
Příručka aplikace Base 7.3
Kapitola 5
Dotazy
Tento dokument je chráněn autorskými právy © 2022 týmem pro dokumentaci LibreOffice. Přispěvatelé jsou uvedeni níže. Dokument lze šířit nebo upravovat za podmínek licence GNU General Public License (https://www.gnu.org/licenses/gpl.html), verze 3 nebo novější, nebo the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0/), verze 4.0 nebo novější.
Všechny ochranné známky uvedené v této příručce patří jejich vlastníkům.
|
Pulkit Krishna |
Dan Lewis |
Steve Fanning |
|
Vikram Ghangurde |
flywire |
|
|
Robert Großkopf |
Pulkit Krishna |
Jost Lange |
|
Dan Lewis |
Hazel Russman |
Jochen Schiffers |
|
Steve Schwettman |
Jean Hollis Weber |
|
Jakékoli připomínky nebo návrhy k tomuto dokumentu prosím směřujte do fóra dokumentačního týmu na adrese https://community.documentfoundation.org/c/documentation/loguides/ (registrace je nutná) nebo pošlete e-mail na adresu: loguides@community.documentfoundation.org.
Poznámka
Vše, co napíšete do fóra, včetně vaší e-mailové adresy a dalších osobních údajů, které jsou ve zprávě napsány, je veřejně archivováno a nemůže být smazáno. E-maily zaslané do fóra jsou moderovány.
Vydáno Srpen 2022. Založeno na LibreOffice 7.3 Community.
Jiné verze LibreOffice se mohou lišit vzhledem a funkčností.
Některé klávesové zkratky a položky nabídek jsou v systému macOS jiné než v systémech Windows a Linux. V následující tabulce jsou uvedeny nejdůležitější rozdíly, které se týkají informací v této knize. Podrobnější seznam se nachází v nápovědě aplikace.
|
Windows nebo Linux |
Ekvivalent pro macOS |
Akce |
|
Výběr v nabídce Nástroje > Možnosti |
LibreOffice > Předvolby |
Otevřou se možnosti nastavení. |
|
Klepnutí pravým tlačítkem |
Control + klepnutí a/nebo klepnutí pravým tlačítkem myši v závislosti na nastavení počítače |
Otevře se místní nabídka. |
|
Ctrl (Control) |
⌘ (Command) |
Používá se také s dalšími klávesami. |
|
Alt |
⌥ (Option) |
Používá se také s dalšími klávesami. |
|
Ctrl+Q |
⌘ + Q |
Ukončí LibreOffice |
Dotazy do databáze jsou nejmocnějším nástrojem, který máme k dispozici pro praktické využití databází. Mohou spojit data z různých tabulek, v případě potřeby vypočítat výsledky a rychle vyfiltrovat konkrétní záznam z velkého množství dat. Rozsáhlé internetové databáze, které lidé denně využívají, existují především proto, aby na základě promyšleného výběru klíčových slov poskytly uživateli rychlý a praktický výsledek z obrovského množství informací – včetně reklamy související s vyhledáváním, která lidi vybízí k nákupu.
Base používá jazyk SQL (Structured Query Language), vyslovovaný jako "sequel", který je v podporovaných databázích podobný. Dotazy lze zadávat jak v grafickém uživatelském rozhraní, tak přímo jako kód SQL. V obou případech se otevře okno, ve kterém můžeme dotaz vytvořit a v případě potřeby také opravit.
Vytváření dotazů pomocí Průvodce je stručně popsáno v kapitole 8 příručky Začínáme s LibreOffice, Začínáme s aplikací Base. Zde vysvětlíme přímé vytváření dotazů v Režimu návrhu.
V této kapitole budeme nadále používat ukázkovou databázi Media_without_Macros.odb. V hlavním okně databáze klepneme v části Databáze na ikonu Dotazy a poté v části Úlohy klepneme na Vytvořit dotaz v zobrazení návrhu. Zobrazí se dvě dialogová okna. Jedno z nich poskytuje základ pro vytvoření návrhu pohledu na dotaz; druhý slouží k přidání tabulek, pohledů nebo dotazů k aktuálnímu dotazu.
Protože náš jednoduchý formulář odkazuje na tabulku Loan, vysvětlíme si nejprve vytvoření dotazu pomocí této tabulky.
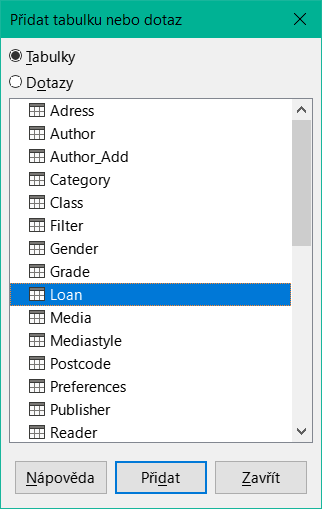
Obrázek 1: Dialogové okno Přidat tabulku nebo dotaz
Z dostupných tabulek vybereme tabulku Úvěr. Toto okno umožňuje kombinovat více tabulek (a také pohledů a dotazů). Chceme-li vybrat tabulku, klepneme na její název a poté na tlačítko Přidat. Nebo dvakrát klepneme na název tabulky. Obě metody přidají tabulku do grafické oblasti dialogového okna Návrh dotazu (obrázek 2).
Po výběru všech potřebných tabulek klepneme na tlačítko Zavřít. V případě potřeby lze později přidat další tabulky a dotazy. Žádný dotaz však nelze vytvořit bez alespoň jedné tabulky, proto je třeba provést výběr na začátku.
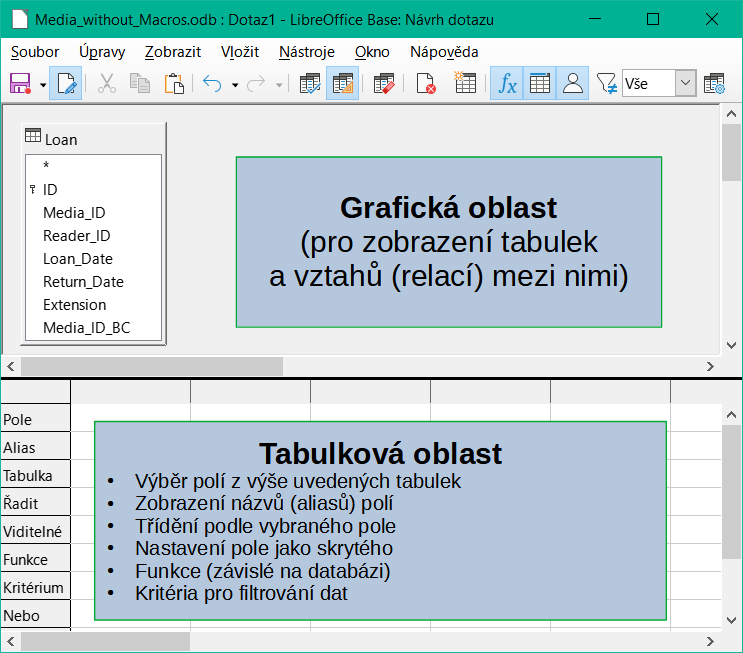
Obrázek 2: Oblasti okna návrhu dotazu
Obrázek 2 zobrazuje základní rozdělení dialogového okna Návrh dotazu: v grafické oblasti jsou zobrazeny tabulky, které mají být s dotazem propojeny. Mohou být také zobrazeny jejich vzájemné relace ve vztahu k dotazu. Tabulková oblast slouží k výběru polí pro zobrazení nebo k nastavení podmínek týkajících se těchto polí.
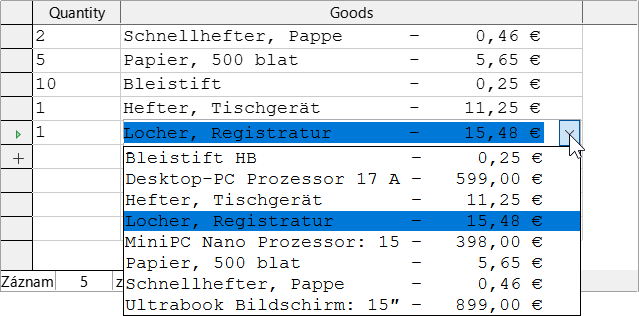
Klepnutím na pole v prvním sloupci v tabulkové oblasti se zobrazí šipka dolů, jak je znázorněno na obrázku 3. Klepnutím na tuto šipku otevřeme rozevírací seznam dostupných polí. Formát je Název_tabulky.Název_pole – proto zde všechny názvy polí začínají slovem Loan.
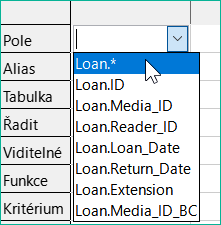
Obrázek 3: Rozevírací seznam dostupných polí
Označení vybraného pole Loan.* má zvláštní význam. Zde můžeme jedním klepnutím přidat do dotazu všechna pole ze zdrojové tabulky. Použijeme-li toto označení polí se zástupným znakem * pro všechna pole, dotaz se od tabulky nerozezná.
Tip
Chceme-li rychle přenést všechna pole tabulky do dotazu, stačí klepnout na zobrazení tabulky v grafickém rozhraní (Loan.* výše).
Dvojitým klepnutím na pole se toto pole vloží do tabulkové oblasti na nejbližší volnou pozici.
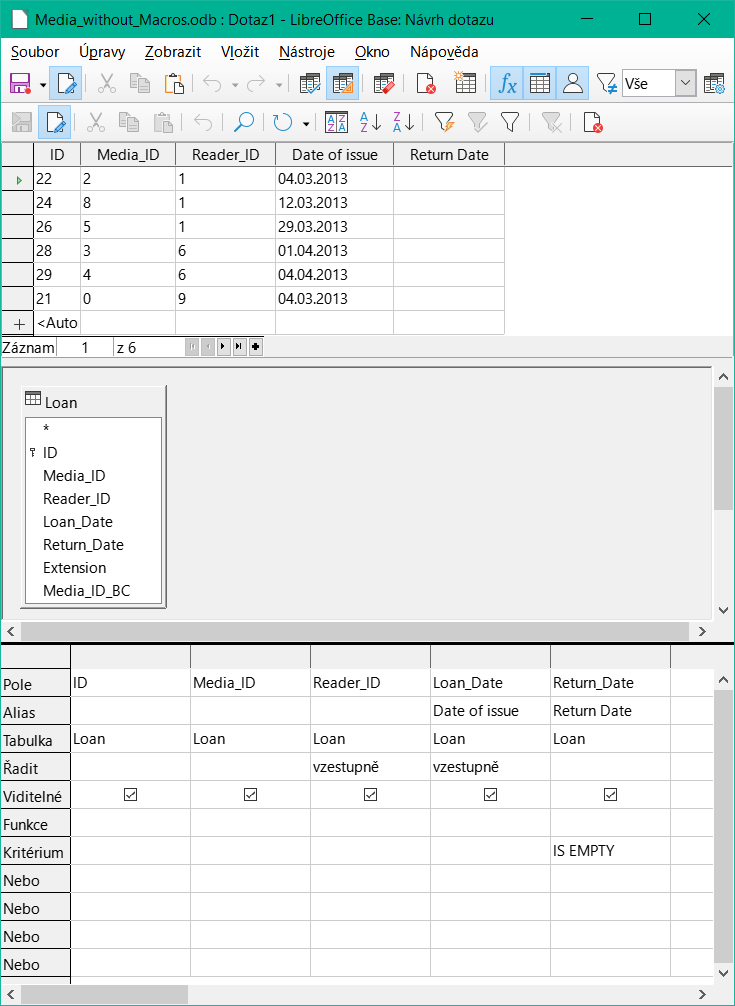
Obrázek 4: Okno návrhu dotazu zobrazující oblast náhledu obsahující výsledky dotazu
Prvních pět polí tabulky Loan je vybráno podle obrázku 4. Dotazy v režimu návrhu lze vždy spustit jako testy klepnutím na tlačítko Spustit dotaz. Tím se nad grafickým zobrazením tabulky Loan se seznamem polí zobrazí tabulka s daty. Před uložením dotazu je vždy vhodné provést jeho testovací spuštění, aby bylo jasné, zda dotaz skutečně dosáhne svého cíle. Logická chyba často zabrání tomu, aby dotaz získal vůbec nějaká data. V jiných případech se může stát, že se zobrazí právě ty záznamy, které jsme chtěli vyloučit.
Dotaz, který v základní databázi vyvolá chybové hlášení, nelze v zásadě uložit, dokud není chyba opravena.
