak může být v maximální možné míře automatizováno. Kromě toho mohou být některá jména stejně mužská i ženská. Proto je nutné uvádět pohlaví zvlášť, i když se upomínky vypisují ručně.
Tabulka rel_Reader_Schoolclass má stejně jako tabulka Address relaci 1:1 s tabulkou Reader. Tato možnost byla zvolena proto, že může být vyžadována buď školní třída nebo adresa. V opačném případě by bylo možné vložit identifikátor Schoolclass_ID přímo do tabulky žáků; totéž by platilo pro kompletní obsah tabulky adres v systému veřejných knihoven.
Třída školy se obvykle skládá z označení ročníku a přípony paralelních tříd. Ve škole se čtyřmi paralelními třídami může tato přípona nabývat hodnot od a do d. Přípona se zadává v tabulce Class. Ročník je v samostatné tabulce Grade. Pokud se čtenáři na konci každého školního roku přesunou do vyšší třídy, můžeme jednoduše změnit zápis ročníku pro všechny.
Adresa je také rozdělena. Ulice se ukládá zvlášť, protože názvy ulic v oblasti se často opakují. Poštovní směrovací číslo a obec jsou odděleny, protože pro jednu oblast často existuje několik poštovních směrovacích čísel, a tedy více poštovních směrovacích čísel než obcí. V porovnání s tabulkou Address tak tabulka Postcode obsahuje výrazně méně záznamů a tabulka Town ještě méně.
Použití této struktury tabulek je dále vysvětleno v kapitole 4, Formuláře, v této knize.
Většina uživatelů LibreOffice bude k vytváření tabulek obvykle používat výhradně grafické uživatelské rozhraní (GUI). Přímé zadání příkazů SQL je nutné například tehdy, když je třeba dodatečně vložit pole na určitou pozici nebo nastavit standardní hodnotu po uložení tabulky.
Tabulková terminologie: Obrázek 7 ukazuje standardní rozdělení tabulek na sloupce a řádky.
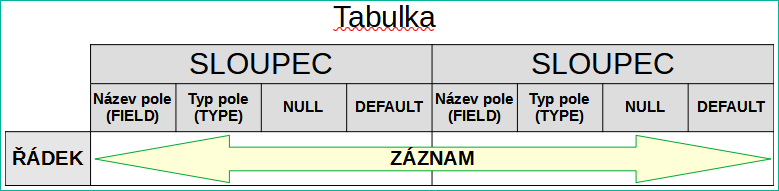
Obrázek 7: Standardní tabulková terminologie
Každý datový záznam je uložen ve vlastním řádku tabulky. Jednotlivé sloupce jsou z velké části definovány polem, typem a pravidly, která určují, zda může být pole prázdné. Podle typu lze také určit velikost pole ve znacích. Kromě toho lze zadat výchozí hodnotu, která se použije v případě, že do pole nebylo zadáno nic.
V základním grafickém uživatelském rozhraní jsou pojmy pro sloupec popsány poněkud odlišně, jak ukazuje obrázek 8.

Obrázek 8: Terminologie tabulky aplikace Base
Pole se změní na Název pole, Typ se změní na Typ pole. Název pole a Typ pole se zadávají do horní části okna Návrh tabulky. Další vlastnosti sloupce můžeme nastavit v části Vlastnosti pole ve spodní části. Tyto další vlastnosti závisí na typu sloupce definovaném výše a jsou také omezeny uživatelským rozhraním. Chceme-li překonat omezení rozhraní, jako je nastavení výchozí hodnoty pole data na skutečné datum zadání, použijeme vhodný příkaz SQL (viz „Přímé zadávání SQL příkazů“ na straně 1).
Poznámka
Výchozí hodnoty: Termín „Výchozí hodnota“ v grafickém uživatelském rozhraní neznamená to, co uživatel databáze obecně chápe jako výchozí hodnotu. Grafické uživatelské rozhraní viditelně zobrazuje určitou hodnotu, která je uložena spolu s daty.
Výchozí hodnota v databázi je uložena v definici tabulky. Do pole se pak zapíše vždy, když je pole v novém datovém záznamu prázdné. Při úpravě vlastností tabulky se nezobrazují výchozí hodnoty SQL.
Vytvoření databáze pomocí grafického uživatelského rozhraní (GUI) je vysvětleno krok za krokem na příkladu tabulky Media.
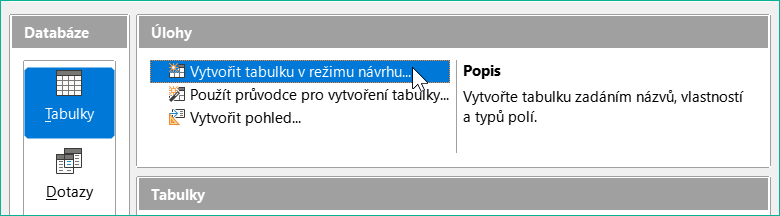
Obrázek 9: Klepneme na tlačítko Vytvořit tabulku v režimu návrhu
Spustíme editor tabulky klepnutím na Vytvořit tabulku v režimu návrhu.
Pole ID:
Do prvního sloupce zadáme Název pole ID. Poté se klávesou Tab přesuneme do sloupce Typ pole. Případně klepneme myší na další sloupec a vybereme jej nebo stiskneme klávesu Enter.
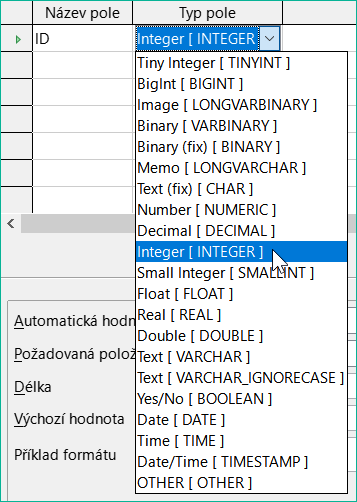
Obrázek 10: Výběr typu Integer pro pole ID
Jako typ pole vybereme ze seznamu Integer [INTEGER]. Výchozí hodnota je Text [VARCHAR]. Celá čísla mohou obsahovat až 10 číslic. Kromě toho je Integer jediným typem dostupným v grafickém uživatelském rozhraní, kterému lze přiřadit automaticky se zvyšující hodnotu.
Tip
Chceme-li rychle provést výběr ze seznamu Typ pole pomocí klávesnice, zadáme znak odpovídající prvnímu písmenu výběru. Opakovaným zadáním tohoto znaku lze výběr změnit. Například zadáním D můžeme změnit výběr z Date na Date/Time nebo na Decimal.
Nastavíme ID jako primární klíč klepnutím pravým tlačítkem myši na obdélník před názvem pole a výběrem možnosti Primární klíč z místní nabídky. Před ID se zobrazí symbol klíče.
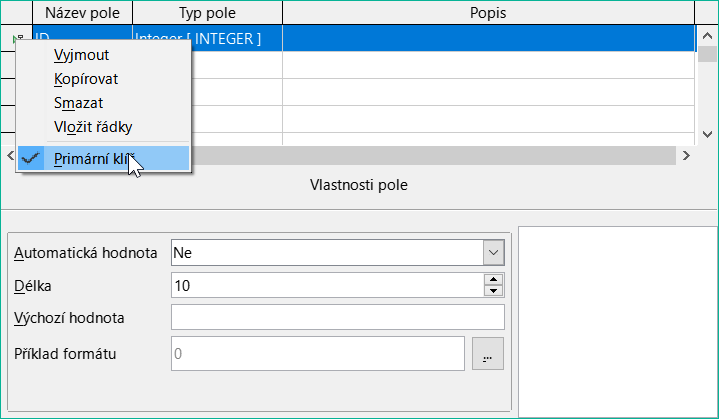
Obrázek 11: Nastavení primárního klíče pomocí místní nabídky
Poznámka
Primární klíč slouží pouze k jednomu účelu – k jednoznačné identifikaci záznamu. Proto můžeme pro toto pole použít libovolný název. V příkladu jsme použili běžně používaný název ID (identifikace).
V části Vlastnosti pole pro pole ID změníme vlastnost Automatická hodnota z Ne na Ano. Tím se primární klíč bude automaticky zvyšovat. V interní databázi začíná počítání od 0.
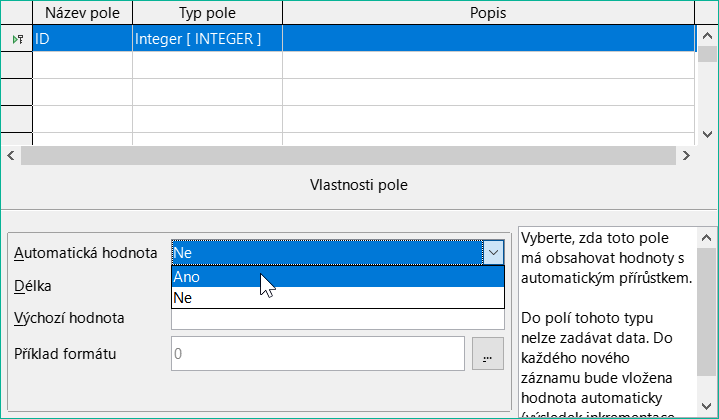
Obrázek 12: Nastavení hodnoty AutoValue na Yes pro pole ID
Dalším polem je Title.
Název pole Title se zadává do sloupce Název pole.
Typ pole zde není třeba měnit, protože je již nastaven na Text [VARCHAR].
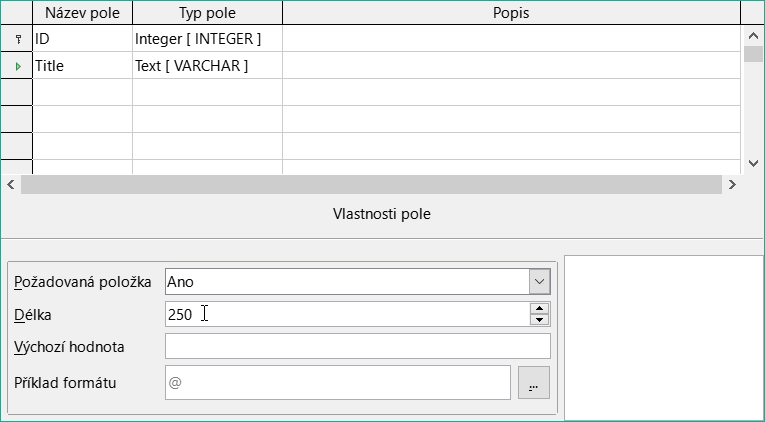
Obrázek 13: Přidání pole Title
Ve vlastnostech pole by měla být délka pole pro názvy médií zvýšena na 250.
Ve vlastnostech pole změníme Požadovaná položka z Ne na Ano. Médium bez názvu by nemělo smysl.
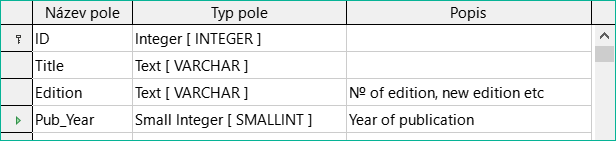
Obrázek 14: Přidání polí Edition a Pub_Year
Popis může být cokoli. Tento sloupec může zůstat také prázdný. Popis slouží pouze k vysvětlení obsahu pole pro ty, kteří si chtějí definici tabulky prohlédnout později.
Pro pole Pub_Year byl zvolen typ Small Integer [SMALLINT]. Může obsahovat celé číslo o maximální velikosti 5 číslic. Pokud je datum zveřejnění celé číslo, je zajištěno, že nebude obsahovat žádné znaky abecedy.
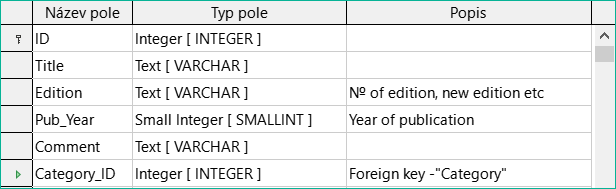
Obrázek 15: Přidání polí Comment a Category_ID
Pro pole Category_ID jsme zvolili typ Integer. V tabulce Category by měl mít primární klíč tento typ pole, takže to, co je zde zadáno jako cizí klíč, musí mít stejný typ. To platí také pro následující cizí klíče Mediastyle_ID, Town_ID a Publisher_ID.
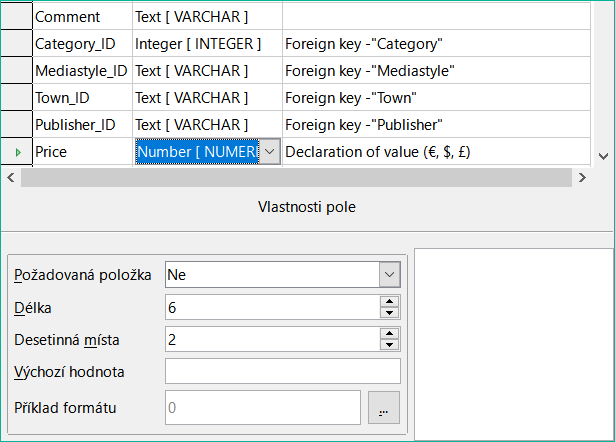
Obrázek 16: Přidání polí Mediastyle_ID, Town_ID, Publisher_ID a Price
Pro pole Price použijeme typ [NUMERIC] nebo [DECIMAL]. Oba tyto typy polí mohou obsahovat hodnoty s desetinnou čárkou. V části Vlastnosti pole nastavíme délku 6 znaků. To by mělo být pro ceny našich médií dostačující.
Počet desetinných míst je nastaven na 2. Tím se získá maximální cena 9999,99, protože samotná desetinná čárka se do počtu nezapočítává.
Ve formátu není nutné uvádět znak $, protože vzorec si s ním poradí sám.
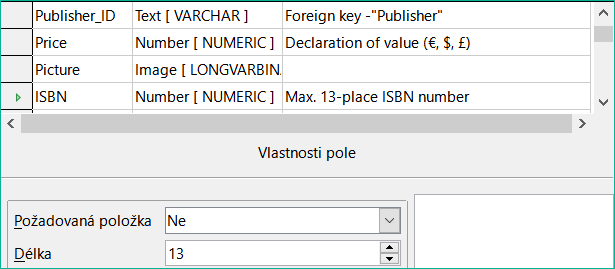
Obrázek 17: Přidání polí Picture a ISBN
Pro pole ISBN použijeme typ [NUMERIC]. Tuto hodnotu lze nastavit přesně na správnou délku pole ISBN. Čísla ISBN jsou dlouhá 10 nebo 13 znaků. Budou uloženy jako čísla bez oddělovače. Délka je nastavena na maximálně 13 znaků. Počet desetinných míst je nastaven na nulu.
Uložíme tabulku s názvem Media.
Nyní jsme vytvořili hlavní tabulku ukázkové databáze. Všechny ostatní tabulky lze vytvořit podobným způsobem. Dbáme na to, aby typy polí a jejich vlastnosti odpovídaly tomu, co bude v těchto polích uloženo. Tím se liší od tabulkového procesoru, v němž může sloupec obsahovat směsici vlastností.
Poznámka
Pořadí polí v tabulce lze měnit pouze do doby, než je tabulka poprvé uložena v grafickém uživatelském rozhraní. Při následném zadávání dat přímo do tabulky je pořadí polí pevné. Pořadí však lze v dotazech, formulářích a sestavách libovolně měnit.
Pokud při návrhu tabulky není nastaven primární klíč, budeme při ukládání tabulky dotázáni, zda má být primární klíč vytvořen. To znamená, že v tabulce chybí významné pole. Bez primárního klíče nelze v grafickém uživatelském rozhraní k tabulce v databázi HSQLDB přistupovat. Toto pole se obvykle jmenuje ID a má typ INTEGER s Automatickou hodnotou > Ano, který hodnotu pole automaticky zvýší. Klepnutím na Ano v dialogovém okně primárního klíče se automaticky vytvoří pole primárního klíče. Klepnutím na tlačítko Ne nebo Zrušit v dialogovém okně primárního klíče můžeme označit existující pole jako primární klíč klepnutím pravým tlačítkem myši na zelenou šipku vlevo od příslušného pole.
Jako primární klíč můžeme použít i kombinaci polí. Pole musí být deklarována jako primární klíč společně (držíme stisknutou klávesu Control nebo Shift). Pak klepnutím pravým tlačítkem myši vytvoříme kombinaci všech zvýrazněných polí jako primární klíč.
Pokud jsou do této tabulky importovány informace z jiných tabulek (například z databáze adres s externě uloženými poštovními směrovacími čísly a obcemi), musí být zahrnuto pole se stejným datovým typem jako primární klíč jiné tabulky. Předpokládejme, že tabulka Postcode má jako primární klíč pole ID s typem Tiny Integer. V tabulce Address pak musí být pole Postcode_ID s typem Tiny Integer. Do tabulky Address se vždy zadává číslo, které slouží jako primární klíč pro dané místo v tabulce Postcode. To znamená, že tabulka Address má nyní kromě vlastního primárního klíče také cizí klíč.
Pravidlem pro pojmenování polí v tabulce je, že žádná dvě pole nemohou mít stejný název. Proto se v tabulce Address nemůže vyskytovat druhé pole s názvem ID jako cizí klíč.
Typ pole lze měnit pouze v omezeném rozsahu. Zvýšení vlastnosti (délka textového pole, větší velikost v čísle) je vždy povoleno, protože všechny již zadané hodnoty budou odpovídat novým podmínkám. Snížení vlastnosti pravděpodobně způsobí problémy a může vést ke ztrátě dat.
Časová pole v tabulkách nelze vytvořit tak, aby obsahovala zlomky sekundy. K tomu potřebujeme pole Timestamp. Grafické uživatelské rozhraní však umožňuje vytvořit pouze pole Timestamp s datem, hodinou, minutou a sekundou. Toto pole budeme muset následně upravit pomocí Nástroje > SQL..
ALTER TABLE "Název_tabulky" ALTER COLUMN "Název_pole" TIMESTAMP(6)
Parametr „6“ umožňuje ukládat do pole Timestamp zlomky sekundy.
Formátování představuje uživateli hodnoty v databázi a umožňuje zadávat hodnoty v závislosti na konvencích zadávání obvyklých v dané zemi. Bez formátování se desetinná místa oddělují tečkou, zatímco většina evropských zemí používá čárku (4.21 místo 4,21). Hodnoty data jsou uvedeny ve tvaru 2014-12-22. Při nastavování formátování je třeba brát ohled na místní standardy.
Formátování poskytuje pouze reprezentaci obsahu. Datum reprezentované dvoumístným číslem roku je stále uloženo jako čtyřmístný rok. Pokud je vytvořeno pole pro číslo se dvěma desetinnými místy, jako je například poplatek za prodlení (tzv. kontokorent) v následujícím příkladu, je číslo uloženo se dvěma desetinnými místy, i když je chybně nastaveno jejich nezobrazování. Do pole formátovaného bez desetinných míst lze zadat číslo se dvěma desetinnými místy. Zdá se, že desetinná část při zadávání zmizí, ale je viditelná, pokud se formátování obejde.
Chceme-li zobrazit pouze čas, nikoli datum, můžeme formuláře naformátovat tak, aby zobrazovaly pouze potřebné informace a zbytek pole Timestamp skryly. V případě ukládání času například ze stopek lze minuty, sekundy a zlomky sekundy v časovém razítku zobrazit pomocí formátu MM:SS.00 na displeji. Formát bez data lze nastavit později ve Formulářích pomocí formátovaného pole, nikoli však přímo do pole Timestamp.
Formátování polí při vytváření tabulky nebo následně prostřednictvím vlastností polí se provádí v samostatném dialogovém okně:
Obrázek 18: Klepnutím na tlačítko vedle příkladu Formát se zobrazí dialogové okno Formát pole
Tlačítko vedle Vlastnosti pole > Příklad formátu otevře dialogové okno pro změnu formátu.
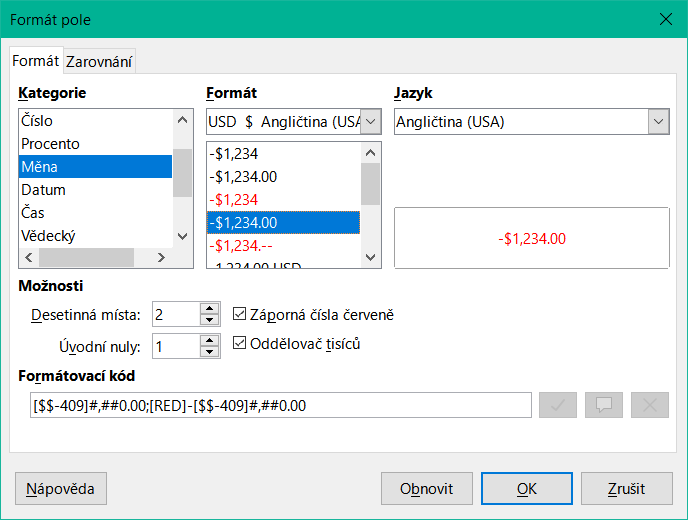
Obrázek 19: Dialogové okno Formát pole
Při vytváření měnových polí dbáme na to, aby číselné pole mělo nastavena dvě desetinná místa. Při vytváření tabulky v grafickém uživatelském rozhraní lze provést formátování, aby se při zadávání použila příslušná měna. To má vliv pouze na vstup do tabulky a na dotazy, které používají vstupní hodnotu bez přepočtu. Ve formulářích musí být označení měny samostatně formátováno.
Poznámka
Program Base ukládá formátování tabulek při vytváření polí nebo během zadávání dat, pokud jsou formáty sloupců upraveny klepnutím pravým tlačítkem myši na záhlaví sloupců. Šířky sloupců na vstupní obrazovce se ukládají i při úpravě během zadávání dat.
V dotazech, formulářích nebo sestavách lze formátování zobrazení upravit podle potřeby.
V případě polí, která mají obsahovat procenta, je třeba vzít na vědomí, že 1 % musí být uloženo jako 0,01. Zápis procent proto vyžaduje alespoň dvě desetinná místa. Pokud je třeba uložit zlomková procenta, například 3,45, vyžaduje uložená číselná hodnota čtyři desetinná místa.
Někdy je užitečné kromě primárního klíče indexovat další pole nebo kombinaci dalších polí. Index urychluje vyhledávání a lze jej také použít k zabránění duplicitním záznamům.
Každý index má definované pořadí řazení. Pokud je tabulka zobrazena bez třídění, bude seřazení probíhat podle obsahu polí uvedených v indexu.
Obrázek 20: Výběr Nástroje > Návrh indexu
Otevřeme tabulku pro úpravy klepnutím pravým tlačítkem myši a použitím místní nabídky. Poté můžeme přistoupit k vytváření indexů pomocí Nástroje > Návrh indexu.