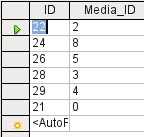
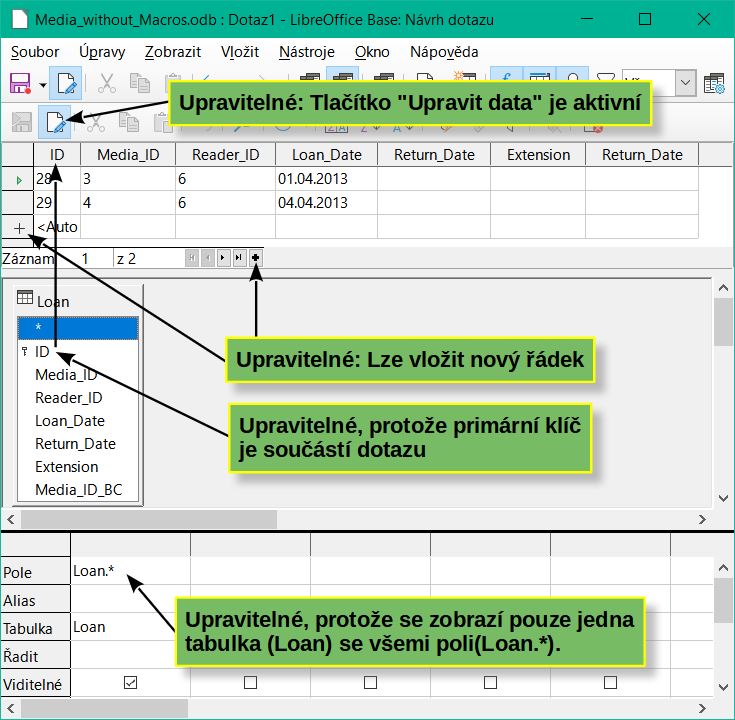
Obrázek 5: Upravitelný dotaz
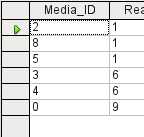
Obrázek 6: Needitovatelný dotaz
Ve výše uvedeném testu věnujeme zvláštní pozornost prvnímu sloupci výsledku dotazu. Značka aktivního záznamu (zelená šipka) se vždy zobrazuje na levé straně tabulky, zde ukazuje na první záznam jako na aktivní záznam. Zatímco první pole prvního záznamu na obrázku 5 je zvýrazněno, odpovídající pole na obrázku 6 zobrazuje pouze čárkovaný okraj. Zvýraznění označuje, že toto pole lze upravit. Jinými slovy, záznamy jsou editovatelné. Čárkovaný rámeček označuje, že toto pole nelze upravovat. Obrázek 5 obsahuje také další řádek pro zadání nového záznamu, přičemž pole ID je již označeno jako <AutoField>. To také ukazuje, že je možné zadávat nové položky.
Tip
Základním pravidlem je, že pokud není v dotazu uveden primární klíč dotazované tabulky, není možné provést žádný nový záznam.

Obrázek 7: Definice aliasů pro pole Loan_Date a Return_Date
Pole Loan_Date a Return_Date mají aliasy, jak je znázorněno na obrázku 7. Tím nedojde k jejich přejmenování, ale pouze k tomu, že se uživateli dotazu zobrazí pod těmito názvy.

Obrázek 8: Pseudonymy používané v záhlavích sloupců výsledků dotazů
Zobrazení tabulky na obrázku 8 ukazuje, jak aliasy nahrazují skutečné názvy polí.

Obrázek 9: Omezení zobrazených záznamů na záznamy s prázdným Return_Date
Pole Return_Date zobrazené na obrázku 9 je rovněž opatřeno vyhledávacím kritériem, které způsobí, že se zobrazí pouze ty záznamy, u nichž je pole Return_Date prázdné. (Do řádku Kritérium v poli Return_Date zadáme IS EMPTY.) Toto vylučovací kritérium způsobí, že se zobrazí pouze ty záznamy, které se týkají médií, která ještě nebyla vrácena.
Obrázek 10: Ikona Zapnout/vypnout zobrazení návrhu na nástrojové liště Návrh dotazu
Občasné přepínání mezi režimem návrhu a režimem SQL pomocí nástroje na obrázku 10 může pomoci při učení jazyka SQL.
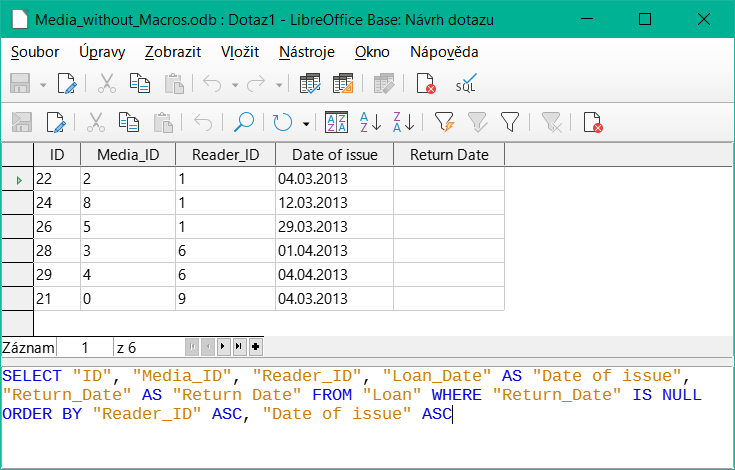
Obrázek 11: Okno návrhu dotazu s vypnutým zobrazením návrhu, zobrazující základní kód SQL
Zde je na obrázku 11 zobrazen vzorec SQL vytvořený našimi předchozími volbami. Pro snazší čtení byly zařazeny některá zalomení řádků. Editor tyto zalomení řádků neukládá, takže při opětovném vyvolání dotazu se zobrazí jako jediný souvislý řádek zalomený na okraji okna.
SELECT začíná výběrová kritéria. AS určuje aliasy polí, které se mají použít. FROM zobrazuje tabulku, která má být použita jako zdroj dotazu. WHERE udává podmínky dotazu, konkrétně, že pole Return_Date má být prázdné (IS NULL). ORDER BY definuje kritéria řazení, konkrétně vzestupné pořadí (ASC – ascending) pro dvě pole Reader_ID a Loan_Date. Tato specifikace třídění ilustruje, jak lze alias pole Loan_Date použít v samotném dotazu.
Tip
Při práci v režimu zobrazení návrhu můžeme pomocí příkazu IS EMPTY požadovat, aby bylo pole prázdné. Při práci v režimu SQL použijeme IS NULL, což vyžaduje jazyk SQL (Structured Query Language).
Pokud chceme řadit sestupně pomocí jazyka SQL, použijeme místo ASC volbu DESC.
Pole Media_ID a Reader_ID jsou zatím viditelná pouze jako číselná pole. Jména čtenářů jsou nejasná. Chceme-li je zobrazit v dotazu, musí být do dotazu zahrnuta tabulka Reader. Za tímto účelem se vrátíme do režimu návrhu. Poté lze do zobrazení Návrh přidat novou tabulku pomocí nástroje na obrázku 12.
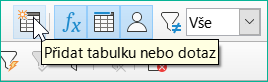
Obrázek 12: Ikona Přidat tabulku nebo dotaz na panelu nástrojů Návrh
Zde lze následně přidat další tabulky nebo dotazy a zviditelnit je v grafickém uživatelském rozhraní. Pokud byly vazby mezi tabulkami deklarovány při jejich vytváření (viz kapitola 3, Tabulky), pak jsou tyto tabulky zobrazeny s příslušnými přímými vazbami na obrázku 13.
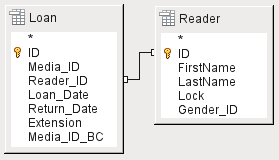
Obrázek 13: Tabulka čtenářů přidaná do grafické oblasti okna Návrh dotazu
Pokud odkaz chybí, lze jej v tomto okamžiku vytvořit přetažením myší z položky "Loan". "Reader_ID" na položku "Reader". "ID".
Poznámka
Propojení tabulek funguje pouze v interní databázi nebo v externích relačních databázích. Například tabulky z tabulkového procesoru propojit nelze. Nejprve je třeba je importovat do interní databáze.
K vytvoření propojení mezi tabulkami stačí prostý import bez dodatečného vytvoření primárního klíče.
Nyní lze do tabulkové oblasti zadat pole z tabulky Reader. Pole jsou zpočátku přidána na konec dotazu, jak je znázorněno na obrázku 14.
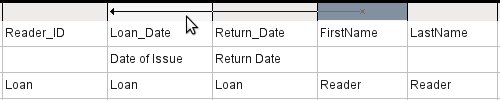
Obrázek 14: Změna pozice pole dotazu
Polohu polí lze v tabulkové oblasti editoru opravit pomocí myši. Takže například pole FirstName bylo na obrázku 15 přetaženo na pozici přímo před pole Loan_Date.
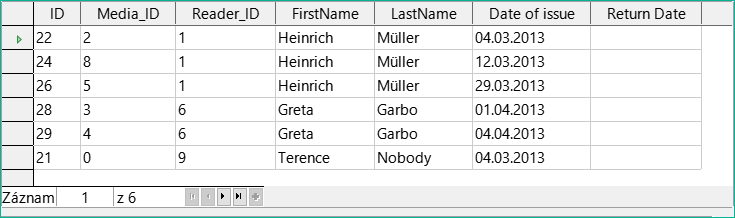
Obrázek 15: Aktualizovaná tabulková oblast okna Návrh dotazu
Nyní jsou jména viditelná. Pole Reader_ID se stalo nadbytečným. Také řazení podle LastName a FirstName dává větší smysl než řazení podle Reader_ID.
Tento dotaz již není vhodný pro použití jako dotaz, který umožňuje zadávat nové záznamy do výsledné tabulky, protože v něm chybí primární klíč pro přidanou tabulku Reader. Teprve pokud je tento primární klíč zabudován, je dotaz opět editovatelný. Ve skutečnosti je pak zcela upravitelný, takže lze měnit i jména čtenářů. Z tohoto důvodu je možnost upravovat výsledky dotazů možností, kterou je třeba používat s nejvyšší opatrností, v případě potřeby pod kontrolou formuláře.
Upozornění
Problémy může způsobit dotaz, který můžeme upravovat. Úpravou dat v dotazu se upravují také data v podkladové tabulce a záznamy v ní obsažené. Údaje nemusí mít stejný význam. Například změníme jméno čtenáře, a tím změníme i to, jaké knihy si čtenář vypůjčil a vrátil.
Pokud musíme data upravovat, provádějme to ve formuláři, abychom viděli účinky úprav dat.
I když lze dotaz dále upravovat, není tak snadné jej používat jako formulář s poli se seznamem, který zobrazuje jména čtenářů, ale obsahuje Reader_ID z tabulky. Pole se seznamem nelze přidat do dotazu; lze je použít pouze ve formulářích.

Obrázek 16: Kód SQL pro dotaz obsahující pole z více tabulek
Pokud se nyní přepneme zpět do zobrazení SQL, vidíme na obrázku 16 , že všechna pole jsou nyní zobrazena v dvojitých uvozovkách: "Název_tabulky". "Název_pole" oddělená tečkou. To je nutné, aby databáze věděla, ze které tabulky pocházejí dříve vybraná pole. Vždyť pole v různých tabulkách mohou mít snadno stejné názvy. Ve výše uvedené struktuře tabulky to platí zejména pro pole ID.
Poznámka
Následující dotaz funguje bez uvedení názvů tabulek před názvy polí:
SELECT "ID", "Number", "Price" FROM "Stock", "Dispatch" WHERE "Dispatch"."stockID" = "Stock"."ID"
Zde je ID převzato z tabulky, která je v definici FROM na prvním místě. Definice tabulky ve vzorci WHERE je také zbytečná, protože stockID se vyskytuje pouze jednou (v tabulce Dispatch) a ID bylo jednoznačně převzato z tabulky Stock (z pozice tabulky v dotazu).
Pokud má pole v dotazu alias, lze na něj odkazovat – například při třídění – pomocí tohoto aliasu, aniž by byl uveden název tabulky. Třídění se provádí v grafickém uživatelském rozhraní podle pořadí polí v tabulkovém zobrazení. Pokud chceme místo toho řadit nejprve podle "Loan_Date" a poté podle "Loan". "Reader_ID", lze to provést, pokud:
Změní se pořadí polí v oblasti tabulky grafického uživatelského rozhraní (přetáhneme "Loan_Date" vlevo od "Loan". "Reader_ID" nebo "Loan_ID").
Přidá se další pole, nastavené jako neviditelné, pouze pro třídění (editor jej však zaregistruje pouze dočasně, pokud pro něj nebyl definován alias) [přidáme další pole "Loan_Date" těsně před "Loan". "Reader_ID" nebo přidáme další pole "Loan". "Reader_ID" těsně za "Loan_Date"], nebo
Text příkazu ORDER BY v SQL editoru se odpovídajícím způsobem změní (ORDER BY "Loan_Date", "Loan". "Reader_ID").
Tip
Dotaz může vyžadovat pole, které není součástí výstupu dotazu. V grafice v následující části je příklad dotazu Return_Date. Tento dotaz vyhledává záznamy, které neobsahují datum vrácení. Toto pole poskytuje kritérium pro dotaz, ale neobsahuje žádné užitečné viditelné údaje.
Použití funkcí umožňuje dotazu poskytnout více než jen filtrovaný pohled na data v jedné nebo více tabulkách. Dotaz na obrázku 17 vypočítá, kolik médií bylo vypůjčeno v závislosti na identifikátoru Reader_ID.

Obrázek 17: Použití funkce Count k výpočtu počtu vypůjčených položek pro každé Reader_ID
Pro ID tabulky Loan je vybrána funkce Count. V zásadě je jedno, které pole tabulky je pro tento účel vybráno. Jedinou podmínkou je, že pole nesmí být v žádném ze záznamů prázdné. Z tohoto důvodu je nejvhodnější volbou pole primárního klíče, které není nikdy prázdné. Započítávají se všechna pole s jiným obsahem než NULL.
Pro identifikátor Reader_ID, který umožňuje přístup k informacím o čtenáři, je zvolena funkce Seskupení. Tímto způsobem jsou záznamy se stejným Reader_ID seskupeny dohromady. Výsledek na obrázku 18 ukazuje počet záznamů pro každé Reader_ID.
Jako kritérium vyhledávání je Return_Date nastaveno na "IS EMPTY", stejně jako v předchozím příkladu. (Níže je uveden následující SQL příkaz WHERE "Return_Date" IS NULL.)