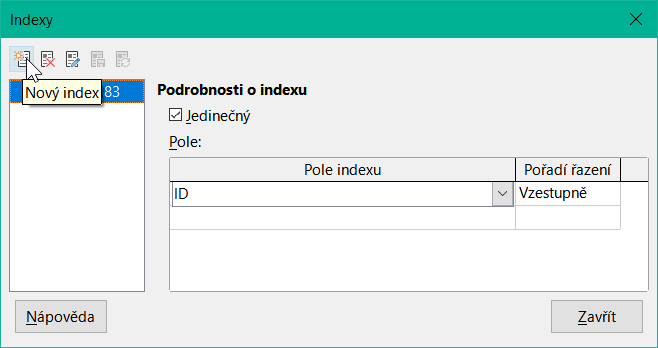
Obrázek 21: Vytvoření nového indexu
V dialogovém okně Indexy (obrázek 21) klepneme na Nový index a vytvoříme kromě primárního klíče také index.
Novému indexu je automaticky přiřazen název index1. Pole indexu určuje, které pole nebo která pole mají být použita pro tento index. Současně můžeme zvolit Pořadí řazení.
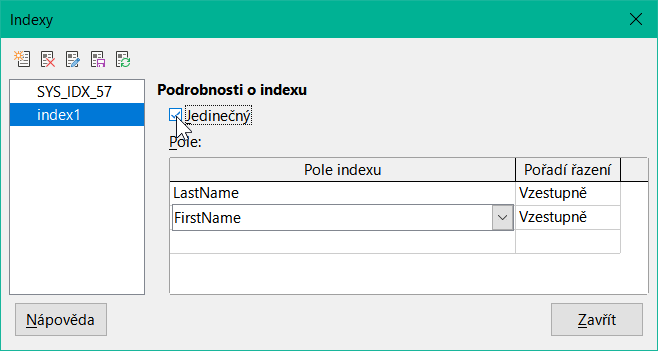
Obrázek 22: Index je definován jako Unique
V zásadě lze index vytvořit i z polí tabulky, která neobsahují jedinečné hodnoty. Na obrázku 22 byl však detail Index Jedinečný zaškrtnut, takže pole LastName spolu s polem FirstName může mít pouze položky, které se v této kombinaci ještě nevyskytují. Takže například jména Robert Miller a Robert Maier jsou možné, stejně tak Robert Miller a Eva Millerová.
Pokud je index vytvořen pouze pro jedno pole, vztahuje se jedinečnost pouze na toto pole. Takovým indexem je obvykle primární klíč. V tomto poli se může každá hodnota vyskytnout pouze jednou. V případě primárních klíčů navíc pole nesmí mít za žádných okolností hodnotu NULL.
Výjimečnou okolností pro jedinečný index je situace, kdy v poli není žádný záznam (pole je NULL). Protože NULL může mít libovolnou hodnotu, index používající dvě pole může mít v jednom z polí vždy opakovaně stejnou položku, pokud v druhém poli není žádná položka.
Poznámka
NULL se v databázích používá pro označení prázdné buňky, která nic neobsahuje. Pomocí pole NULL nelze provést žádný výpočet. To je rozdíl oproti tabulkovým procesorům, kde prázdná pole automaticky obsahují hodnotu 0 (nula).
Příklad: V databázi médií se při výpůjčce zadává číslo média a datum výpůjčky. Při vrácení položky se zadá datum vrácení. Teoreticky by index využívající pole Media_ID a ReturnDate mohl snadno zabránit opakovanému půjčování stejné položky, aniž by bylo zaznamenáno datum vrácení. To však nebude fungovat, protože datum vrácení nemá zpočátku žádnou hodnotu. Index zabrání tomu, aby položka byla dvakrát označena jako vrácená se stejným datem, ale neudělá nic jiného.
Nejlepší je vytvořit tabulky se všemi požadovanými nastaveními, aby nebylo nutné později měnit jejich konfiguraci. Při pozdější změně vlastností polí (název pole, povinný údaj apod.) může dojít k chybovým hlášením, která nejsou způsobena grafickým uživatelským rozhraním, ale pokusem o nežádoucí změnu základní databáze.
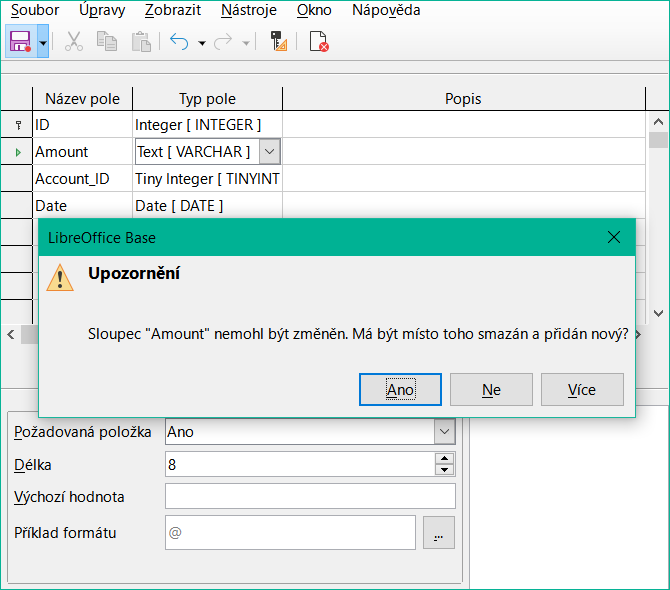
Obrázek 23: Chyba při pokusu o změnu požadované položky na Ano
V tomto případě se pole Amount vynuluje na hodnotu Vstup požadován=ano. Výstražný symbol nás upozorňuje, že tato změna může vést ke ztrátě dat. Jednoduchá změna není možná, protože již mohou existovat záznamy, které v tomto poli nemají žádný záznam.
Klepnutí na Ano vede k dalšímu chybovému hlášení, protože struktura databáze neumožňuje toto pole odstranit. Klepnutím na Ne se celá operace zruší. Volba Další možnosti je uvedena vždy, když je to možné, abychom získali další informace o řešení problému.
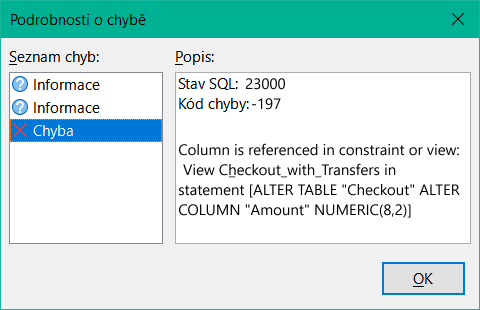
Obrázek 24: Dialogové okno Podrobnosti o chybě, když nelze změnit pole Amount
Chybové hlášení Sloupec je odkazován v omezení nebo zobrazení znamená:
Na sloupec s názvem pole „Amount“ se odkazuje v jiné části databáze. Může se jednat o definici omezení nebo zobrazení tabulky, které bylo vytvořeno některým uživatelem po vytvoření samotné tabulky. Z výše uvedeného obrázku vyplývá, že název omezení nebo zobrazení je View_Checkout_with_Transfers. Uživateli je tak jasné, kde v databázi je třeba provést změny. Například kód SQL pro zobrazení by mohl být nejprve uložen jako dotaz a poté by mohlo být zobrazení zničeno a proveden nový pokus o znovuvytvoření pole.
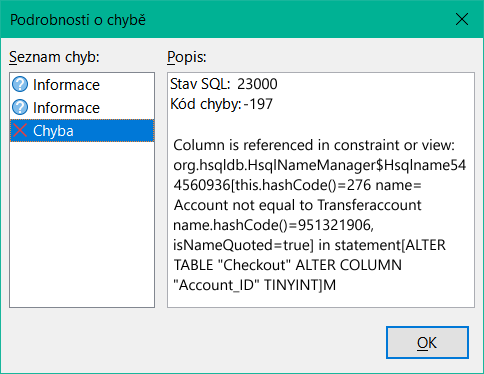
Obrázek 25: Dialogové okno Podrobnosti o chybě při nemožnosti změnit pole Account_ID
V tomto případě nás název omezení Account not equal to Transferaccount vede k definici tohoto omezení. Podmínkou je, že hodnota v poli Account_ID nesmí být stejná jako hodnota v poli TransferAccount_ID. Sloupec lze změnit pouze tehdy, pokud je tato podmínka odstraněna.
Pokud dojde k další chybě, je to s největší pravděpodobností způsobeno tím, že příslušné pole je propojeno s polem v jiné tabulce pomocí definovaného vztahu. V takovém případě je třeba před provedením změny přerušit vazbu pomocí Nástroje > Relace.
Pořadí polí v tabulce nelze po uložení databáze měnit. Zobrazení jiné sekvence vyžaduje dotaz.
Pole na konkrétní pozici v tabulce lze vložit pouze zadáním přímých příkazů SQL. Touto metodou však nelze přesouvat již vytvořená pole.
Na začátku je třeba nastavit vlastnosti tabulek: například která pole nesmí být NULL a která musí obsahovat standardní hodnotu (Default). Tyto vlastnosti nelze následně měnit pomocí grafického uživatelského rozhraní.
Výchozí hodnoty, které můžeme nastavit v grafickém uživatelském rozhraní, nejsou tak silné jako možné výchozí hodnoty v samotné databázi. Například nelze definovat výchozí hodnotu pole s datem jako datum zadání. To je možné pouze pomocí přímo zadaných příkazů SQL.
Chceme-li zadat příkazy SQL přímo, přejdeme na Nástroje > SQL.
Příkazy se zadávají v horní části okna (obrázek 26). V dolní části (Status) se zobrazuje úspěch nebo důvod neúspěchu. Výsledky dotazů lze zobrazit v poli Výstup, pokud je toto políčko zaškrtnuto.
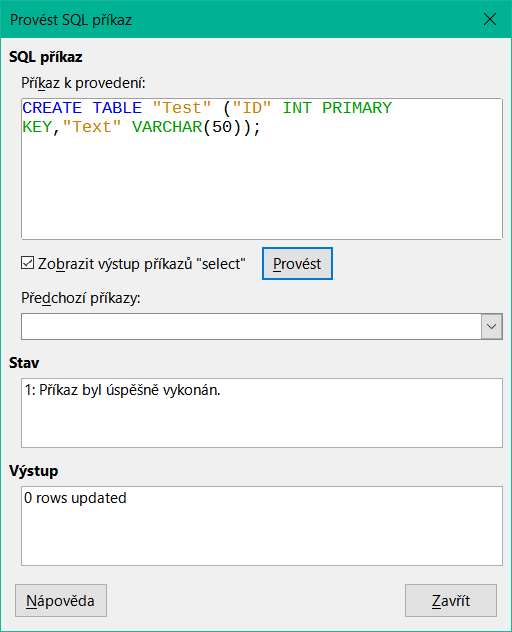
Obrázek 26: Dialog pro přímé zadávání příkazů SQL
Přehled možných příkazů pro vestavěný engine HSQLDB najdeme na adrese http://www.hsqldb.org/doc/1.8/guide/ch09.html. Obsah je popsán v následujících kapitolách. Některé příkazy mají smysl pouze při práci s externí databází HSQLDB (Zadat uživatele atd.). V případě potřeby se jimi zabývá kapitola „Práce s externí HSQLDB“ v dodatku této příručky.
Poznámka
LibreOffice je založen na verzi 1.8.0 HSQLDB. Aktuálně dostupná verze serveru je 2.5. Funkce nové verze jsou rozsáhlejší. Informace o nich můžeme nalézt na adrese http://hsqldb.org/web/hsqlDocsFrame.html. Popis verze 1.8 je nyní na adrese http://www.hsqldb.org/doc/1.8/guide/. Další popis je uveden v instalačních balíčcích pro HSQLDB, které si můžeme stáhnout ze stránky http://sourceforge.net/projects/hsqldb/files/hsqldb/.
Jednoduchý příkaz pro vytvoření použitelné tabulky je:
CREATE TABLE "Test" ("ID" INT PRIMARY KEY, "Text" VARCHAR(50));
Rozdělení tohoto příkazu:
CREATE TABLE "Test": Vytvoří tabulku s názvem "Test".
( ): zadané názvy polí, typy polí a možnosti se vloží do závorek.
"ID" INT PRIMARY KEY,: Název pole ID s číselným typem integer jako primárním klíčem;
"Text" VARCHAR(50): název pole Text s proměnnou délkou textu typu text a velikostí textu omezenou na 50 znaků.
Parametry příkazu CREATE:
CREATE [MEMORY | CACHED | [GLOBAL] TEMPORARY | TEMP | TEXT] TABLE "Table name" ( <Field definition> [, ...] [, <Constraint Definition>...] ) [ON COMMIT {DELETE | PRESERVE} ROWS];
[MEMORY | CACHED | [GLOBAL] TEMPORARY | TEMP | TEXT]:
CREATE TEXT TABLE "Text" ("ID" INT PRIMARY KEY, "Text" VARCHAR(50));
Vytvoří textovou tabulku v HSQLDB. Nyní musí být propojen s externím textovým souborem (například se souborem *.csv): SET TABLE "Text" SOURCE "Text.csv";
Soubor Text.csv musí samozřejmě obsahovat odpovídající pole ve správném pořadí. Při vytváření odkazu lze vybrat různé další možnosti. Podrobnosti nalezneme na http://www.hsqldb.org/doc/1.8/guide/guide.html#set_table_source-section.
Textové tabulky nejsou chráněny proti zápisu jinými programy. Může se tedy stát, že jiný program nebo uživatel změní tabulku právě ve chvíli, kdy k ní přistupuje databáze Base. Textové tabulky se používají především k výměně dat mezi různými programy.
Tabulky ve formátu TEXT (například CSV) nelze zapisovat do interních databází, které jsou nastaveny čistě v MEMORY, zatímco program Base nemá přístup k tabulkám TEMPORARY nebo TEMP. Příkazy SQL se v tomto případě provedou, ale tabulky se pomocí grafického uživatelského rozhraní nezobrazí (a nelze je tedy odstranit) a data zadaná prostřednictvím SQL nejsou pro dotazovací modul grafického uživatelského rozhraní rovněž viditelná, pokud není zabráněno automatickému odstranění obsahu po konečném odevzdání (pomocí ON COMMIT PRESERVE ROWS). Jakýkoli požadavek v tomto případě zobrazí tabulku bez jakéhokoli obsahu.
Tabulky sestavené přímo pomocí jazyka SQL se nezobrazují okamžitě. Musíme buď použít Zobrazení > Obnovit tabulky nebo databázi jednoduše zavřít a poté ji znovu otevřít.
Umožňuje zahrnout do definice pole výchozí hodnoty.
Do textových polí můžeme zadávat text v jednoduchých uvozovkách nebo NULL. Jediná povolená funkce SQL je CURRENT_USER. To má smysl pouze v případě, že se HSQLDB používá jako externí databáze serveru s několika uživateli.
U polí pro datum a čas lze datum, čas nebo jejich kombinaci zadat v jednoduchých uvozovkách nebo jako NULL. Je třeba zajistit, aby datum odpovídalo americkým konvencím (rrrr-mm-dd), aby čas měl formát hh:mm:ss a aby kombinovaná hodnota data a času měla formát rrrr-mm-dd hh:mm:ss.
Povolené funkce SQL:
pro aktuální datum – CURRENT_DATE, TODAY, CURDATE()
pro aktuální čas – CURRENT_TIME, NOW, CURTIME()
pro aktuální časové razítko dat – CURRENT_TIMESTAMP, NOW.
Pro logická pole (ano/ne) lze zadat výrazy FALSE, TRUE, NULL. Ty musí být zadány bez jednoduchých uvozovek.
U číselných polí je možné zadat libovolné platné číslo v daném rozsahu nebo NULL. Pokud zadáváme NULL, nepoužíváme uvozovky. Při zadávání desetinných míst dbáme na to, aby desetinný oddělovač byla tečka, nikoli čárka. (Někteří anglicky mluvící lidé používají čárku jako desetinnou tečku.)
Pro binární pole (obrázky atd.) je možné použít jakýkoli platný hexadecimální řetězec v jednoduchých uvozovkách nebo NULL. Příklad hexadecimálního řetězce je: 0004ff, což představuje 3 bajty: nejprve 0, pak 4 a nakonec 255 (0xff). Vzhledem k tomu, že binární pole je v praxi nutné zadávat pouze pro obrázky, je třeba znát binární kód obrázku, který má sloužit jako výchozí.
Poznámka
Šestnáctková soustava: Čísla jsou založena na 16. Smíšený systém složený z čísel 0 až 9 a písmen a až f poskytuje 16 možných číslic pro každý sloupec. Při použití dvou sloupců můžeme získat 16*16=256 možných hodnot. To odpovídá 1 Bajtu (28).
NOT NULL: Hodnota pole nemůže být NULL. Tuto podmínku lze uvést pouze v definici pole.
Příklad:
CREATE TABLE "Test" ("ID" INT GENERATED BY DEFAULT AS IDENTITY (START WITH 10), "Name" VARCHAR(50) NOT NULL, "Date" DATE DEFAULT TODAY);
Vytvoří se tabulka s názvem Test. Klíčové pole ID je definováno jako Automatická hodnota s hodnotami začínajícími na 10. Vstupní pole Name je textové pole s maximální velikostí 50 znaků. Nesmí být prázdné. Nakonec máme pole Date, které ve výchozím nastavení ukládá aktuální datum, pokud není zadáno jiné datum. Tato výchozí hodnota je platná pouze při vytvoření nového záznamu. Odstraněním data v existujícím záznamu zůstane pole prázdné.
UNIQUE ( "Field_name 1" [,"Field_name 2"…] ) |
PRIMARY KEY ( "Field_name 1" [,"Field_name 2"…] ) |
FOREIGN KEY ( "Field_name 1" [,"Field_name 2"…] )
REFERENCES "other_table_name" ( "Field_name_1" [,"Field_name 2"…])
[ON {DELETE | UPDATE}
{CASCADE | SET DEFAULT | SET NULL}] |
CHECK(<Search_condition>)
Omezení definují podmínky, které musí být při zadávání dat splněny. Omezení lze pojmenovat.
UNIQUE ("Field_name"): hodnota pole musí být jedinečná v rámci daného pole
PRIMARY KEY ("Field_name"): hodnota pole musí být jedinečná a nesmí být NULL (primární klíč)
FOREIGN KEY ("Field_name") REFERENCES <"other_table_name"> ("Field_name"): Uvedená pole této tabulky jsou propojena s poli jiné tabulky. Hodnota pole musí být testována na referenční integritu jako cizí klíč, to znamená, že pokud je zde zadána hodnota, musí existovat odpovídající primární klíč v jiné tabulce.
[ON {DELETE | UPDATE} {CASCADE | SET DEFAULT | SET NULL}]: V případě cizího klíče určuje, co se má stát, pokud je například cizí záznam odstraněn. V tabulce výpůjček pro knihovnu nemá smysl uvádět číslo uživatele, který již neexistuje. Příslušný záznam musí být upraven tak, aby vztah mezi tabulkami zůstal platný. Obvykle se záznam jednoduše odstraní. K tomu dojde, pokud vybereme možnost ON DELETE CASCADE.
CHECK(<Search_condition>): Formulováno jako podmínka WHERE, ale pouze pro aktuální záznam.
CREATE TABLE "Time_measurement" ("ID" INT PRIMARY KEY, "Start_time" TIME, "End_time" TIME, CHECK ("Start_time" <= "End_time"));
Podmínka CHECK vylučuje zadání dřívější hodnoty času ukončení než času zahájení. Při pokusu o takovýto zápis se zobrazí chybová zpráva podobná:
Zkontrolujeme porušení omezení tabulky SYS_CT_357: Time_measurement ...
Omezení pro vyhledávání je přiřazen název, který není příliš informativní. Místo toho by název mohl být definován v definici tabulky:
CREATE TABLE "Time_measurement" ("ID" INT PRIMARY KEY, "Start_time" TIME, "End_time" TIME, CONSTRAINT "Start_time<=End_time" CHECK ("Start_time" <= "End_time"));
Tím se získá poněkud jasnější chybové hlášení, protože se zobrazí název příslušného omezení.
Při vytváření relací mezi tabulkami nebo indexování konkrétních polí je třeba dodržovat omezení. Omezení se vytvářejí pomocí podmínky „CHECK“, v grafickém uživatelském rozhraní pomocí Nástroje > Relace a také v indexech vytvořených v návrhu tabulky v části Nástroje > Návrh indexu.
[ON COMMIT {DELETE | PRESERVE} ROWS]:
Pokud chceme, aby tabulka tohoto typu obsahovala data dostupná po celou relaci (od otevření databáze až po její uzavření), zvolíme možnost ON COMMIT PRESERVE ROWS.
Někdy můžeme chtít vložit další pole na určitou pozici v tabulce. Předpokládejme, že máme tabulku s názvem Addresses s poli ID, Name, Street a podobně. Uvědomujeme si, že by možná bylo rozumné rozlišovat křestní jména a příjmení.
ALTER TABLE "Addresses" ADD "FirstName" VARCHAR(25) BEFORE "Name";
ALTER TABLE "Addresses": Změní tabulku s názvem Addresses.
ADD "FirstName" VARCHAR(25): vloží pole FirstName s délkou 25 znaků.
BEFORE "Name": před polem Name.
Možnost zadat pozici dalších polí po vytvoření tabulky není v grafickém uživatelském rozhraní k dispozici.
ALTER TABLE "Table_name" ADD [COLUMN] <Field_definition> [BEFORE "already_existing_field_name"];
Dodatečné označení COLUMN není nutné v případech, kdy nejsou k dispozici žádné alternativní možnosti.
ALTER TABLE "Table_name" DROP [COLUMN] "Field_name";
Pole Field_name je vymazáno z tabulky Table_name. K tomu však nedojde, pokud je pole zapojeno do zobrazení nebo jako cizí klíč v jiné tabulce.
ALTER TABLE "Table_name" ALTER COLUMN "Field_name" RENAME TO "New_field_name"
Změní název pole.
ALTER TABLE "Table_name" ALTER COLUMN "Field_name" SET DEFAULT <Standard value>};
Nastaví konkrétní výchozí hodnotu pole. NULL odstraní existující výchozí hodnotu.
ALTER TABLE "Table_name" ALTER COLUMN "Field_name" SET [NOT] NULL
Nastaví nebo odstraní podmínku NOT NULL pro pole.
ALTER TABLE "Table_name" ALTER COLUMN <Field definition>;
Definice pole odpovídá definici z Vytvoření tabulky s následujícími omezeními:
Pole musí být již polem primárního klíče, aby bylo možné akceptovat vlastnost IDENTITY. IDENTITY znamená, že pole má vlastnost Automatická hodnota. To je možné pouze pro pole INTEGER nebo BIGINT. Popisy těchto typů polí nalezneme v dodatku k této příručce.
Pokud pole již má vlastnost IDENTITY, ale v definici pole se neopakuje, stávající vlastnost IDENTITY se odstraní.
Výchozí hodnotou se stane hodnota uvedená v definici nového pole. Pokud je definice výchozí hodnoty ponechána prázdná, jsou všechny již definované výchozí hodnoty odstraněny.
Vlastnost NOT NULL pokračuje v nové definici, pokud není definována jinak. To je rozdíl od výchozí hodnoty.
V některých případech, v závislosti na typu změny, musí být tabulka prázdná, aby mohlo dojít ke změně. Ve všech případech se změna projeví pouze tehdy, pokud je v zásadě možná (například změna z NOT NULL na NULL) a všechny stávající hodnoty lze převést (například změna z TINYINT na INTEGER).