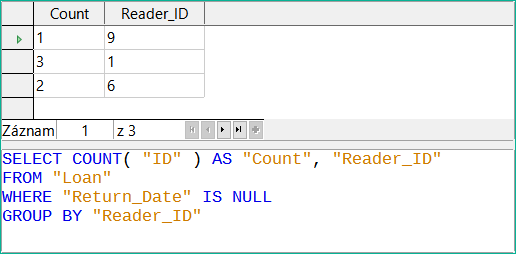
Obrázek 18: Výsledky a kód SQL pro dotaz na zjištění počtu vypůjčených položek pro každé Reader_ID
Výsledek dotazu ukazuje, že Reader_ID '0' má celkem 3 vypůjčená média. Kdyby byla funkce Count přiřazena k Return_Date místo k ID, měl by každý Reader_ID na výpůjčce médium '0', protože Return_date je předdefinován jako NULL.
Odpovídající vzorec v kódu SQL je rovněž uveden na obrázku 18.
Celkově grafické uživatelské rozhraní poskytuje funkce uvedené vpravo, které odpovídají funkcím v základní databázi HSQLDB.
Vysvětlení funkcí nalezneme v části „Vylepšení dotazu pomocí režimu SQL“ na straně 1.
Pokud je jedno pole v dotazu spojeno s funkcí, musí být všechna zbývající pole uvedená v dotazu také spojena s funkcemi, pokud mají být zobrazena. Pokud to není zajištěno, zobrazí se chybové hlášení na obrázku 19:
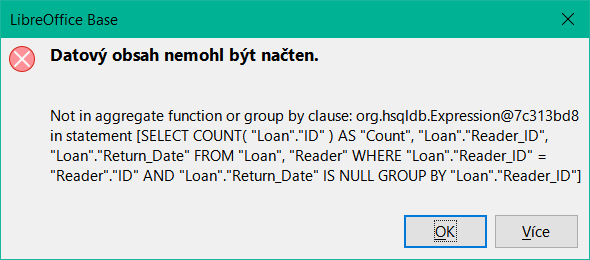
Obrázek 19: Dialogové okno s chybou zobrazené v případě, že pole není přiřazeno k funkci
Poněkud volný překlad by zněl: Následující výraz neobsahuje žádnou agregační funkci ani seskupení.
Tip
Při použití režimu zobrazení návrhu je pole viditelné pouze tehdy, pokud je v řádku Viditelné zaškrtnuto. Při použití SQL režimu je pole viditelné pouze tehdy, když následuje za klíčovým slovem SELECT.
Poznámka
Pokud pole není spojeno s funkcí, je počet řádků ve výstupu dotazu určen podmínkami vyhledávání. Pokud je pole spojeno s funkcí, je počet řádků ve výstupu dotazu určen tím, zda je či není provedeno seskupení. Pokud nedojde k seskupení, je ve výstupu dotazu pouze jeden řádek. Pokud existuje seskupení, počet řádků odpovídá počtu různých hodnot, které má pole se zvolenou funkcí seskupení. Všechna viditelná pole tedy musí být buď spojena s funkcí, nebo musí být spojena s příkazem seskupení, aby se zabránilo tomuto konfliktu ve výstupu dotazu.
Poté je v chybové zprávě uveden celý dotaz, ale bez konkrétního názvu chybného pole. V tomto případě bylo pole Return_Date přidáno jako zobrazované pole. Toto pole nemá žádnou přidruženou funkci a není zahrnuto ani v příkazu pro seskupení.
Informace poskytnuté pomocí tlačítka Více zahrnují kód chyby SQL, ale pro běžného uživatele databáze nemusí být příliš poučné.
Chceme-li chybu opravit, odstraníme zaškrtnutí v řádku Viditelné u pole Return_Date. Jeho vyhledávací podmínka (Kritérium) je použita při spuštění dotazu, ale není viditelná ve výstupu dotazu.
Pomocí grafického uživatelského rozhraní lze provádět základní výpočty a používat další funkce.
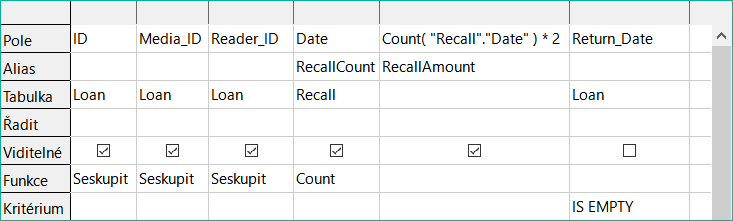
Obrázek 20: Dotaz na výpočet pokuty za položku u opožděných médií
Předpokládejme, že knihovna nevydává upomínky, když má být položka vrácena, ale vydává upomínky za zpoždění v případech, kdy výpůjční lhůta uplynula a položka nebyla vrácena. To je běžná praxe ve školních a veřejných knihovnách, které půjčují pouze na krátkou, pevně stanovenou dobu. V tomto případě vydání oznámení o prodlení automaticky znamená, že musí být zaplacena pokuta. Jak tyto pokuty vypočítáme?
V dotazu na obrázku 20 jsou tabulky Loan a Recalls dotazovány společně. Z počtu datových záznamů v tabulce Recalls se zjistí celkový počet oznámení o vrácení. Pokuta za zpožděná média je v dotazu stanovena na 2,00 USD. Místo názvu pole je označení pole uvedeno jako Count(Recalls.Date)*2. Grafické uživatelské rozhraní přidá uvozovky a převede výraz „count“ na příslušný příkaz SQL.
Upozornění
Pouze pro ty, kteří používají čárku jako oddělovač desetinných míst:
Pokud chceme zadávat čísla s desetinnými místy pomocí grafického uživatelského rozhraní, musíme zajistit, aby se v konečném příkazu SQL použila jako oddělovač desetinných míst desetinná tečka, nikoli čárka. Jako oddělovače polí se používají čárky, takže pro desetinnou část se vytvoří nové pole dotazu.
Položka s čárkou v zobrazení SQL vždy vede k dalšímu poli obsahujícímu číselnou hodnotu desetinné části, jak je znázorněno na obrázku 21.
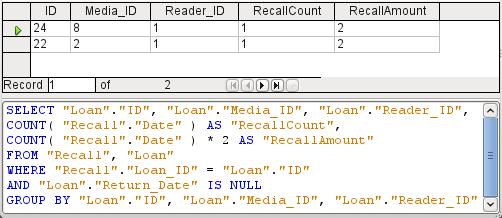
Obrázek 21: Výsledky a kód SQL pro dotaz na výpočet pokuty za položku pro opožděné vrácení médií
Dotaz nyní pro každé médium, které je stále zapůjčeno, zobrazuje pokuty, které narostly na základě vydaných oznámení o vrácení, a pole pro dodatečnou multiplikaci. Struktura dotazu na obrázku 22 bude užitečná i pro výpočet dlužných pokut od jednotlivých uživatelů.
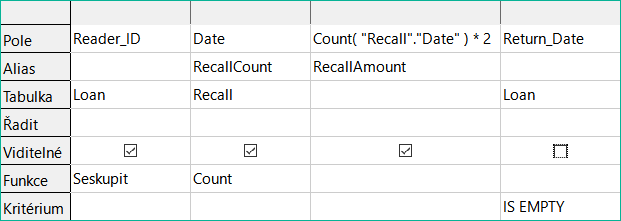
Obrázek 22: Dotaz na výpočet pokut za zpoždění médií pro každé Reader_ID
Pole "Loan". "ID" a "Loan". "Media_ID" byla odstraněna. Byly použity v předchozím dotazu k vytvoření samostatného záznamu pro každé médium. Nyní budeme seskupovat pouze podle čtenáře. Výsledek dotazu je zobrazen na obrázku 23:
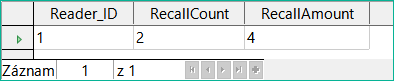
Obrázek 23: Výsledky dotazu na výpočet pokut za opožděné vrácení médií pro každé Reader_ID
Namísto samostatného výpisu médií pro Reader_ID = 0 byla započítána všechna pole "Recalls". "Date" a celková částka 8,00 USD byla zadána jako dlužná pokuta.
Při vyhledávání dat v tabulkách nebo formulářích je vyhledávání obvykle omezeno na jednu tabulku nebo jeden formulář. Dokonce ani cesta z hlavního formuláře do podformuláře není navigovatelná pomocí vestavěné vyhledávací funkce. Takové údaje je lepší shromažďovat pomocí dotazu.
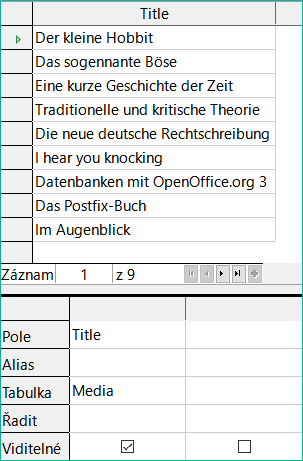
Obrázek 24: Dotaz na zobrazení názvů z tabulky Media
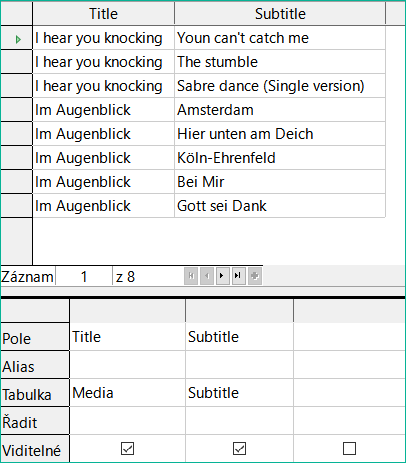
Obrázek 25: Dotaz na zobrazení názvů a titulků z tabulky Media
Jednoduchý dotaz na pole Title z tabulky Media na obrázku 24 zobrazuje testovací záznamy pro tuto tabulku, celkem 9 záznamů. Pokud však do dotazovací tabulky zadáte položku Subtitle, obsah záznamu v tabulce Media se zmenší na pouhé 2 tituly. Pouze pro tyto dva Titles (tituly, pozn. překl.) jsou v tabulce uvedeny také Subtitles (podtituly, pozn. překl.), jak ukazuje obrázek 25. U všech ostatních titulů podtituly neexistují. To odpovídá podmínce spojení uvedené na obrázku 26 , že se mají zobrazit pouze ty záznamy, u nichž se pole Media_ID v tabulce Subtitles rovná poli ID v tabulce Media. Všechny ostatní záznamy jsou vyloučeny.
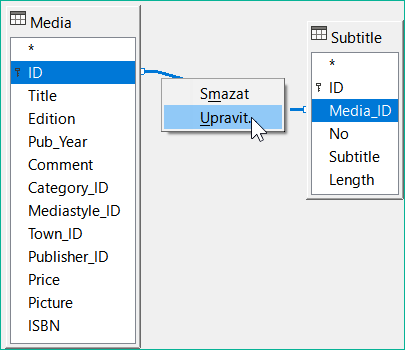
Obrázek 26: Úprava spojení v rámci dotazu
Aby se zobrazily všechny požadované záznamy, je třeba otevřít podmínky spojení pro úpravy. V tomto případě nemáme na mysli spojení mezi tabulkami v rámci návrhu relací, ale spojení v rámci dotazů.
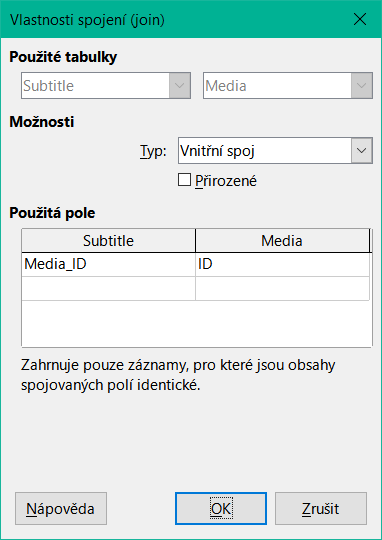
Obrázek 27: Dialogové okno Vlastnosti spojení zobrazující výchozí nastavení Typ vnitřního spojení
Ve výchozím nastavení jsou relace nastaveny jako vnitřní spojení, což znamená, že dotaz vrátí pouze záznamy, jejichž obsah souvisejících polí obou tabulek je totožný. Na obrázku 27 je zobrazeno okno s informacemi o tom, jak tento typ spojení funguje v praxi.
Dvě dříve vybrané tabulky jsou uvedeny v seznamu Použité tabulky. Zde je nelze vybrat. Příslušná pole z obou tabulek se načtou z definic tabulek. Pokud není v definici tabulky zadán žádný vztah, lze jej v tomto okamžiku pro dotaz vytvořit. Pokud jsme však databázi naplánovali přehledně pomocí HSQLDB, nemělo by být nutné tato pole měnit.
Nejdůležitějším nastavením je možnost Join. Zde lze relace zvolit tak, aby byly vybrány všechny záznamy z tabulky Subtitles, ale pouze ty záznamy z Media, které mají v tabulce Subtitles zadaný titulek.
Nebo můžeme zvolit opačný postup: že se v každém případě zobrazí všechny záznamy z tabulky Media bez ohledu na to, zda mají podtitul.
Volba Přirozené určuje, že propojená pole v tabulkách jsou považována za rovnocenná. Tomuto nastavení se můžeme vyhnout také správným definováním relací na samém začátku plánování databáze.
Pro typ Pravý spoj popis ukazuje, že se zobrazí všechny záznamy z tabulky Media (Subtitle RIGHT JOIN Media). Vzhledem k tomu, že v Media neexistuje žádný Subtitle, kterému by chyběl název, ale v Media určitě existují Titles, kterým chybí Subtitles, je tato volba správná, jak ukazuje obrázek 28.
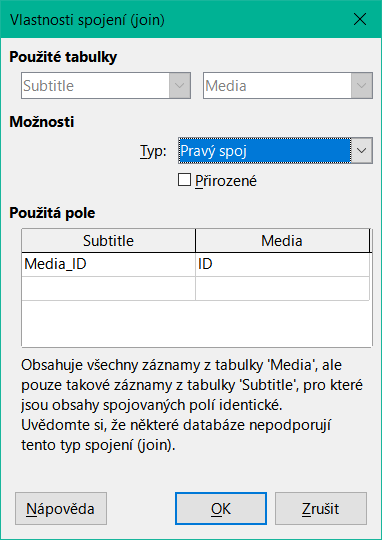
Obrázek 28: Dialogové okno Vlastnosti spojení s typem nastaveným na Pravé spojení
Po potvrzení Pravého spoje vypadají výsledky dotazu tak, jak jsme chtěli. Title a Subtitle se zobrazují společně v jednom dotazu, který je znázorněn na obrázku 29. Samozřejmě se tituly objevují vícekrát, stejně jako u předchozí relace. Pokud se však nepočítají shody, lze tento dotaz dále použít jako základ vyhledávací funkce. Viz fragmenty kódu v této kapitole, v kapitole 8, Úlohy databáze, a v kapitole 9, Makra.
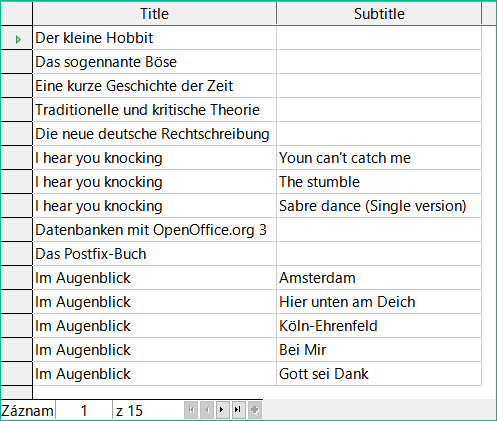
Obrázek 29: Výsledek dotazu zobrazující všechny názvy a titulky (pokud existují)
Od LibreOffice verze 4.1 je možné v editoru dotazů definovat další vlastnosti.
Obrázek 30: Ikona Vlastnosti dotazu na nástrojové liště Návrh
Vedle tlačítka pro otevření okna Vlastnosti dotazu se nachází pole se seznamem pro regulaci počtu zobrazených záznamů a tlačítko Rozlišit hodnoty (viz obrázek 30). Tyto funkce se opakují v dialogovém okně na obrázku 31:
Obrázek 31: Dialogové okno Vlastnosti dotazu
Nastavení Jedinečné hodnoty určuje, zda má dotaz potlačit duplicitní záznamy.
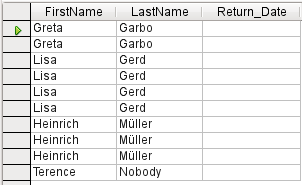
Obrázek 32: Výstup dotazu s hodnotou Rozlišovat hodnoty nastavenou na Ne
Předpokládejme, že se provede dotaz na čtenáře, kteří mají stále vypůjčené knihy. Jejich názvy se zobrazí, pokud je pole pro datum vrácení prázdné. Pro čtenáře, kteří mají vypůjčeno více položek, se názvy zobrazují vícekrát, jak je znázorněno na obrázku 32.
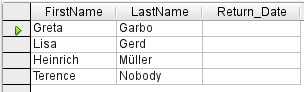
Obrázek 33: Výstup dotazu s hodnotou Rozlišovat hodnoty nastavenou na Ano
Pokud zvolíme možnost Odlišné hodnoty, zmizí záznamy se stejným obsahem, jak je znázorněno na obrázku 33.
Dotaz pak vypadá takto:

Původní dotaz:
SELECT "Reader"."FirstName", "Reader"."LastName" …
Přidáním DISTINCT do dotazu se duplicitní záznamy potlačí.
SELECT DISTINCT "Reader"."FirstName", "Reader"."LastName" …
V dřívějších verzích bylo pro zadání jedinečných záznamů nutné přepnout z režimu návrhu do režimu SQL a vložit kvalifikátor DISTINCT. Tato vlastnost je zpětně kompatibilní s předchozími verzemi LO a nezpůsobuje žádné problémy.
Nastavení Limit určuje, kolik záznamů se má v dotazu zobrazit. Zobrazen je pouze omezený počet záznamů.
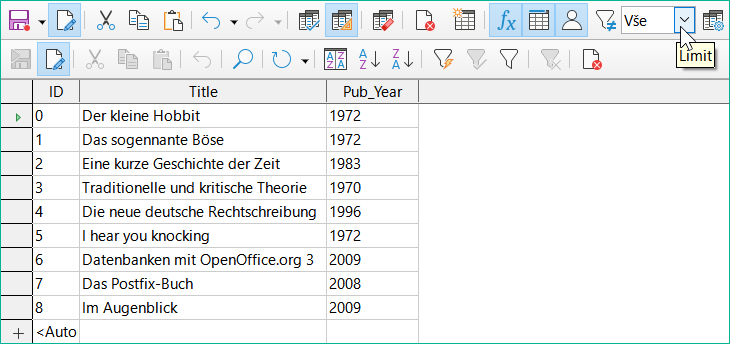
Obrázek 34: Výstup dotazu zobrazující všechny záznamy v tabulce Media
Všechny záznamy v tabulce Media jsou zobrazeny na obrázku 34. Dotaz je upravitelný, protože obsahuje primární klíč.
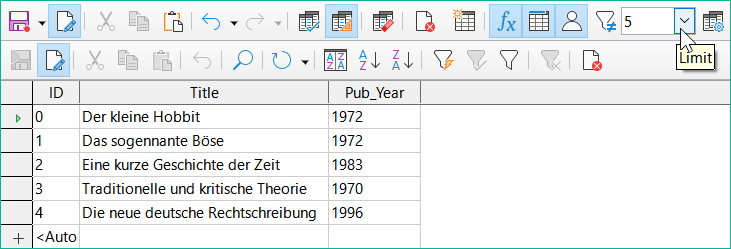
Obrázek 35: Výstup dotazu omezený na zobrazení prvních pěti záznamů v tabulce Media
Nastavením limitu uvedeného na obrázku 35 se zobrazí pouze prvních pět záznamů (ID 0-4). Nebylo požadováno řazení, proto je použito výchozí řazení podle primárního klíče. I přes omezení výstupu lze dotaz dále upravovat. Tím se vstup v grafickém rozhraní liší od toho, co bylo v předchozích verzích dostupné pouze pomocí jazyka SQL.
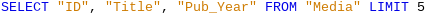
Do původního dotazu bylo jednoduše přidáno „LIMIT 5“. Velikost limitu může být libovolná.
Upozornění
Nastavení limitů v grafickém rozhraní není zpětně kompatibilní. Ve všech verzích LO před verzí 4.1 bylo možné limit nastavit pouze v režimu přímého SQL. Omezení pak vyžadovalo třídění (ORDER BY ...) nebo podmínku (WHERE ...).
Pokud při grafickém zadávání vypneme zobrazení návrhu pomocí Zobrazit > Režim návrhu zap/vyp, zobrazí se příkaz SQL pro to, co se dříve zobrazovalo v zobrazení návrhu. To může začátečníkům pomoci naučit se standardní dotazovací jazyk (Standard Query Language) pro databáze. Někdy je to také jediný způsob, jak zadat dotaz do databáze, pokud grafické uživatelské rozhraní nedokáže převést vaše požadavky na potřebné příkazy SQL.
SELECT * FROM "Table_name"
Zobrazí se vše, co je v tabulce Table_name. Znak "*" představuje všechna pole tabulky.
SELECT * FROM "Table_name" WHERE "Field_name" = 'Karl'
Zde existuje významné omezení. Zobrazí se pouze ty záznamy, u nichž pole Field_name obsahuje výraz „Karl“ – přesný výraz, nikoli například „Karl Egon“.
Někdy nelze dotazy v aplikaci Base provádět pomocí grafického uživatelského rozhraní, protože určité příkazy nemusí být rozpoznány. V takových případech je nutné vypnout zobrazení návrhu a pro přímý přístup k databázi použít příkaz Úpravy > Spustit SQL příkaz přímo. Tato metoda má tu nevýhodu, že s dotazem lze pracovat pouze v režimu SQL.
Obrázek 36: Ikona přímého spuštění příkazu SQL na panelu nástrojů SQL
Přímé použití příkazů SQL je dostupné také pomocí grafického uživatelského rozhraní, jak ukazuje obrázek 36. Klepnutím na zvýrazněnou ikonu (Spustit SQL příkaz přímo) vypneme ikonu Režim návrhu zap/vyp.. Nyní se po klepnutí na ikonu Spustit, spustí přímo příkazy SQL.
Zde je příklad rozsáhlých možností, které jsou k dispozici pro zadávání dotazů do databáze a určování typu požadovaného výsledku:
SELECT [{LIMIT <offset> <limit> | TOP <limit>}][ALL | DISTINCT]
{ <Select-Formulation> | "Table_name".* | * } [, ...]
[INTO [CACHED | TEMP | TEXT] "new_Table"]
FROM "Table_list"
[WHERE SQL-Expression]
[GROUP BY SQL-Expression [, ...]]
[HAVING SQL-Expression]
[{ UNION [ALL | DISTINCT] | {MINUS [DISTINCT] | EXCEPT [DISTINCT] } |
INTERSECT [DISTINCT] } Query statement]
[ORDER BY Order-Expression [, ...]]
[LIMIT <limit> [OFFSET <offset>]];
[{LIMIT <offset> <limit> | TOP <limit>}]:
[ALL | DISTINCT]
<Select-Formulation>
{ Expression | COUNT(*) |
{ COUNT | MIN | MAX | SUM | AVG | SOME | EVERY | VAR_POP | VAR_SAMP | STDDEV_POP | STDDEV_SAMP }
([ALL | DISTINCT]] Expression) } [[AS] "display_name"]
Poznámka
Výpočty v databázi někdy vedou k neočekávaným výsledkům. Předpokládejme, že databáze obsahuje známky udělené za nějakou práci ve třídě a že chceme vypočítat průměrnou známku.
Nejprve musíme sečíst všechny známky. Předpokládejme, že součet je 80. Nyní je třeba tuto hodnotu vydělit počtem žáků (řekněme 30). Výsledkem dotazu je 2.
K tomu dochází, protože pracujeme s poli typu INTEGER. Výsledkem výpočtu proto musí být celočíselná hodnota. Ve výpočtu musíme mít alespoň jednu hodnotu typu DECIMAL. Toho můžeme dosáhnout buď pomocí převodní funkce HSQLDB nebo (jednodušeji) můžeme dělit číslem 30,0 namísto 30. Tím získáme výsledek s jedním desetinným místem. Dělením 30.00 získáme dvě desetinná místa. Dbáme na používání desetinných míst v anglickém stylu. Použití čárek v dotazech je vyhrazeno pro oddělovače polí.
COUNT | MIN | MAX | SUM | AVG | SOME | EVERY | VAR_POP | VAR_SAMP | STDDEV_POP | STDDEV_SAMP
Tip
Tato funkce selhává také v polích pro čas. Zde mohou být užitečné následující informace:
SELECT (SUM( HOUR("Time") )*3600 + SUM( MINUTE("Time") ))*60 + SUM( SECOND("Time") ) AS "seconds" FROM "Table"
Zobrazený součet se skládá z jednotlivých hodin, minut a sekund. Poté se upraví tak, aby se získal celkový součet v jedné jednotce, v tomto případě v sekundách. Zde se pak funkcí sum sčítají pouze celá čísla. Pokud nyní použijeme:
SELECT ((SUM( HOUR("Time") )*3600 + SUM( MINUTE("Time") ))*60 + SUM( SECOND("Time") )) / 3600.0000 AS "hours" FROM "Table"
získáme čas v hodinách s minutami a sekundami jako desetinnými místy. Při vhodném formátování můžeme tuto hodnotu v dotazu nebo formuláři změnit zpět na normální časovou hodnotu.
Tip
Typ pole logického typu je Yes/No[BOOLEAN]. Toto pole však obsahuje pouze 0 nebo 1. V podmínkách vyhledávání dotazu použijeme buď TRUE, 1, FALSE nebo 0. Pro podmínku Yes můžeme použít hodnotu TRUE nebo 1. Pro podmínku No použijeme buď FALSE, nebo 0. Pokud se místo toho pokusíme použít „Yes“ nebo „No“, zobrazí se chybová zpráva. Pak budeme muset svou chybu opravit.
SELECT "Class", EVERY("Swimmer")
FROM "Table1"
GROUP BY "Class";
"Table_name".* | * [, ...]
[INTO [CACHED | TEMP | TEXT] "new_table"]
"Table_name 1" [{CROSS | INNER | LEFT OUTER | RIGHT OUTER} JOIN "Table_name 2" ON Expression] [, ...]
SELECT "Table1"."Name", "Table2"."Class"
FROM "Table1", "Table2"
WHERE "Table1"."ClassID" = "Table2"."ID"
SELECT "Table1"."Name", "Table2"."Class"
FROM "Table1"
JOIN "Table2"
ON "Table1"."ClassID" = "Table2"."ID"
SELECT "Table1"."Name", "Table2"."Class"
FROM "Table1"
LEFT JOIN "Table2"
ON "Table1"."ClassID" = "Table2"."ID"
SELECT "Table1"."Player1", "Table2"."Player2"
FROM "Table1" AS "Table1"
CROSS JOIN "Table2" AS "Table1"
WHERE "Table1"."Player1" <> "Table2"."Player2"
SELECT "Table1"."Name", "Table2"."Class"
FROM "Table1"
JOIN "Table2"
ON "Table1"."ClassID" = "Table2"."ID"
SELECT "Table1"."Name", "Table2"."Class"
FROM "Table1" AS "Table1"
CROSS JOIN "Table2" AS "Table2"
WHERE "Table1"."ClassID" = "Table2"."ID"
[WHERE SQL-Expression]
[GROUP BY SQL-Expression [, …]]
SELECT "Name", SUM("Input"-"Output") AS "Balance"
FROM "Table1"
GROUP BY "Name";
Tip
Pokud jsou pole zpracována pomocí určité funkce (například COUNT, SUM ...), všechna pole, která nejsou zpracována pomocí funkce, ale mají být zobrazena, jsou seskupena pomocí GROUP BY.