ALTER TABLE "Table_name" ALTER COLUMN "Field_name" RESTART WITH <New_field_value>
Tento příkaz se používá výhradně pro pole IDENTITY. Určuje další hodnotu pole s nastavenou funkcí Automatická hodnota. Lze ji použít například v případě, kdy je databáze nejprve používána s testovacími daty a následně je vybavena reálnými daty. To vyžaduje odstranění obsahu tabulek a nastavení nové hodnoty pole, například "1".
ALTER TABLE "Table_name"
ADD [CONSTRAINT "Condition_name"] CHECK (<Search_condition>);
Tím se přidá podmínka vyhledávání zavedená slovem CHECK. Taková podmínka se nebude vztahovat zpětně na existující záznamy, ale bude se vztahovat na všechny následné změny a nově vložené záznamy. Pokud není název omezení definován, bude přiřazen automaticky.
Příklad:
ALTER TABLE "Loan" ADD CHECK (IFNULL("Return_Date","Loan_Date")>="Loan_Date")
Tabulka Loan musí být chráněna před vstupními chybami. Musíme například zabránit tomu, aby bylo datum vrácení uvedeno dříve, než je datum výpůjčky. Pokud se tato chyba vyskytne během procesu vracení, zobrazí se chybová zpráva Kontrola porušení omezení ....
ALTER TABLE "Table_name"
ADD [CONSTRAINT "Constraint_name"] UNIQUE ("Field_name1", "Field_name2"…);
Zde je přidána podmínka, která vynucuje, aby pojmenovaná pole měla v každém záznamu jiné hodnoty. Pokud je pojmenováno více polí, vztahuje se tato podmínka spíše na kombinaci než na jednotlivá pole. NULL se zde nepočítá. Pole tedy může mít opakovaně stejnou hodnotu, aniž by to způsobovalo problémy, pokud je jiné pole v každém ze záznamů NULL.
Tento příkaz nebude fungovat, pokud pro stejnou kombinaci polí již existuje podmínka UNIQUE.
ALTER TABLE "Table_name"
ADD [CONSTRAINT "Constraint_name"] PRIMARY KEY ("Field_name1", "Field_name2"…);
Přidá do tabulky primární klíč, případně s omezením. Syntaxe omezení je stejná jako při vytváření tabulky.
ALTER TABLE "Table_name" ADD [CONSTRAINT "Constraint_name"] FOREIGN KEY ("Field_name1", "Field_name2"…)
REFERENCES "Table_name_of_another_table" ("Field_name1_other_table", "Field_name2_other_table"…)
[ON {DELETE | UPDATE} {CASCADE | SET DEFAULT | SET NULL}];
Tím se do tabulky přidá cizí klíč (FOREIGN KEY). Syntaxe je stejná jako při vytváření tabulky.
Operace se ukončí chybovým hlášením, pokud některá hodnota v tabulce nemá odpovídající hodnotu v tabulce obsahující daný primární klíč.
Příklad: Tabulky Name a Address mají být propojeny. Tabulka Name obsahuje pole s názvem Address_ID. Hodnota tohoto pole by měla být spojena s polem ID v tabulce Address. Pokud se v poli Address_ID nachází hodnota 1, ale ne v poli ID tabulky Address, odkaz nebude fungovat. Nebude to fungovat ani v případě, že obě pole jsou různých typů.
ALTER TABLE "Table_name" DROP CONSTRAINT "Constraint_name";
Tento příkaz odstraní z tabulky pojmenované omezení (UNIQUE, CHECK, FOREIGN KEY).
ALTER TABLE "Table_name" RENAME TO "new_table_name";
Nakonec tento příkaz změní pouze název tabulky.
Poznámka
Když změníme tabulku pomocí jazyka SQL, změna se projeví v databázi, ale nemusí být nutně viditelná nebo účinná v grafickém uživatelském rozhraní. Po zavření a opětovném otevření databáze se změny zobrazí i v grafickém uživatelském rozhraní.
Změny se také zobrazí, pokud v kontejneru tabulky zvolíme Zobrazení > Obnovit tabulky.
DROP TABLE "Table name" [IF EXISTS] [RESTRICT | CASCADE];
Odstraní tabulku Table name.
IF EXISTS zabrání chybě, pokud tato tabulka neexistuje.
RESTRICT je výchozí uspořádání a nemusí být explicitně zvoleno; znamená, že k vymazání nedojde, pokud je tabulka propojena s jinou tabulkou pomocí cizího klíče nebo je aktivní zobrazení této tabulky. Dotazy nejsou ovlivněny, protože nejsou uloženy v HSQLDB.
Pokud místo toho zvolíme CASCADE, budou odstraněny všechny odkazy na tabulku Table_name. V propojených tabulkách jsou všechny cizí klíče nastaveny na NULL. Všechny pohledy odkazující na pojmenovanou tabulku jsou také zcela odstraněny.
V zásadě můžeme mít databázi bez odkazů mezi tabulkami. Uživatel pak musí při zadávání dat zajistit, aby vztahy mezi tabulkami zůstaly správné. K tomu obvykle slouží vhodné vstupní formuláře, které to umožňují.
Odstranění záznamů v propojených tabulkách není jednoduchá záležitost. Předpokládejme, že chceme odstranit konkrétní ulici z tabulky Street na obrázku 6, kde je toto pole propojeno s tabulkou Address jako cizí klíč v této tabulce. Odkazy v tabulce Address by zmizely. Databáze to po vytvoření vztahu neumožňuje. Aby bylo možné ulici odstranit, musí být splněna podmínka, že na ni již není odkazováno v tabulce Address.
Základní vazby se vytvářejí pomocí Nástroje > Relace. Tím se vytvoří spojovací linie z primárního klíče v jedné tabulce na definovaný cizí klíč v druhé tabulce.
Při vytváření takového odkazu se může zobrazit následující chybová zpráva:
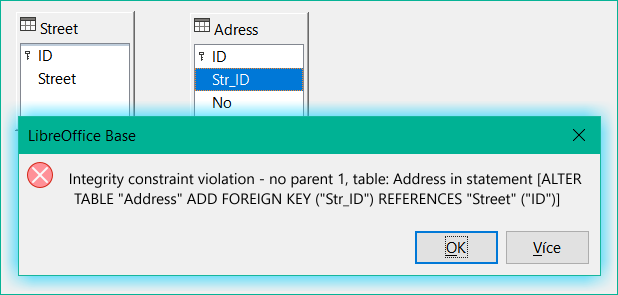
Obrázek 27: Typy sloupců se při vytváření relace neshodují
Tato zpráva zobrazuje chybu, ke které došlo, a interní příkaz SQL, který chybu způsobil.
Typy sloupců se v příkazu neshodují—Při zobrazení příkazu SQL je zřejmý odkaz na sloupce Address.str_ID a Street.ID. Pro účely testu bylo jedno z těchto polí definováno jako Integer, druhé jako Tiny Integer. Proto nelze vytvořit žádné propojení, protože jedno pole nemůže mít stejnou hodnotu jako druhé.
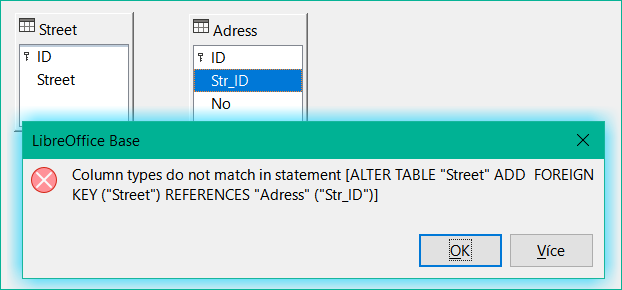
Obrázek 28: Porušení omezení integrity při vytváření vztahu
V tomto případě se typy sloupců shodují. Příkaz SQL je stejný jako v prvním příkladu. Opět je zde však chyba:
Porušení omezení integrity – žádný rodič 1, tabulka: Address... —Nelze stanovit integritu relace. V poli str_ID tabulky Address je číslo 1, které se v poli ID tabulky Street nevyskytuje. Nadřazenou tabulkou je zde Street, protože musí existovat její primární klíč. Tato chyba je velmi častá, pokud mají být propojeny dvě tabulky a některá pole v tabulce s předpokládaným cizím klíčem již obsahují data. Pokud pole cizího klíče obsahuje položku, která se nenachází v rodičovské tabulce (tabulka obsahující primární klíč), jedná se o neplatnou položku.
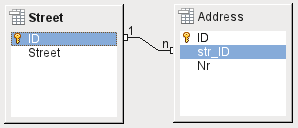
Obrázek 29: Relace úspěšně vytvořena
Pokud je propojení provedeno úspěšně a následně dojde k pokusu o zadání podobně neplatného záznamu do tabulky, zobrazí se následující chybové hlášení:
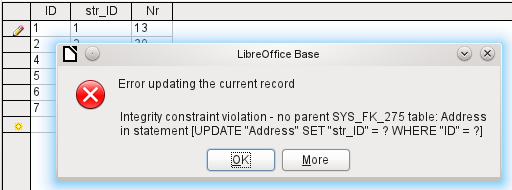
Obrázek 30: Porušení integritního omezení při zadávání dat
Opět se jedná o porušení integrity. Program Base odmítá přijmout hodnotu 1 pro pole str_ID po vytvoření odkazu, protože tabulka Street takovou hodnotu v poli ID neobsahuje.
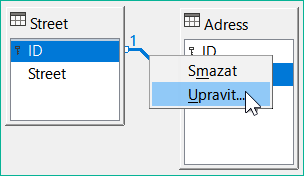
Obrázek 31: Úprava odkazů klepnutím pravým tlačítkem myši
Vlastnosti odkazu lze upravit tak, aby se při odstranění záznamu z tabulky Street současně nastavila hodnota NULL u odpovídajících záznamů v tabulce Address.
Vlastnosti zobrazené na obrázku 31 se vždy vztahují k akci spojené se změnou záznamu z tabulky obsahující příslušný primární klíč. V našem případě je to tabulka Street. Pokud je primární klíč záznamu v této tabulce změněn (Update), může dojít k následujícím akcím.
Žádná akce
Kaskádová aktualizace
Nastavit null
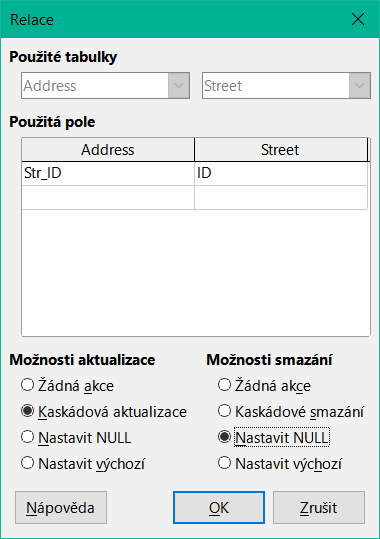
Obrázek 32: Úprava vlastností relace
Nastavení výchozí hodnoty
ALTER TABLE "Address" ALTER COLUMN "Street_ID" SET DEFAULT 1;
Upozornění
Pokud by výchozí hodnota v poli cizího klíče nebyla propojena s hodnotou primárního klíče cizí tabulky, vytvořil by se odkaz na hodnotu, která není možná. Referenční integrita databáze by byla zničena.
Lepší by bylo využít možnosti nastavit výchozí hodnotu.
Pokud je záznam odstraněn z tabulky Street, jsou k dispozici následující možnosti.