[HAVING SQL-Expression]
SELECT "Name", "Runtime"
FROM "Table1"
GROUP BY "Name", "Runtime"
HAVING MIN("Runtime") < '00:40:00';
SELECT "Name", SUM("Input"-"Output") AS "Balance"
FROM "Table1"
GROUP BY "Name"
HAVING SUM("Input"-"Output") > 0;
[SQL Expression]
[NOT] podmínka [{ OR | AND } podmínka]
SELECT *
FROM "Table_name"
WHERE NOT "Return_date" IS NULL AND "ReaderID" = 2;
SELECT *
FROM "Table_name"
WHERE NOT ("Return_date" IS NULL AND "ReaderID" = 2);
[SQL Expression]: podmínky
{ hodnota [|| hodnota]
SELECT "Surname" || ', ' || "First_name" AS "Name"
FROM "Table_name"
| hodnota { = | < | <= | > | >= | <> |!= } hodnota
| hodnota IS [NOT] NULL
| EXISTS(Query_result)
SELECT "Name"
FROM "Table1"
WHERE EXISTS
(SELECT "First_name"
FROM "Table2"
WHERE "Table2"."First_name" = "Table1"."Name")
| Hodnota BETWEEN Hodnota AND Hodnota
SELECT "Name"
FROM "Table_name"
WHERE "Name" BETWEEN 'A' AND 'E';
| hodnota [NOT] IN ( {hodnota [, ...] | výsledek dotazu } )
| hodnota [NOT] LIKE hodnota [ESCAPE] hodnota }
SELECT "Name"
FROM "Table_name"
WHERE "Name" LIKE '\_%' ESCAPE '\'
[SQL Expression]: hodnoty
[+ | –] { Výraz [{ + | – | * | / | | } Výraz]
SELECT "Surname"||', '||"First_name"
FROM "Table"
| ( Podmínka )
| Funkce ( [Parametr] [,...] )
| Výsledek dotazu, který dává přesně jednu odpověď
| {ANY|ALL} (Výsledek dotazu, který dává přesně jednu odpověď z celého sloupce)
[SQL Expression]: Výraz
{ 'Text' | Celé číslo | Číslo s plovoucí desetinnou čárkou
| ["Table".]"Field" | TRUE | FALSE | NULL }
UNION [ALL | DISTINCT] Query_result
SELECT "First_name"
FROM "Table1"
UNION DISTINCT
SELECT "First_name"
FROM "Table2";
SELECT
"Sales_price"
FROM "Stock" WHERE "Stock_ID" = 1
UNION
SELECT
"Rebate_price_1"
FROM "Stock" WHERE "Stock_ID" = 1
UNION
SELECT
"Rebate_price_2"
FROM "Stock" WHERE "Stock_ID" = 1;
MINUS [DISTINCT] | EXCEPT [DISTINCT] Query_result
SELECT "First_name"
FROM "Table1"
EXCEPT
SELECT "First_name"
FROM "Table2";
INTERSECT [DISTINCT] Query_result
SELECT "First_name"
FROM "Table1"
INTERSECT
SELECT "First_name"
FROM "Table2";
[ORDER BY Ordering-Expression [, …]]
SELECT "First_name", "Surname" AS "Name"
FROM "Table1"
ORDER BY "Surname";
SELECT "First_name", "Surname" AS "Name"
FROM "Table1"
ORDER BY 2;
SELECT "First_name", "Surname" AS "Name"
FROM "Table1"
ORDER BY "Name";
[LIMIT <limit> [OFFSET <offset>]]:
Dotazy mohou reprodukovat pole se změněnými názvy.
SELECT "First_name", "Surname" AS "Name"
FROM "Table1"
Pole Surname se v zobrazení nazývá Name.
Pokud dotaz zahrnuje dvě tabulky, musí být před názvem každého pole uveden název tabulky:
SELECT "Table1"."First_name", "Table1"."Surname" AS "Name", "Table2"."Class"
FROM "Table1", "Table2"
WHERE "Table1"."Class_ID" = "Table2"."ID"
Názvu tabulky lze také přidělit alias, ale tato změna se projeví pouze v dotazu a neprojeví se v zobrazení tabulky. Pokud je takový alias nastaven, je třeba odpovídajícím způsobem změnit všechny názvy tabulek v dotazu:
SELECT "a"."First_name", "a"."Surname" AS "Name", "b"."Class"
FROM "Table1" AS "a", "Table2" AS "b"
WHERE "a"."Class_ID" = "b"."ID"
Přiřazení aliasu tabulce lze provést stručněji bez použití termínu AS:
SELECT "a"."First_name", "a"."Surname" "Name", "b"."Class"
FROM "Table1" "a", "Table2" "b"
WHERE "a"."Class_ID" = "b"."ID"
Tím se však kód stává méně čitelným. Z tohoto důvodu by se zkrácený formulář měl používat pouze ve výjimečných případech.
Poznámka
Kód editoru dotazů v grafickém uživatelském rozhraní byl nedávno změněn tak, aby se označení aliasů vytvářela bez použití předpony AS. Je to proto, že při použití externích databází, jejichž způsob zadávání aliasů nelze předvídat, vedlo zahrnutí AS k chybovým hlášením.
Pokud je kód dotazu otevřen k úpravám nikoli přímo v SQL, ale pomocí grafického uživatelského rozhraní, stávající aliasy ztratí předponu AS. Pokud je to pro nás důležité, musíme dotazy vždy upravovat v režimu SQL.
Aliasový název také umožňuje použít tabulku s odpovídajícím filtrováním více než jednou v rámci dotazu:
SELECT "KasseAccount"."Balance", "Account"."Date",
"a"."Balance" AS "Actual",
"b"."Balance" AS "Desired"
FROM "Account"
LEFT JOIN "Account" AS "a"
ON "Account"."ID" = "a"."ID" AND "a"."Balance" >= 0
LEFT JOIN "Account" AS "b"
ON "Account"."ID" = "b"."ID" AND "b"."Balance" < 0
V polích se seznamem se zobrazuje hodnota, která neodpovídá obsahu podkladové tabulky. Používají se k zobrazení hodnoty, kterou uživatel přiřadil cizímu klíči, a nikoli samotného klíče. Hodnota, která je nakonec uložena ve formuláři, se nesmí vyskytovat na první pozici pole seznamu.
SELECT "FirstName", "ID"
FROM "Table1";
Tento dotaz by zobrazil všechna křestní jména a hodnoty primárního klíče "ID", které poskytuje základní tabulka formuláře. Samozřejmě to ještě není optimální. Křestní jména nejsou seřazena a v případě stejných křestních jmen nelze určit, o kterou osobu se jedná.
SELECT "FirstName"||' '||"LastName", "ID"
FROM "Table1"
ORDER BY "FirstName"||' '||"LastName";
Nyní se zobrazí jméno i příjmení oddělené mezerou. Jména se stanou rozlišitelnými a jsou také seřazena. Řazení se však řídí obvyklou logikou, kdy se začíná prvním písmenem řetězce, takže se řadí podle jména a teprve potom podle příjmení. Jiné pořadí řazení, než v jakém jsou pole zobrazena, by bylo pouze matoucí.
SELECT "LastName"||', '||"FirstName", "ID"
FROM "Table1"
ORDER BY "LastName"||', '||"FirstName";
To nyní vede k řazení, které lépe odpovídá běžným zvyklostem. Členové rodiny se objevují společně, jeden pod druhým; různé rodiny se stejným příjmením se však prolínají. Abychom je mohli rozlišit, museli bychom je v tabulce seskupit jinak.
Je tu ještě jeden problém: pokud mají dva lidé stejné příjmení a jméno, stejně je nelze rozlišit. Jedním z řešení by mohlo být použití přípony jména. Ale představme si, jak by to vypadalo, kdyby na pozdravu stálo Pan "Müller II"!
SELECT "LastName"||', '||"FirstName"||' - ID:'||"ID", "ID"
FROM "Table1"
ORDER BY "LastName"||', '||"FirstName"||"ID";
Zde jsou všechny záznamy rozlišitelné. Ve skutečnosti se zobrazí "LastName, FirstName – ID:ID hodnota". Například osoba jménem Heinrich Müller s ID 1 se zobrazí jako „Müller, Heinrich – ID: 1“.
Ve formuláři pro výpůjčky se v seznamu zobrazí pouze média, která ještě nebyla vypůjčena. Vytváří se pomocí následujícího SQL příkazu:
SELECT "Title" || ' - Nr. ' || "ID", "ID"
FROM "Media"
WHERE "ID" NOT IN
(SELECT "Media_ID"
FROM "Loan"
WHERE "Return_Date" IS NULL)
ORDER BY "Title" || ' - Nr. ' || "ID" ASC
Je důležité, aby toto pole se seznamem bylo vždy aktualizováno, pokud je médium v něm zapůjčeno.
Následující pole se seznamem na obrázku 37 zobrazuje obsah několika polí v tabulkové podobě tak, že prvky, které patří k sobě, jsou přímo pod sebou.
Obrázek 37: Příklad pole se seznamem
Aby takové zobrazení fungovalo, musíme nejprve zvolit vhodné písmo s pevnou šířkou. Zde lze použít Courier nebo jiné bezpatkové písmo, například Liberation Mono. Tabulkový formulář vytvoříte pomocí kódu SQL:
SELECT
LEFT("Stock"||SPACE(25),25) || ' - ' ||
RIGHT(SPACE(8)||"Price",8) || ' €',
"ID"
FROM "Stock"
ORDER BY ("Stock" || ' - ' || "Price" || ' $') ASC
Obsah pole Stock byl doplněn mezerami tak, aby celý řetězec měl minimální délku 25 znaků. Poté se tam umístí prvních 25 písmen a přebytek se odstřihne.
Situace se komplikuje, pokud obsah pole seznamu obsahuje netisknutelné znaky, jako jsou nové řádky. Pak je třeba kód upravit takto:
SELECT
LEFT(REPLACE("Stock",CHAR(10),' ')||SPACE(25), 25) || ' - ' || ...
Tím se v systému Linux nahradí nový řádek mezerou. V systému Windows musíme navíc odstranit návrat kurzoru na začátek řádku (CHAR(13)).
Počet potřebných mezer lze také určit na základě jednotlivých dotazů. Tím se zabrání náhodnému zkrácení hodnoty „Stock“.
SELECT
LEFT("Stock"||SPACE((SELECT MAX(LENGTH("Stock")) FROM "Stock")), (SELECT MAX(LENGTH("Stock")) FROM "Stock"))|| ' - ' ||
RIGHT(' '||"Price",8) || ' €',
"ID"
FROM "Stock"
ORDER BY ("Stock" || ' - ' || "Price" || ' $') ASC
Protože se cena má zobrazovat vpravo, je vlevo doplněna mezerami a umístěna maximálně osm znaků zprava. Vybrané zobrazení bude fungovat pro všechny ceny do $ 99999,99.
Pokud chceme v jazyce SQL nahradit desetinnou tečku čárkou, budeme potřebovat další kód:
REPLACE(RIGHT(' '||"Price",8),'.',',')
Pokud chceme, aby formulář zobrazoval další informace, které by jinak nebyly viditelné, máme k dispozici různé možnosti dotazů. Nejjednodušší je získat tyto informace pomocí nezávislých dotazů a výsledky vložit do formuláře. Nevýhodou této metody je, že změny v záznamech mohou ovlivnit výsledek dotazu, ale tyto změny se automaticky nezobrazují.
Tabulka 1 je příkladem z oblasti skladového hospodářství pro jednoduchou pokladnu.
Tabulka pokladny obsahuje součty a cizí klíče pro skladové položky a číslo příjemky. Zákazník má jen velmi málo informací, pokud na účtence není vytištěn žádný další výsledek dotazu. Koneckonců, položky jsou identifikovány pouze načtením čárového kódu. Bez dotazu se zobrazí pouze formulář:
Tabulka 1: Počet položek pro každý čárový kód
|
Celkem |
Čárový kód |
|
3 |
17 |
|
2 |
24 |
To, co se skrývá za čísly, nelze zviditelnit pomocí pole se seznamem, protože cizí klíč se zadává přímo pomocí čárového kódu. Stejně tak není možné použít pole se seznamem vedle položky, aby se zobrazovala alespoň jednotková cena.
Zde může pomoci dotaz.
SELECT "Checkout"."Receipt_ID", "Checkout"."Total", "Stock"."Item", "Stock"."Unit_Price", "Checkout"."Total"*"Stock"."Unit_price" AS "Total_Price"
FROM "Checkout", "Stock"
WHERE "Stock"."ID" = "Checkout"."Item_ID";
Nyní po zadání informací alespoň víme, kolik je třeba zaplatit za 3 * Item'17'. Kromě toho je třeba ve formuláři filtrovat pouze informace relevantní pro příslušné Receipt_ID. Stále chybí to, co musí zákazník celkově zaplatit.
SELECT "Checkout"."Receipt_ID", SUM("Checkout"."Total"*"Stock"."Unit_price") AS "Sum"
FROM "Checkout", "Stock"
WHERE "Stock"."ID" = "Checkout"."Item_ID"
GROUP BY "Checkout"."Receipt_ID";
Formulář navrhneme tak, aby zobrazoval vždy jeden záznam dotazu. Protože je dotaz seskupen podle Receipt_ID, formulář zobrazuje informace vždy o jednom zákazníkovi.
Tip
Pokud formulář potřebuje zobrazit hodnoty data, které závisí na jiném datu (například výpůjční doba média může být 21 dní, takže jaké je datum vrácení?), nelze použít vestavěné funkce HSQLDB. Funkce „DATEADD“ neexistuje.
Dotaz
SELECT "Date", DATEDIFF('dd','1899-12-30',"Date")+21 AS "ReturnDate" FROM "Table"
poskytne správné cílové datum pro vrácení ve formuláři. Tento dotaz počítá dny od 30.12.1899. Jedná se o výchozí datum, které Calc používá také jako nulovou hodnotu.
Vrácená hodnota je však pouze číslo, nikoli datum, které lze použít v dalším dotazu.
Vrácené číslo není vhodné pro použití v dotazech, protože formátování dotazů se neukládá. Místo toho je třeba vytvořit zobrazení.
Abychom mohli provádět záznamy do dotazu, který vyvolává pouze jednu tabulku, musí být přítomen primární klíč tabulky, která je základem dotazu, jak je znázorněno na obrázku 38.
Obrázek 38: Podmínky pro to, aby byl dotaz editovatelný
Při půjčování médií nemá smysl vystavovat předměty, které již byly před časem vráceny.
SELECT "ID", "Reader_ID", "Media_ID", "Loan_Date"
FROM "Loan"
WHERE "Return_Date" IS NULL;
Formulář tak může v rámci kontrolního pole tabulky zobrazit vše, co si konkrétní čtenář v průběhu času vypůjčil. I zde musí dotaz filtrovat pomocí příslušné struktury formuláře (čtenář v hlavním formuláři, dotaz v podformuláři), aby se zobrazovala pouze média, která jsou skutečně vypůjčena. Dotaz je vhodný pro zadávání dat, protože je v něm obsažen primární klíč.
Pokud se dotaz skládá z více než jedné tabulky, je možné jej upravovat, pokud jsou přítomny primární klíče všech tabulek a k tabulkám se nepřistupuje prostřednictvím aliasu.
Obrázek 39: Příklad upravitelného dotazu zahrnujícího dvě tabulky
SELECT "Media"."ID", "Media"."Title", "Media"."Category_ID", "Category"."ID" AS "katID", "Category"."Category"
FROM "Media", "Category"
WHERE "Media"."Category_ID" = "Category"."ID";
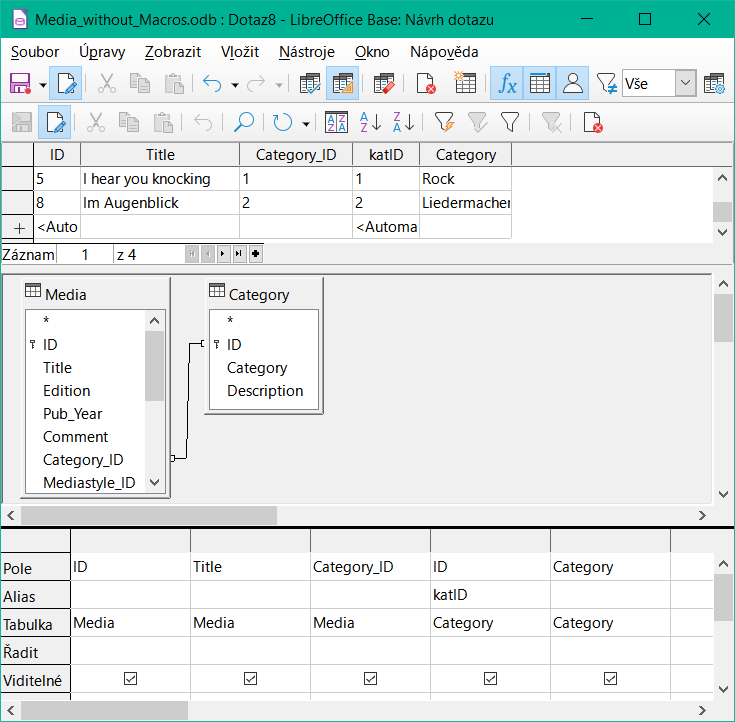
Dotaz na obrázku 39 je upravitelný, protože jsou v něm zahrnuty oba primární klíče a lze k nim přistupovat v tabulkách bez použití aliasu. Dotaz, který spojuje několik tabulek dohromady, rovněž vyžaduje přítomnost všech primárních klíčů.
V dotazu, který zahrnuje několik tabulek, není možné změnit pole cizího klíče v jedné tabulce, které odkazuje na záznam v jiné tabulce. V záznamu na obrázku 40 byl proveden pokus o změnu kategorie pro titul „The Little Hobbit“. Pole Category_ID bylo změněno z 0 na 2. Zdálo se, že změna proběhla a nová kategorie se objevila v záznamu. Ukázalo se však, že ji nelze uložit.
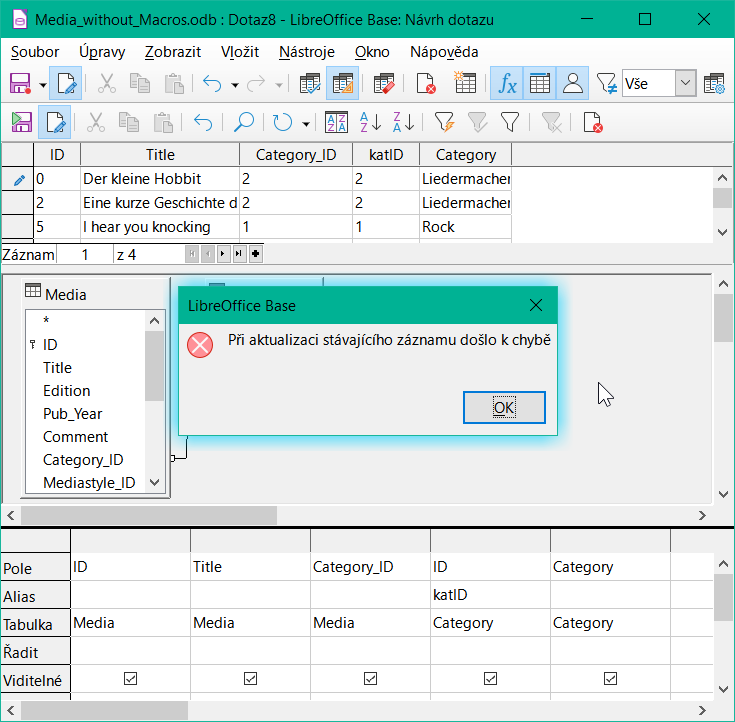
Obrázek 40: Chyba, když upravený dotaz nelze uložit
Je však možné upravit obsah příslušného záznamu kategorie, například nahradit „Fantasie“ za „Fantasy“. Název kategorie se pak změní pro všechny záznamy, které jsou s touto kategorií propojeny.
SELECT "m"."ID", "m"."Title", "Category"."Category", "Category"."ID" AS "katID"
FROM "Media" AS "m", "Category"
WHERE "m"."Category_ID" = "Category"."ID";
V tomto dotazu se k tabulce Media přistupuje pomocí aliasu. Dotaz nelze upravovat. V tomto případě je jedno, zda je primární klíč v dotazu přítomen, nebo ne.
Ve výše uvedeném příkladu se tomuto problému snadno vyhneme. Pokud však použijeme korelovaný poddotaz (viz strana 1), musíme použít alias tabulky. Dotaz je v tomto případě upravitelný pouze tehdy, pokud obsahuje pouze jednu tabulku v hlavním dotazu.
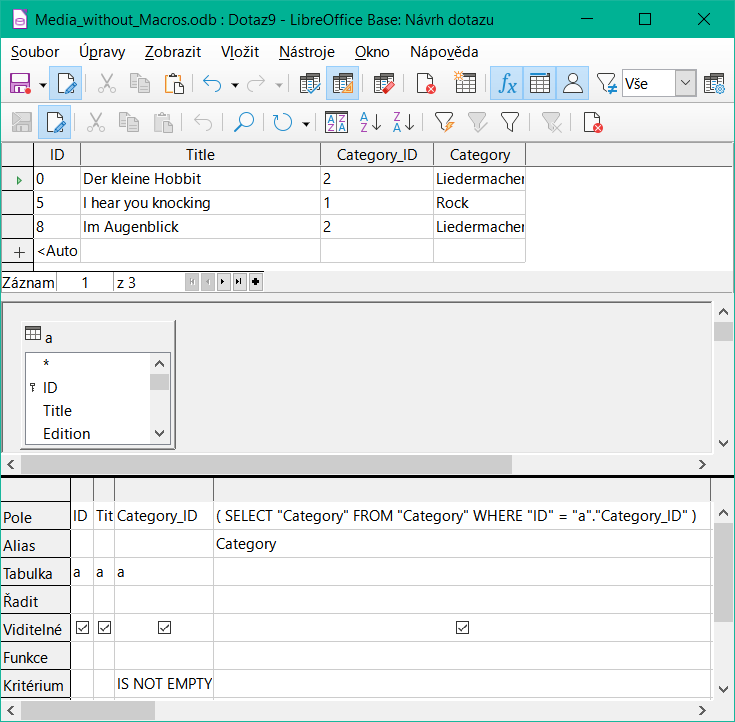
Obrázek 41: Upravitelný dotaz pomocí korelovaného poddotazu s aliasem
V režimu zobrazení na obrázku 41 se zobrazí pouze jedna tabulka. Tabulce Media je přidělen alias, aby bylo možné přistupovat k obsahu pole Category_ID pomocí souvisejícího poddotazu.
V takovém dotazu je nyní možné změnit pole cizího klíče Category_ID na jinou kategorii. Ve výše uvedeném příkladu se pole Category_ID změní z 0 na 2. Titul „The Little Hobbit“ je tedy zařazen do kategorie „Songwriter“.
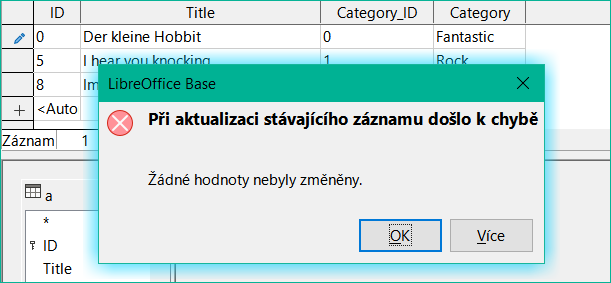
Obrázek 42: Chyba při pokusu o změnu hodnoty v poli korelovaného poddotazu
Není však již možné změnit hodnotu v poli, které získalo svůj obsah prostřednictvím souvisejícího poddotazu. Pokus o změnu kategorie z „Fantasy“ na „Fantastic“ je znázorněn na obrázku 42. Tato změna není zaregistrována a nelze ji ani uložit. V tabulce, která se zobrazí v zobrazení návrhu, není pole Category přítomno.
Pokud často používáme stejný základní dotaz, ale pokaždé s jinými hodnotami, můžeme použít dotazy s parametry. Dotazy s parametry fungují v zásadě stejně jako dotazy pro dílčí formulář:
SELECT "ID", "Reader_ID", "Media_ID", "Loan_Date"
FROM "Loan"
WHERE "Return_Date" IS NULL AND "Reader_ID"=2;
Tento dotaz zobrazuje pouze média půjčená čtenáři s číslem 2.
SELECT "ID", "Reader_ID", "Media_ID", "Loan_Date"
FROM "Loan"
WHERE "Return_Date" IS NULL AND "Reader_ID" =: Readernumber;
Nyní se při spuštění dotazu zobrazí vstupní pole. Vyzve nás k zadání čísla čtenáře. Ať už zde zadáme jakoukoli hodnotu, zobrazí se média, která jsou pro daného čtenáře aktuálně vypůjčena.
SELECT
"Loan"."ID",
"Reader"."LastName"||', '||"Reader"."FirstName",
"Loan"."Media_ID",
"Loan"."Loan_date"
FROM "Loan", "Reader"
WHERE "Loan"."Return_Date" IS NULL
AND "Reader"."ID" = "Loan"."Reader_ID"
AND "Reader"."LastName" LIKE '%' ||: Readername || '%'
ORDER BY "Reader"."LastName"||', '||"Reader"."FirstName" ASC;
Tento dotaz je zjevně uživatelsky přívětivější než předchozí. Číslo čtenáře již není nutné znát. Stačí zadat část příjmení a zobrazí se všechna média, která jsou půjčena odpovídajícím čtenářům.
Pokud vyměníme
"Reader"."LastName" LIKE '%' || :Readername || '%'
za
LOWER("Reader"."LastName") LIKE '%' || LOWER(: Readername) || '%'
Již nezáleží na tom, zda je jméno zadáno velkými nebo malými písmeny.
Pokud by parametr ve výše uvedeném dotazu zůstal prázdný, všechny verze LibreOffice až do verze 4.4 by zobrazily všechny čtenáře, protože pouze ve verzi 4.4 se prázdné pole parametru čte jako NULL, nikoli jako prázdný řetězec. Pokud toto chování nechceme, musíme mu zabránit pomocí triku:
LOWER ("Reader"."LastName") LIKE '%' || IFNULL(NULLIF (LOWER (:Readername), ''), '§§' ) || '%'
Pole prázdného parametru vrací do dotazu prázdný řetězec, nikoli NULL. Proto musí být prázdnému poli parametru přiřazena vlastnost NULL pomocí NULLIF. Pak, protože položka parametru nyní dává hodnotu NULL, lze ji resetovat na hodnotu, která se normálně nevyskytuje v žádném záznamu. Ve výše uvedeném příkladu je to '$$'. Tuto hodnotu samozřejmě ve vyhledávání nenajdeme.