Žádná akce
Kaskádové mazání
Nastavení na hodnotu Null
Tip
Ve většině případů je třeba se vyhnout možnosti Žádná akce, aby se uživateli nezobrazovala chybová hlášení z databáze, protože ta nemusí být pro uživatele vždy srozumitelná.
V nabídce Nástroje > Relace se přetažením myší vytvoří cizí klíče, které odkazují na jedno pole v jiné tabulce. Chceme-li vytvořit odkaz na tabulku, která má složený primární klíč, přejdeme na Nástroje > Relace a poté na Vložit > Nová relace, nebo použijeme příslušné tlačítko. Zobrazí se dialogové okno pro úpravu vlastností vztahu s volným výběrem dostupných tabulek.
Databáze, které se skládají pouze z jedné tabulky, obvykle nevyžadují vstupní formulář, pokud neobsahují pole pro obrázky. Jakmile však tabulka obsahuje cizí klíče z jiných tabulek, musí si uživatelé buď pamatovat, která čísla klíčů mají zadat, nebo musí mít možnost podívat se současně do jiných tabulek. V takových případech je užitečný formulář.
Tabulky v kontejneru tabulek se otevírají poklepáním. Pokud je primárním klíčem automaticky inkrementující pole, bude jedno z viditelných polí obsahovat text Automatická hodnota. Do pole Automatická hodnota není možné zadávat žádné údaje. Jeho přiřazenou hodnotu lze v případě potřeby změnit, ale až poté, co byl záznam uložen.
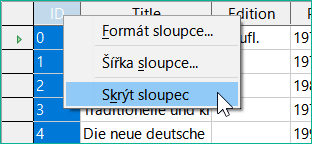
Obrázek 33: Zadání položky do tabulek – skrytí sloupců
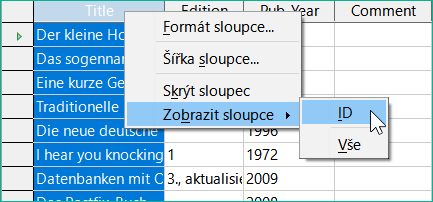
Obrázek 34: Zadání položky do tabulek – zrušení skrývání sloupců
Jednotlivé sloupce v zobrazení tabulky dat lze skrýt. Pokud například pole primárního klíče nemusí být viditelné, lze to zadat v tabulce v zobrazení pro zadávání dat klepnutím pravým tlačítkem myši na záhlaví sloupce. Toto nastavení je uloženo v grafickém uživatelském rozhraní. Sloupec v tabulce nadále existuje a lze jej vždy znovu zviditelnit.
Do tabulky se obvykle zapisuje zleva doprava pomocí klávesnice s klávesami Tab nebo Enter. Můžeme také použít myš.
Po dosažení posledního pole záznamu kurzor automaticky přejde na další záznam. Předchozí záznam se uloží do úložiště. Další ukládání pomocí Soubor > Uložit není nutné a ani možné. Data jsou již v databázi.
Upozornění
V případě HSQLDB jsou data v pracovní paměti. Na pevný disk se přenese až po zavření aplikace Base. To není z hlediska bezpečnosti dat vždy žádoucí, protože pokud se aplikace Base z nějakého důvodu neuzavře spořádaným způsobem, může to vést ke ztrátě dat.
Pokud nejsou zadána žádná data do pole, které bylo při návrhu tabulky definováno jako povinné (NOT NULL), zobrazí se příslušné chybové hlášení:
Pokus o vložení prázdné hodnoty do povinného sloupce...
Zobrazí se také příslušný sloupec, tabulka a příkaz SQL (přeložený grafickým uživatelským rozhraním).
Změna záznamu je snadná: vyhledáme pole, zadáme jinou hodnotu a řádek opět opustíme.
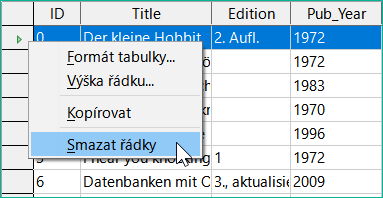
Obrázek 35: Odstranění řádku(ů) tabulky
Chceme-li odstranit záznam, vybereme řádek klepnutím na jeho záhlaví (šedá oblast vlevo), klepneme pravým tlačítkem myši a zvolíme Smazat řádky.
Existuje poměrně dobře skrytá metoda pro kopírování celých řádků. Aby to fungovalo, musí být primární klíč tabulky definován jako Automatická hodnota.
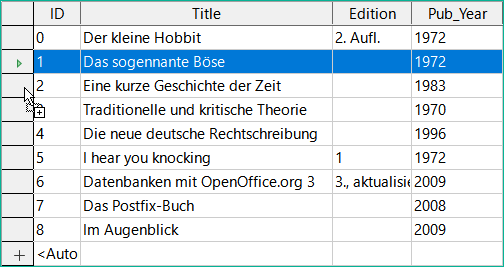
Obrázek 36: Kopírování řádku tabulky
Nejprve se klepne levým tlačítkem myši na záhlaví řádku. Poté podržíme stisknuté tlačítko a přetáhneme myš. Kurzor se změní na symbol se znaménkem +. To znamená, že záznam je zkopírován do poslední položky tabulky.
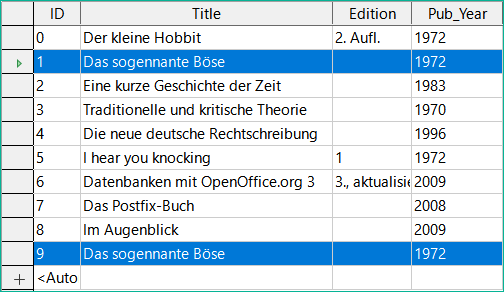
Obrázek 37: Řádek s ID 1 zkopírován na konec tabulky jako ID 9
Záznam s primárním klíčem 1 se vloží jako nový záznam s novým primárním klíčem 9.
Pokud je pomocí klávesy Control nebo Shift označena skupina záznamů, budou tyto záznamy zkopírovány jako skupina.
Tip
Záhlaví sloupců lze přetáhnout na šířku vhodnou pro zadávání. Pokud se to provede v tabulce, program Base automaticky uloží novou šířku sloupce do tabulky.
Šířka sloupců v tabulkách ovlivňuje šířku sloupců v dotazech. Pokud jsou sloupce v dotazu příliš úzké, bude mít jejich rozšíření pouze dočasný účinek. Nová šířka se neuloží. Je lepší sloupec v tabulce rozšířit, aby se v dotazech zobrazoval správně a nebylo nutné měnit jeho velikost.
Funkce Třídit, Hledat a Filtrovat jsou velmi užitečné pro vyhledávání konkrétních záznamů.
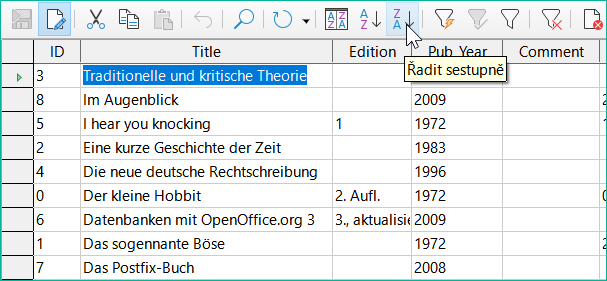
Obrázek 38: Rychlé třídění
Tlačítka A > Z a Z > A umožňují rychlé řazení. Nejprve vybereme pole. Poté klepneme na tlačítko odpovídající vzestupnému nebo sestupnému řazení a data se seřadí podle daného sloupce. Obrázek 38 zobrazuje sestupné řazení podle pole Title.
Rychlé třídění seřadí pouze podle jednoho sloupce. Chceme-li řadit podle více sloupců současně, nalevo od tlačítek rychlého řazení je k dispozici pokročilejší funkce řazení:
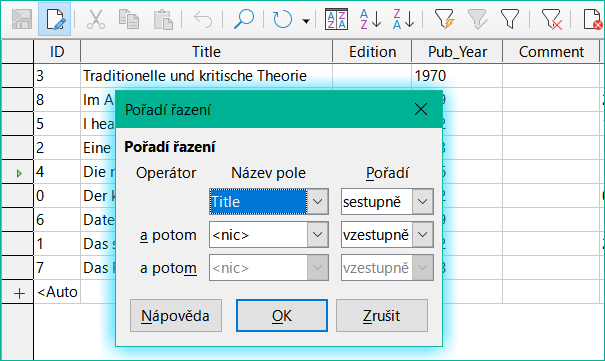
Obrázek 39: Řazení podle více než jednoho sloupce
Vybere se název pole sloupce a aktuální pořadí řazení. Pokud bylo provedeno předchozí rychlé třídění, první řádek již bude obsahovat odpovídající název pole a pořadí třídění.
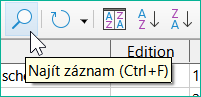
Obrázek 40: Ikona Najít záznam na nástrojové liště Tabulka dat
Tlačítko Najít záznam je jednoduchá metoda pro vyhledávání záznamů ve velké tabulce. Funkce vyhledávání je však u rozsáhlých databází velmi pomalá, protože vyhledávání nepoužívá příkaz SQL v rámci databáze. Pro rychlejší vyhledávání použijeme místo funkce Najít záznam dotaz. Pro eliminaci častých úprav dotazu lze navrhnout jeho spouštění pomocí parametrů. Viz kapitola 5, Dotazy, část „Použití parametrů v dotazech“.
Tip
Před vyhledáváním se ujistíme, že sloupce, ve kterých budeme hledat, jsou dostatečně široké, aby správně zobrazovaly nalezené záznamy. Okno vyhledávání zůstane v popředí a nebude možné opravit nastavení šířky sloupců v základní tabulce. Chceme-li se dostat ke stolu, musíme hledání přerušit.
Tlačítko Najít záznam automaticky vyplní hledaný výraz obsahem pole, ze kterého bylo vyvoláno.
Aby bylo hledání účinné, měla by být oblast hledání co nejvíce omezena. Bylo by zbytečné vyhledávat výše uvedený text z pole Ttile v poli Author. Namísto toho je jméno pole Title již navrženo pro Název pole.
Další nastavení vyhledávání může usnadnit práci prostřednictvím specifických kombinací. Můžeme použít běžné zástupné znaky SQL ("_" pro proměnný znak, "%" pro libovolný počet proměnných znaků nebo "\" jako escape znak, který umožňuje vyhledávání těchto speciálních znaků).
Regulární výrazy jsou podrobně popsány v nápovědě LibreOffice.
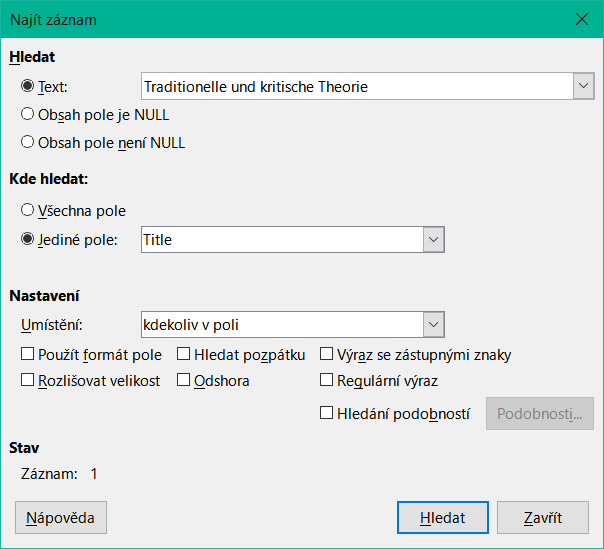
Obrázek 41: Vstupní maska pro vyhledávání záznamů
Funkce vyhledávání podobností je užitečná, pokud potřebujeme vyloučit pravopisné chyby. Čím vyšší hodnoty nastavíme, tím více záznamů se v konečném seznamu zobrazí.