Od verze 4.4 jsou nutné úpravy této techniky dotazování:
LOWER ("Reader"."LastName") LIKE '%' || LOWER (:Readername) || '%'
musí v případě neexistence záznamu nevyhnutelně vést ke kombinaci:
'%' || LOWER (:Readername) || '%' a the NULL value.
Abychom tomu zabránili, přidáme další podmínku, že pro prázdné pole se skutečně zobrazí všechny hodnoty:
(LOWER ("Reader"."LastName") LIKE '%' || LOWER (:Readername) || '%' OR: Readername IS NULL)
Celou věc je třeba dát do závorek. Pak se buď hledá jméno, nebo pokud je pole prázdné (NULL z LibreOffice 4.4), použije se druhá podmínka.
Při použití formulářů lze parametr předat z hlavního formuláře do podformuláře. Někdy se však stává, že se dotazy s parametry v dílčích formulářích neaktualizují, pokud jsou data změněna nebo nově zadána.
Často by bylo vhodné měnit obsah polí se seznamem pomocí nastavení v hlavním formuláři. Mohli bychom například zabránit půjčování médií v knihovně osobám, které mají v současné době zakázáno si média půjčovat. Ovládání nastavení seznamu tímto personalizovaným způsobem pomocí parametrů není možné.
Poddotazy zabudované do polí mohou vždy vrátit pouze jeden záznam. Pole může také vracet pouze jednu hodnotu.
SELECT "ID", "Income", "Expenditure",
( SELECT SUM( "Income" ) - SUM( "Expenditure" )
FROM "Checkout") AS "Balance"
FROM "Checkout";
Tento dotaz umožňuje zadávání dat (včetně primárního klíče). Dílčí dotaz poskytuje přesně jedna hodnotu, a to celkový zůstatek. To umožňuje po každém zadání odečíst zůstatek na pokladně. To ještě není srovnatelné s formulářem pokladny supermarketu popsaným v části „Dotazy jako základ pro další informace ve formulářích“ na straně 1. Samozřejmě chybí jednotlivé výpočty Total * Unit_price, ale také přítomnost čísla účtenky. Uvádí se pouze celkový součet. Pomocí parametru dotazu lze uvést alespoň číslo účtenky:
SELECT "ID", "Income", "Expenditure",
( SELECT SUM( "Income" ) - SUM( "Expenditure" )
FROM "Checkout"
WHERE "Receipt_ID" = :Receipt_Number) AS "Balance"
FROM "Checkout" WHERE "Receipt_ID" =: Receipt_Number;
V dotazu s parametry musí být parametr v obou příkazech dotazu stejný, pokud má být rozpoznán jako parametr.
U podformulářů lze tyto parametry zahrnout. Podformulář pak místo názvu pole obdrží odpovídající název parametru. Tento odkaz lze zadat pouze ve vlastnostech podformuláře, nikoli při použití Průvodce.
Poznámka
Dílčí formuláře založené na dotazech nejsou automaticky aktualizovány na základě jejich parametrů. Vhodnější je předávat parametr přímo z hlavního formuláře.
Pomocí ještě dokonalejšího dotazu, editovatelného dotazu, můžeme dokonce přenášet průběžný zůstatek pokladny:
SELECT "ID", "Income", "Expenditure",
( SELECT SUM( "Income" ) - SUM( "Expenditure" )
FROM "Checkout"
WHERE "ID" <= "a"."ID" ) AS "Balance"
FROM "Checkout" AS "a"
ORDER BY "ID" ASC
Tabulka Checkout je stejná jako tabulka "a". "a" však poskytuje pouze vztah k aktuálním hodnotám v tomto záznamu. Tímto způsobem lze v rámci poddotazu vyhodnotit aktuální hodnotu ID z vnějšího dotazu. V závislosti na ID se tedy určí předchozí zůstatek v příslušném čase, pokud vycházíme z toho, že ID, které je automatická hodnota, se zvyšuje samo o sobě.
Poznámka
Pokud má být obsah poddotazu filtrován pomocí funkce filtru editoru dotazů, funguje to v současné době pouze tehdy, pokud na začátku a na konci poddotazu použijeme dvojité závorky místo jednoduchých: ((SELECT ....)) AS "Saldo"
Dotazem je nutné nastavit zámek proti všem čtenářům, kteří obdrželi třetí oznámení o zpoždění pro médium.
SELECT "Loan"."Reader_ID", '3rd Overdue – the reader is blacklisted' AS "Lock"
FROM
(SELECT COUNT( "Date" ) AS "Total_Count", "Loan_ID"
FROM "Recalls" GROUP BY "Loan_ID") AS "a",
"Loan"
WHERE "a"."Loan_ID" = "Loan"."ID" AND "a"."Total_Count" > 2
Nejprve prozkoumejme vnitřní dotaz, ke kterému se vnější dotaz vztahuje. V tomto dotazu se zjišťuje počet záznamů data seskupených podle cizího klíče Loan_ID. To nesmí být závislé na Reader_ID, protože by se tak započítávala nejen tři oznámení o zpoždění pro jedno médium, ale také tři média, každé s jedním oznámením o zpoždění. Vnitřnímu dotazu je přidělen alias, aby mohl být propojen s identifikátorem Reader_ID z vnějšího dotazu.
Vnější dotaz se v tomto případě vztahuje pouze k podmíněnému vzorci z vnitřního dotazu. Zobrazuje pouze Reader_ID a text pro pole Lock, pokud se "Loan". "ID" a "a". "Loan_ID" rovnají a "a". "Total_Count" > 2.
V zásadě jsou všechna pole vnitřního dotazu dostupná vnějšímu dotazu. Takže například součet "a". "Total_Count" může být sloučen do vnějšího dotazu, aby se získal skutečný součet pokut.
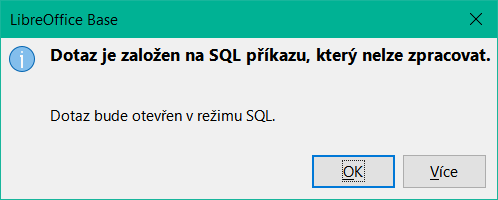
V dialogovém okně Návrh dotazu se však může stát, že po takové konstrukci již nebude režim zobrazení návrhu fungovat. Pokud se pokusíme dotaz znovu otevřít pro úpravy, zobrazí se upozornění na obrázku 43:
Obrázek 43: Chyba při pokusu o otevření dotazu, který nelze otevřít v režimu návrhu
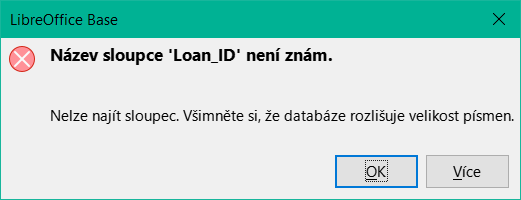
Pokud pak otevřeme dotaz k úpravám v režimu SQL a pokusíme se z něj přepnout do režimu Návrh, zobrazí se chybová zpráva na obrázku 44:
Obrázek 44: Chyba při nemožnosti přepnout z režimu SQL do zobrazení návrhu
V režimu zobrazení návrhu nelze najít pole obsažené ve vnitřním dotazu "Loan_ID", kterým se řídí vztah mezi vnitřním a vnějším dotazem.
Při spuštění dotazu v režimu SQL se odpovídající obsah poddotazu reprodukuje bez chyby. Proto v tomto případě nemusíme používat přímý režim SQL.
Vnější dotaz použil výsledky vnitřního dotazu k vytvoření konečných výsledků. Jedná se o seznam hodnot "Loan_ID", které by měly být uzamčeny a proč. Pokud chceme konečné výsledky dále omezit, použijeme funkce řazení a filtrování v grafickém uživatelském rozhraní.
Následující snímky obrazovky ukazují, jakými různými způsoby lze dojít k výsledku dotazu s poddotazy. Zde se dotaz do skladové databáze snaží zjistit, co má zákazník zaplatit u pokladny. Jednotlivé ceny se vynásobí počtem zakoupených položek a získá se mezisoučet. Pak je třeba určit součet těchto dílčích součtů. To vše musí být možné upravovat, aby bylo možné dotaz použít jako základ formuláře.
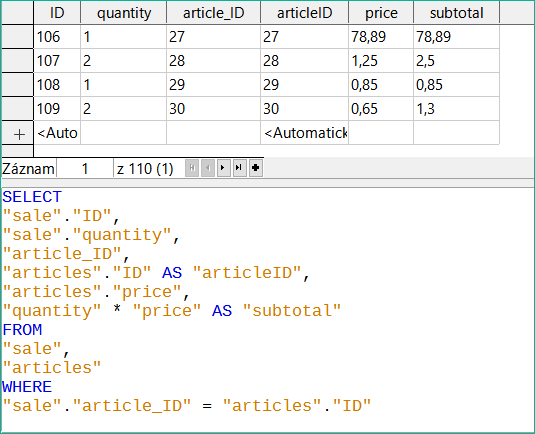
Obrázek 45: Jednoduchý dotaz pro vytvoření mezisoučtů
Dotaz znázorněný na obrázku 45 používá dvě tabulky (sale and articles). Aby bylo možné dotaz upravovat, musí být zahrnuty oba primární klíče.
Poznámka
Kvůli chybě 61871 aplikace Base neaktualizuje dílčí výsledek automaticky.
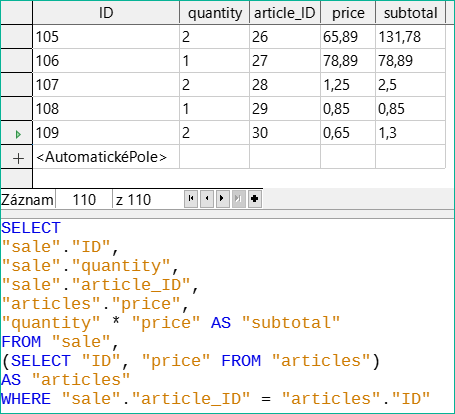
Obrázek 46: Tabulka článků je přesunuta do poddotazu
Na obrázku 46 je tabulka articles přesunuta do poddotazu, který je vytvořen v oblasti tabulky (za výrazem „FROM“) a je mu přidělen alias. Nyní již není primární klíč tabulky articles nezbytně nutný k tomu, aby byl dotaz editovatelný.
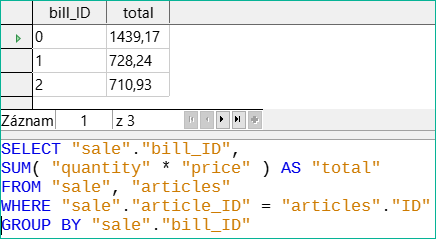
Obrázek 47: Výpočet hodnoty prodeje podle bill_id
Na obrázku 47 se v dotazu musí objevit vypočtená částka. Již jednoduchý dotaz pro výpočet součtu není editovatelný, takže je zde seskupen a sečten.
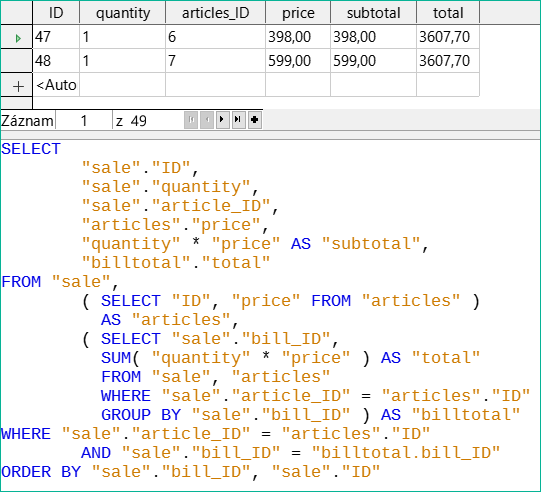
Obrázek 48: Použití dvou poddotazů
Na obrázku 48 se druhým poddotazem stane zdánlivě nemožné možným. Předchozí dotaz je vložen jako poddotaz do definice tabulky hlavního dotazu (za „FROM“). Celý dotaz tak zůstává upravitelný. V tomto případě je možné provádět záznamy pouze ve sloupcích „Sum“ a „WarID“. To je následně jasně uvedeno ve formuláři dotazu.
Při vyhledávání dat v celé databázi vede použití jednoduchých formulářových funkcí často k problémům. Formulář se koneckonců vztahuje pouze k jedné tabulce a vyhledávací funkce prochází pouze podkladové záznamy tohoto formuláře.
Získání všech dat je jednodušší, pokud používáme dotazy, které mohou poskytnout obraz o všech záznamech. V části „Definice relace v dotazu“ je navržena taková konstrukce dotazu. Ten je pro ukázkovou databázi vytvořen takto:
SELECT "Media"."Title", "Subtitle"."Subtitle", "Author"."Author"
FROM "Media"
LEFT JOIN "Subtitle"
ON "Media"."ID" = "Subtitle"."Media_ID"
LEFT JOIN "rel_Media_Author"
ON "Media"."ID" = "rel_Media_Author"."Media_ID"
LEFT JOIN "Author"
ON "rel_Media_Author"."Author_ID" = "Author"."ID"
Zde jsou všechny tituly (Titles), podtituly (Subtitles) a autoři (Authors) zobrazeni společně.