Tento vyhledávací modul je nejvhodnější pro lidi, kteří z pravidelného používání přesně vědí, jak dosáhnout daného výsledku. Většina uživatelů má větší šanci na úspěšné nalezení záznamů pomocí filtru.
Kapitola 4 této knihy popisuje použití formulářů pro vyhledávání a způsob, jakým lze pomocí jazyka SQL a maker dosáhnout vyhledávání podle klíčových slov.
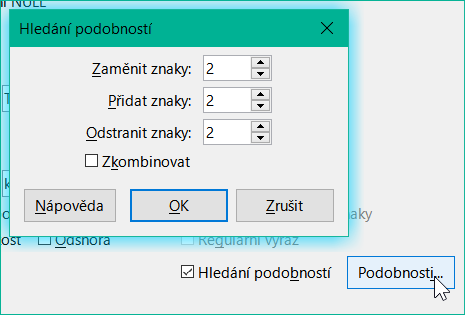
Obrázek 42: Omezení hledání podobnosti
Obrázek 43: Ikona AutoFilter na nástrojové liště Tabulka dat
Tabulku můžeme rychle filtrovat pomocí Automatického filtru. Umístíme kurzor do buňky pole a jedním klepnutím na ikonu filtr převezme obsah tohoto pole. Zobrazí se pouze ty záznamy, u nichž má vybrané pole stejný obsah jako vybraná buňka. Obrázek níže ukazuje filtrování podle položky ve sloupci Pub_Year.
Obrázek 44: Ikona Obnovit filtr/uspořádání na nástrojové liště Tabulka dat
Filtr je aktivní, což je znázorněno ikonou filtru se zeleným zaškrtnutím. Symbol filtru je zobrazen stisknutý. Toto tlačítko je přepínací, takže pokud na něj klepneme znovu, filtr bude existovat i nadále, ale nyní se zobrazí všechny záznamy. Pokud chceme, můžeme na něj kdykoli klepnout a vrátit se do filtrovaného stavu.
Klepnutím na ikonu Odstranit filtr/řazení vpravo dole se odstraní všechny existující filtry a řazení. Filtry se stanou neaktivními a nelze již obnovit jejich staré hodnoty.
Tip
Do filtrované tabulky nebo do tabulky, která byla omezena vyhledáváním, můžeme stále zadávat záznamy normálně. V zobrazení tabulky zůstávají viditelné, dokud není tabulka aktualizována klepnutím na tlačítko Obnovit.
Obrázek 45: Ikona Standardní filtr na nástrojové liště Tabulka dat
Ikona Standardní filtr otevře dialogové okno, ve kterém můžeme filtrovat pomocí několika kritérií současně, podobně jako při třídění. Pokud se používá Automatický filtr, zobrazí se toto existující kritérium filtru již na prvním řádku standardního filtru.
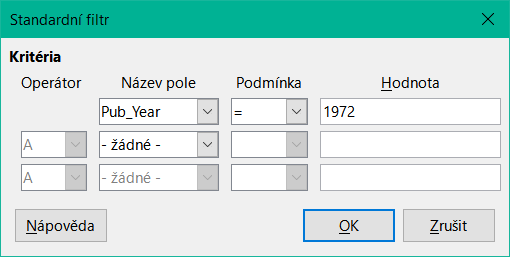
Obrázek 46: Filtrování vícenásobných dat pomocí standardního filtru
Standardní filtr poskytuje mnoho funkcí filtrování dat SQL. K dispozici jsou následující příkazy SQL.
Tabulka 1: Podmínky dostupné pro standardní filtry
|
Grafické zobrazení podmínky |
Popis |
|
= |
Přesná rovnost; odpovídá like, ale bez dalších zástupných znaků. |
|
<> |
Není rovno |
|
< |
Méně než |
|
<= |
Menší než nebo rovno |
|
> |
Větší než |
|
>= |
Větší než nebo rovno |
|
like |
Pro text psaný v uvozovkách (' '); "_" pro proměnný znak, "%" pro libovolný počet proměnných znaků. |
|
not like |
Opak like, v SQL NOT LIKE. |
|
prázdný |
Žádné zadání, dokonce ani znak mezery. V jazyce SQL je toto vyjádřeno termínem NULL. |
|
Není prázdný |
Opak prázdného, v SQL NOT NULL |
Před kombinací jednoho kritéria filtru s jiným musí být na následujícím řádku vybrán alespoň jeden název pole. Na obrázku 46 je místo názvu pole zobrazeno slovo – none – (- žádné -, pozn. překl.), takže kombinace není aktivní. K dispozici jsou kombinační operátory AND a OR.
Název pole může být nový nebo dříve vybraný název pole.
I v případě velkých souborů dat lze počet vyhledaných záznamů snížit na zvládnutelnou množinu pomocí vhodného filtrování s využitím těchto tří možných podmínek.
Také v případě filtrování formulářů existují některé další možnosti (popsané v kapitole 4), které grafické uživatelské rozhraní neposkytuje.
Přímé zadávání dat pomocí jazyka SQL je užitečné pro zadávání, změnu nebo odstranění více záznamů jedním příkazem.
INSERT INTO "Table_name" [( "Field_name" [,…] )]
{ VALUES("Field value" [,…]) | <Select-Formula>};
Pokud není zadáno pole Field_name, musí být všechna pole vyplněna a ve správném pořadí (jak je uvedeno v tabulce). To zahrnuje i automaticky inkrementované pole primárního klíče, pokud je k dispozici. Zadané hodnoty mohou být také výsledkem dotazu (<Select-Formula>). Přesnější informace jsou uvedeny níže.
INSERT INTO "Table_name" ("Field_name") VALUES ('Test');
CALL IDENTITY();
V tabulce se do sloupce Field_name vloží hodnota Test. Automaticky inkrementované pole primárního klíče ID není dotčeno. Příslušnou hodnotu ID je třeba vytvořit samostatně pomocí CALL IDENTITY(). To je důležité při použití maker, aby bylo možné hodnotu tohoto klíčového pole použít později.
INSERT INTO "Table_name" ("Field_name") SELECT "Other_fieldname" FROM "Name_of_other_table";
V první tabulce se do pole Field_name vloží tolik nových záznamů, kolik jich je ve sloupci Other_fieldname v druhé tabulce. Zde lze samozřejmě použít vzorec Select-Formula k omezení počtu záznamů.
UPDATE "Table_name" SET "Field_name" = <Expression> [, ...] [WHERE <Expression>];
Při úpravě mnoha záznamů najednou je velmi důležité pečlivě zkontrolovat zadávaný příkaz SQL. Předpokládejme, že všichni žáci ve třídě budou posunuti o jeden ročník výše:
UPDATE "Table_name" SET "Year" = "Year"+1
Nic nemůže být rychlejší: Všechny datové záznamy se změní jediným příkazem. Představme si však, že nyní musíme určit, kterých studentů se tato změna neměla týkat. Bylo by jednodušší zaškrtnout pole Yes/No pro opakování ročníku a poté přesunout nahoru pouze ty studenty, u kterých toto pole nebylo zaškrtnuto:
UPDATE "Table_name" SET "Year" = "Year"+1 WHERE "Repetition" = FALSE
Tyto podmínky fungují pouze v případě, že dané pole může nabývat pouze hodnot FALSE a TRUE; nesmí být NULL. Bylo by bezpečnější, kdyby byla podmínka formulována jako WHERE "Repetition". <> TRUE.
Pokud chceme následně do určitého pole, které je prázdné, zadat výchozí hodnotu, můžeme to provést pomocí příkazu:
UPDATE "Table" SET "Field" = 1 WHERE "Field" IS NULL
Přímým přiřazením hodnot můžeme změnit několik polí najednou. Předpokládejme, že tabulka knih obsahuje jména jejich autorů. Zjistilo se, že Erich Kästner byl často zapsán jako Eric Käschtner.
UPDATE "Books" SET "Author_first_name" = 'Erich', "Author_surname" = 'Kästner' WHERE "Author_first_name" = 'Eric' AND "Author_surname" = 'Käschtner'
Pomocí funkce Update je možné provést i další kroky výpočtu. Pokud má být například zboží s cenou vyšší než 150,00 USD zahrnuto do speciální nabídky a cena snížena o 10 %, lze to provést takto:
UPDATE "Table_name" SET "Price" = "Price"*0.9 WHERE "Price" >= 150
Pokud zvolíme datový typ CHAR, pole má pevnou šířku. V případě potřeby je text doplněn nulovými znaky. Pokud jej převedeme na VARCHAR, tyto nulové znaky zůstanou zachovány. Chceme-li je odstranit, použijeme funkci oříznutí prázdných znaků zprava:
UPDATE "Table_name" SET "Field_name" = RTRIM("Field_name")
DELETE FROM "Table_name" [WHERE <Expression>];
Bez podmíněného výrazu je příkaz
DELETE FROM "Table_name"
odstraní celý obsah tabulky.
Z tohoto důvodu je vhodnější, aby byl příkaz konkrétnější. Pokud je například zadána hodnota primárního klíče, bude smazán pouze tento přesný záznam.
DELETE FROM "Table_name" WHERE "ID" = 5;
Pokud má být v případě výpůjčky záznam o médiu při vrácení položky vymazán, lze to provést pomocí příkazu
DELETE FROM "Table_name" WHERE NOT "Return_date" IS NULL;
nebo alternativně pomocí
DELETE FROM "Table_name" WHERE "Return_date" IS NOT NULL;
Někdy jsou v jiném programu kompletní datové sady, které je třeba importovat do programu Base prostřednictvím schránky. To může zahrnovat vytvoření nové tabulky nebo přidání záznamů do stávající tabulky.
Poznámka
Chceme-li importovat data pomocí schránky, musí být formát dat čitelný v aplikaci Base. To platí vždy pro datové soubory otevřené v LibreOffice.
Pokud se například mají do souboru *.odb načíst tabulky z externí databáze, musí být tato databáze nejprve otevřena v LibreOffice nebo zaregistrována v LibreOffice jako zdroj dat. Viz „Přístup k externím databázím“ v kapitole 2, Vytvoření databáze.
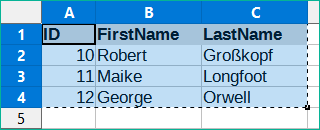
Obrázek 47: Data ke zkopírování do tabulky
Nahoře je malá ukázková tabulka zkopírovaná z tabulkového procesoru Calc do schránky. Poté se vloží v aplikaci Base do kontejneru Table. Samozřejmě to šlo udělat i tak, že jsme ji vybrali levým tlačítkem myši a pak ji přetáhli na druhou stranu.
Obrázek 48: Vložení dat do požadované tabulky
V kontejneru Table klepneme pravým tlačítkem myši a otevřeme místní nabídku pro tabulku, do které mají být záznamy přidány.
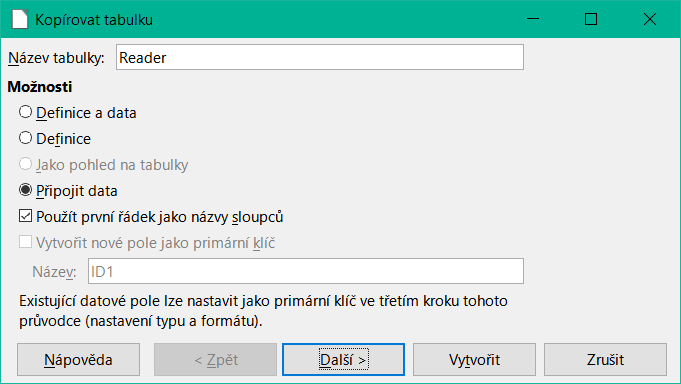
Obrázek 49: Dialogové okno Kopírovat tabulku – přidávání dat
Název tabulky se zobrazí v průvodci importem. Současně je vybrána volba Připojit data. Použít první řádek jako názvy sloupců může, ale nemusí být vyžadován v závislosti na verzi LibreOffice. Pokud mají být záznamy připojeny, není definice dat vyžadována. K dispozici musí být také primární klíč.
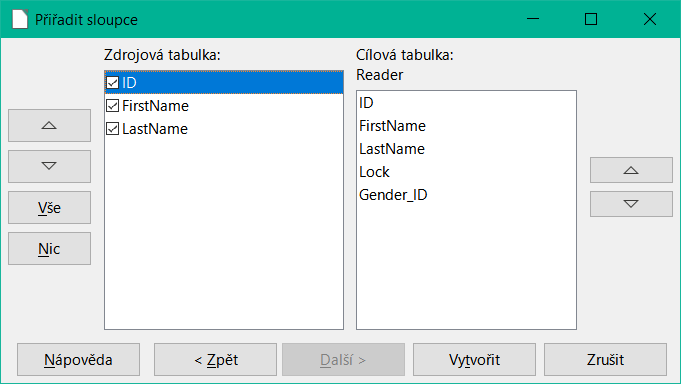
Obrázek 50: Přiřadit dat sloupců – doplnění dat
Sloupce zdrojové tabulky aplikace Calc a cílové tabulky v aplikaci Base se nemusí shodovat v pořadí, názvech ani celkovém počtu. Přenesou se pouze prvky vybrané z levé strany. Shodu mezi zdrojovou a cílovou tabulkou je třeba upravit pomocí tlačítek se šipkami na obou stranách.
Tím je import dokončen.
Import může vést k problémům, pokud:
Pole v cílové tabulce vyžadují povinný záznam, ale zdrojová tabulka pro ně neposkytuje žádné údaje.
Definice polí v cílové tabulce neodpovídají definicím ve zdrojové tabulce (například do číselného pole má být zadáno jméno nebo cílové pole má příliš málo znaků pro data).
Zdrojová tabulka poskytuje data nekonzistentní s daty cílové tabulky, například nejednotné hodnoty primárních klíčů nebo jiných polí definovaných jako jedinečné.
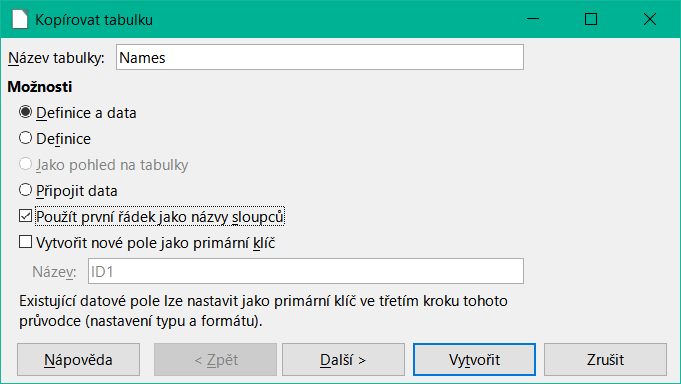
Po spuštění Průvodce importem se automaticky zobrazí dříve vybraný název tabulky. Pokud vytváříme novou tabulku, je nutné tento název tabulky změnit, protože je zakázáno mít tabulku se stejným názvem jako již existující. Název této tabulky je Names. Definice a data mají být přeneseny. První řádek se použije jako záhlaví sloupců.
V tomto okamžiku můžeme vytvořit nové, další pole pro primární klíč. Název tohoto pole nesmí existovat jako záhlaví sloupce v tabulce aplikace Calc. V opačném případě se zobrazí chybová zpráva:
Tato zpráva však situaci nevysvětluje zcela správně.
Pokud chceme, aby jako primární klíč sloužilo existující pole, nevybereme možnost Vytvořit primární klíč. V tomto případě vytvoříme pole primárního klíče na třetí stránce dialogového okna Průvodce.
Při importu se přenese definice tabulky a data.
Obrázek 51: Dialog Kopírovat tabulku – vytvoření nové tabulky
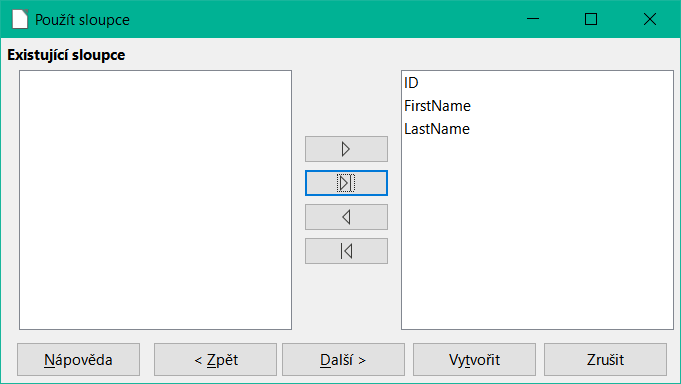
Přenesou se všechny dostupné sloupce.
Obrázek 52: Dialogové okno Použít sloupce
Formátování typů tabulek často vyžaduje úpravu. Obvykle jsou pole předdefinována jako textová pole s velmi velkou velikostí. Číselná pole a pole s daty by proto měla být resetována pomocí Typ formátování > Informace o sloupci > Typ pole. V případě desetinných čísel je třeba zkontrolovat počet desetinných míst.
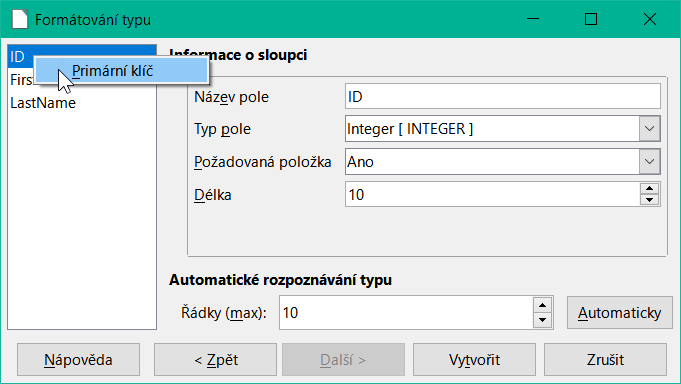
Obrázek 53: Dialogové okno Formátování typu – nastavení primárního klíče
Možnost výběru primárního klíče je poněkud nejasně přítomna v místní nabídce pole, které jej má obsahovat. V tomto příkladu bylo pole ID naformátováno způsobem, který umožňuje jeho použití jako primárního klíče. Pokud nebyl primární klíč vytvořen jako další pole v okně Kopírovat tabulku v průvodci, je třeba jej nyní explicitně nastavit pomocí místní nabídky názvu pole.
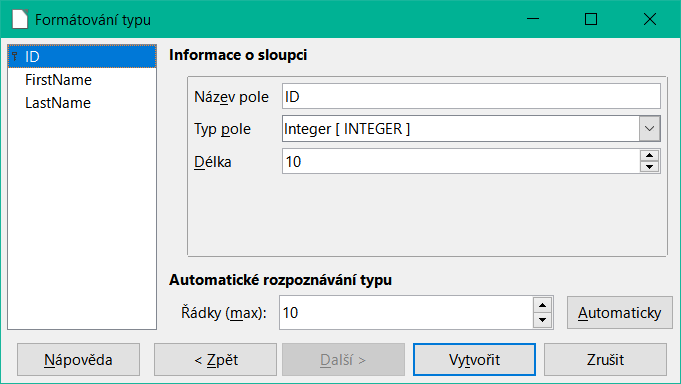
Obrázek 54: Dialogové okno Formátování typu – ID nastaveno jako primární klíč
Po klepnutí na tlačítko Vytvořit se vytvoří tabulka a vyplní se zkopírovanými daty.
Nový primární klíč není klíčem Automatické hodnoty. Chceme-li takovou tabulku vytvořit, musíme ji otevřít pro úpravy. Poté můžeme provádět další operace formátování.
Někdy nejsou zdrojová data k dispozici v požadované podobě. Například adresy se do tabulek často zadávají jako jediné pole, včetně města a poštovního směrovacího čísla. Při importu těchto prvků je možná budeme chtít umístit do samostatné tabulky, kterou lze následně propojit s hlavní tabulkou.
Následující způsob je možný pro přímé vytvoření této relace:
Kompletní tabulka se všemi informacemi o adresách je importována do databáze aplikace Base jako tabulka s názvem Addresses. Podrobnosti nalezneme v předchozích kapitolách.
Pole Postcode a Town jsou načtena dotazem, zkopírována a uložena jako samostatná tabulka Postcode_Town. Za tímto účelem se přidá pole ID a zadá se jako primární klíč s funkcí Automatická hodnota.
Zde je dotaz:
SELECT DISTINCT "Postcode", "Town" FROM "Addresses"
Do tabulky Addresses je přidáno nové pole s názvem Postcode_ID.
Pomocí Nástroje > SQL se provede aktualizace této tabulky:
UPDATE "Addresses" AS "a" SET "a"."Postcode_ID" = (SELECT "ID" FROM "Postcode_Town" WHERE "Postcode"||"Town" = "a"."Postcode"||"a"."Town")
Otevře se tabulka Addresses k úpravám a odstraní se pole Postcode a Town. Tato změna se uloží a tabulka se opět zavře.
Tím se tabulky oddělí, aby bylo možné vytvořit relaci 1:n mezi tabulkou Postcode_Town a tabulkou Addresses. Tento vztah je definován pomocí Nástroje > Relace.
Podrobnosti o kódu SQL nalezneme také v kapitole 5, Dotazy.
Zadání pouze pomocí tabulky nebere v úvahu odkazy na jiné tabulky. To je zřejmé z příkladu půjčovny médií.
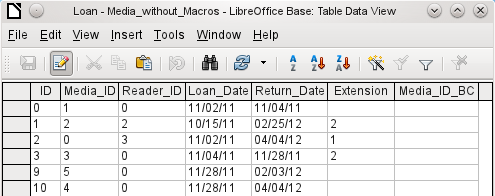
Obrázek 55: Část tabulky Loan
Tabulka Loan se skládá z cizích klíčů pro vypůjčovanou položku (Media_ID) a odpovídajícího čtenáře (Reader_ID) a z data výpůjčky (Loan_Date). Do tabulky proto musíme v okamžiku výpůjčky zadat dvě číselné hodnoty (číslo média a číslo čtenáře) a datum. Primární klíč je automaticky zadán do pole ID. Zda čtenář skutečně odpovídá číslu, není zřejmé, pokud není současně otevřena druhá tabulka pro čtenáře. Není také zřejmé, zda byl předmět zapůjčen se správným číslem. Zde se musí výpůjčka spolehnout na štítek na položce nebo na jinou otevřenou tabulku.
Toho všeho lze mnohem snadněji dosáhnout pomocí formulářů. Zde lze uživatele a média vyhledat pomocí ovládacích prvků seznamu. Ve formulářích jsou názvy uživatele a položky viditelné a jejich číselné identifikátory jsou skryté. Kromě toho může být formulář navržen tak, že se nejprve vybere uživatel, pak datum výpůjčky a každé sadě médií se přiřadí toto jedno datum podle čísla. Jinde lze tato čísla zviditelnit přesně odpovídajícími popisy médií.
Přímý vstup do tabulek je užitečný pouze pro databáze s jednoduchými tabulkami. Jakmile existují vztahy mezi tabulkami, je lepší použít speciálně navržený formulář. Ve formulářích lze tyto vztahy lépe řešit pomocí podformulářů nebo seznamových polí.