Tabulka Media obsahuje celkem 9 titulů. U dvou z těchto titulů je k dispozici celkem 8 podtitulů. Bez spojení LEFT JOIN se v obou tabulkách zobrazí dohromady pouze 8 záznamů. Pro každý podtitul se vyhledá odpovídající název a tím dotaz končí. Tituly bez podtitulů se nezobrazují.
Nyní se zobrazí všechna média včetně těch bez podtitulů: hodnota pole Media je na levé straně zadání, Subtitles na pravé straně. LEFT JOIN zobrazí všechny hodnoty Title z tabulky Media, ale hodnoty Subtitle pouze pro ty, které mají hodnotu Title. Tabulka Media se stává rozhodující tabulkou pro určení, které záznamy se mají zobrazit. To bylo plánováno již při sestavování tabulky (viz kapitola 3, Tabulky). Protože pro dva z devíti titulů existují podtituly, dotaz nyní zobrazí 9 + 8 – 2 = 15 záznamů.
Poznámka
Běžné propojení tabulek po vypsání všech tabulek následuje po klíčovém slově WHERE.
V případě spojení LEFT JOIN nebo RIGHT JOIN se přiřazení definuje přímo za názvy obou tabulek pomocí ON. Pořadí je tedy vždy
Tabulka1 LEFT JOIN Tabulka2 ON Tabulka1.Pole1 = Tabulka2.Pole1 LEFT JOIN Tabulka3 ON Tabulka2.Pole1 = Tabulka3.Pole1...
Dva tituly v tabulce Media zatím nemají položku Author nebo Subtitle. Zároveň má jeden titul celkem tři autory. Pokud je tabulka Author propojena bez spojení LEFT JOIN, nezobrazí se dvě Media bez autora. Protože však jedno médium má tři autory místo jednoho, celkový počet zobrazených záznamů bude stále 15.
Pouze pomocí spojení LEFT JOIN bude dotaz instruován, aby použil tabulku Media k určení záznamů, které se mají zobrazit. Nyní se opět objeví záznamy bez hodnoty Subtitle nebo Author, celkem tedy 17 záznamů.
Použití vhodných spojů obvykle zvyšuje množství zobrazených dat. Tento rozšířený soubor dat lze však snadno skenovat, protože kromě názvů se zobrazují i autoři a podtituly. V ukázkové databázi lze přistupovat ke všem tabulkám závislým na médiích.
Pohledy v SQL jsou rychlejší než dotazy, zejména pro externí databáze, protože jsou ukotveny přímo v databázi a server vrací pouze výsledky. Naproti tomu dotazy jsou nejprve odeslány na server a tam zpracovány.
Pokud se nový dotaz vztahuje k jinému dotazu, režim SQL v databázi Base vytvoří z jiného dotazu tabulku. Pokud z něj vytvoříte View, uvidíte, že ve skutečnosti pracujete s poddotazem (Select použitý v rámci jiného Selectu). Z tohoto důvodu nelze Query 2, který se vztahuje k jinému Query 1, spustit přímo pomocí příkazu Edit > Spustit SQL, protože o Query 1 ví pouze grafické uživatelské rozhraní, a nikoli samotná databáze.
Databáze neumožňuje přímý přístup k dotazům. To platí i pro přístup pomocí maker. Naproti tomu k pohledům lze přistupovat jak z maker, tak z tabulek. V zobrazení však nelze upravovat žádné záznamy. (Musí být upraveny v tabulce nebo formuláři.)
Tip
Dotaz vytvořený pomocí funkce Vytvořit dotaz v režimu SQL má tu nevýhodu, že jej nelze řadit ani filtrovat pomocí grafického uživatelského rozhraní. Jeho použití je proto omezeno.
Naproti tomu Pohledy lze spravovat v aplikaci Base stejně jako běžnou tabulku – s tím rozdílem, že není možné měnit data. Zde jsou tedy i v přímých příkazech SQL k dispozici všechny možnosti řazení a filtrování.
Kromě toho se formátování sloupců v pohledu zachovává i po uzavření databáze, na rozdíl od sloupců v dotazu.
Pohledy jsou řešením mnoha dotazů, pokud chceme vůbec získat nějaké výsledky. Pokud se má například na výsledky dotazu použít podvýběr, vytvořte Pohled, který vám tyto výsledky poskytne. Poté použijeme dílčí výběr v okně Pohled. Odpovídající příklady najdeme v kapitole 8, Úlohy databáze.
Vytvoření pohledu z dotazu je poměrně snadné a přímočaré.
Klepneme na objekt Tabulka v části Databáze.
Klepneme na Vytvořit pohled.
Zavřeme dialogové okno Přidat tabulku.
Klepneme na ikonu Režim návrh zap/vyp. (Jedná se o režim SQL pro Pohled.)
Získání SQL pro Pohled:
Upravíme dotaz v režimu SQL.
Pomocí Control+A zvýrazníme SQL dotaz.
Pomocí Control+C zkopírujeme SQL.
V zobrazení režimu SQL použijeme klávesy Control+V pro vložení SQL.
K výpočtu hodnot se používají také dotazy. Někdy interní databáze HSQLDB vykazuje zdánlivé chyby, které se při bližším zkoumání ukáží jako logicky správné interpretace dat. Objevují se také problémy se zaokrouhlováním, které mohou snadno způsobit zmatek.
Časy v HSQLDB jsou správně formátovány pouze do rozdílu 23:59:59 hodin. Pokud je třeba sečíst více časů, například pro výpočet odpracovaných hodin, je třeba najít jiný způsob. Zde existuje několik složitých přístupů:
Čas se přímo vyjadřuje pouze v součtu minut nebo dokonce sekund. Výhoda: hodnoty umožňují následný bezproblémový výpočet.
Čas je rozdělen na části hodiny, minuty a sekundy a znovu sestaven jako text s použitím znaku ':' jako oddělovače. Výhoda: text se v dotazech od začátku zobrazuje jako správně naformátovaný čas.
Čas je vytvořen jako desetinné číslo. Den je 1, hodina je 1/24 atd. Výhoda: hodnoty lze následně v dotazu přeformátovat na čas a prezentovat je jako formátovatelné formulářové pole.
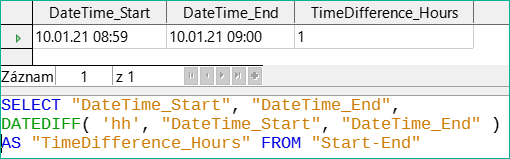
Obrázek 49: Použití funkce DATEDIFF pro výpočet časového rozdílu v hodinách
Funkce DATEDIFF umožňuje určit časové intervaly. Výslovně se ptá na rozdíl, který má být určen. V příkladu na obrázku 49 nebyly požadovány minuty, ale jsou zohledněny všechny prvky, které jsou delší než minuta. Rozdíl mezi 8:59 a 9:00 je tedy jedna hodina (!). Naproti tomu rozdíl dat se počítá jako časový rozdíl v hodinách. Pokud je například pole Date_time_end nastaveno na 2.10.14 09:00, je to počítáno jako 25 hodin.
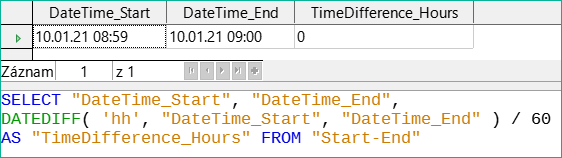
Obrázek 50: Vypočítáme časový rozdíl v minutách a vydělíme jej 60.
Pokud se místo toho časový interval vypočítá v minutách a poté se vydělí 60, časový rozdíl v hodinách se stane nulovým, jak je znázorněno na obrázku 50. Tohle vypadá spíš jako správná hodnota, až na to, kam se poděla ta jedna minuta?
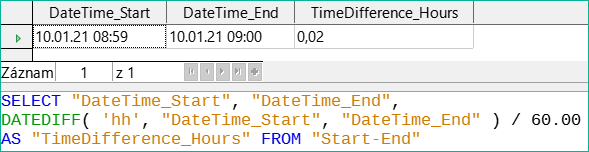
Obrázek 51: Vypočítáme časový rozdíl v minutách a vydělíme jej číslem 60,00.
Na obrázku 51 je časový interval zadán jako celé číslo. Celé číslo bylo děleno celým číslem. Výsledkem dotazu musí být i v těchto případech celé, nikoli desetinné číslo. To lze snadno opravit. Časový rozdíl v minutách se vydělí desetinným číslem se dvěma desetinnými místy (60,00). Výsledek má rovněž dvě desetinná místa. 0,02 hodiny stále není přesně jedna minuta, ale je jí mnohem blíže než dříve. Počet desetinných míst by bylo možné zvýšit použitím více nul. Perioda 0,016 je ještě bližší přiblížení, ale pozdější chyby ve výpočtu nelze vždy vyloučit.
Místo toho, abychom museli pracovat se spoustou přidaných nul, lze datový typ DATEDIFF ovlivnit přímo. Pomocí (CONVERT(DATEDIFF('mi', "Date_time_start", "Date_time_end"),DECIMAL(50,49)))/60 lze dosáhnout přesnosti 49 desetinných míst.
Při používání výpočetních funkcí si musíme vždy uvědomit, že datové typy v HSQLDB mají pouze omezenou přesnost. Ať už použijeme jakýkoli počet desetinných míst, faktem zůstává, že mezilehlé výsledky zahrnující počítání času lze pro další výpočty použít pouze v omezené míře.
Pokud má být časová hodnota následně použita ve formuláři nebo sestavě jako formátovaný čas, musíme zajistit, aby byl den platný jako základ pro formátování času.
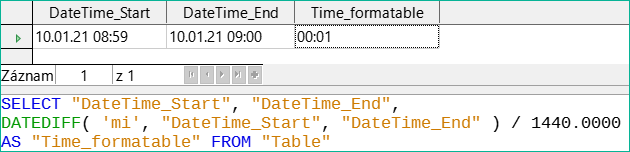
Obrázek 52: Vypočítáme časový rozdíl v minutách a vydělíme jej číslem 1440.0000.
Na obrázku 52 je rozdíl vypočítán v minutách. Výsledek se udává jako zlomek dne. Jeden den má 60 * 24 minut. Pokud bychom jednoduše vydělili 1440, výsledek by byl nula, takže opět musíme explicitně uvést desetinná místa. Pak se zobrazí jako formátovaný čas 0 hodin a 1 minuta.
Kód formátu pro čas delší než jeden den je [HH]:MM. Pokud použijeme nesprávný formát, může se časový rozdíl 1 den a 1 minuta zobrazit pouze jako 1 minuta.
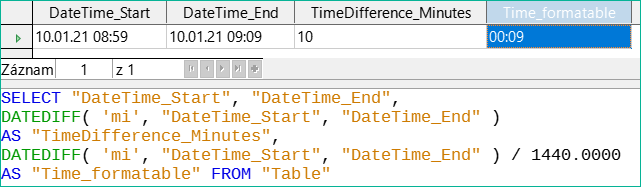
Obrázek 53: Vypočítáme časový rozdíl v minutách kromě časového rozdílu v minutách vyděleného 1440,0000.
Chybový ďábel znovu udeřil! Časový rozdíl 10 minut by se při správném formátování podle obrázku 53 neměl zobrazit jako 9 minut. Abychom zjistili, v čem spočívá problém, musíme se zabývat tím, jak přesně se výpočet provádí:
10/1440 = 0.00694. Výsledek je zaokrouhlen na 0,0069, protože byla zadána pouze čtyři desetinná místa.
0,0069 * 1440 = 9,936 minuty, což je 9 minut 56,16 sekundy. A sekundy se nezobrazují ve zvoleném formátu!
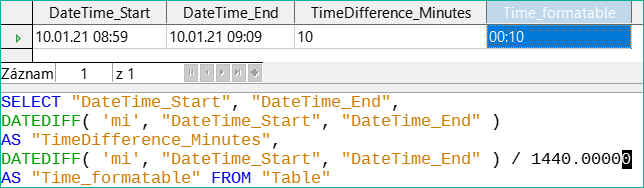
Obrázek 54: Vypočítáme časový rozdíl v minutách kromě časového rozdílu v minutách vyděleného 1440,00000.
Konečně na obrázku 54 prodloužení dělitele o jedno desetinné místo (z 1440,0000 na 1440,00000) tuto chybu vyřeší. Nyní se zaokrouhluje na 0,00694. 0,00694*1440 dává 9,9936, což je 59,616 sekundy. Počet vteřin se zaokrouhluje na 60 vteřin, takže k 9 minutám se přičte 1 minuta, celkem tedy 10 minut.
I zde se mohou vyskytnout další problémy. Mohou existovat další desetinná místa, která při formátování nedávají 1 minutu? K vyřešení tohoto problému může pomoci krátký výpočet pomocí programu Calc s podobně zaokrouhlenými čísly. Sloupec A obsahuje posloupnost čísel od 1 (pro minuty). Sloupec B obsahuje vzorec =ROUND(A1/1440;4) a je formátován tak, aby zobrazoval hodiny a minuty. Pokud budeme pokračovat směrem dolů, uvidíme vedle 10 minut ve sloupci A hodnotu 00:09 ve sloupci B. Podobně pro 28 minut atd. Pokud zaokrouhlíme na 5 míst, tyto chyby zmizí.
Jakkoli by bylo příjemné mít ve formuláři vhodně naformátované zobrazení, je třeba si uvědomit, že se jedná o zaokrouhlené hodnoty, které nejsou vhodné pro další použití při slepých mechanických výpočtech. Pokud je třeba hodnotu použít pro další výpočet, je lepší použít pouze vyjádření časového rozdílu v nejmenších dostupných jednotkách, v tomto případě v minutách.