
Příručka aplikace Base 7.3
Kapitola 6
Sestavy
Tento dokument je chráněn autorskými právy © 2022 týmem pro dokumentaci LibreOffice. Přispěvatelé jsou uvedeni níže. Dokument lze šířit nebo upravovat za podmínek licence GNU General Public License (https://www.gnu.org/licenses/gpl.html), verze 3 nebo novější, nebo the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0/), verze 4.0 nebo novější.
Všechny ochranné známky uvedené v této příručce patří jejich vlastníkům.
|
flywire |
Steve Fanning |
|
|
Robert Großkopf |
Pulkit Krishna |
Jost Lange |
|
Dan Lewis |
Hazel Russman |
Jochen Schiffers |
|
Jean Hollis Weber |
|
|
Jakékoli připomínky nebo návrhy k tomuto dokumentu prosím směřujte do fóra dokumentačního týmu na adrese https://community.documentfoundation.org/c/documentation/loguides/ (registrace je nutná) nebo pošlete e-mail na adresu: loguides@community.documentfoundation.org.
Poznámka
Vše, co napíšete do fóra, včetně vaší e-mailové adresy a dalších osobních údajů, které jsou ve zprávě napsány, je veřejně archivováno a nemůže být smazáno. E-maily zaslané do fóra jsou moderovány.
Vydáno Srpen 2022. Založeno na LibreOffice 7.3 Community.
Jiné verze LibreOffice se mohou lišit vzhledem a funkčností.
Některé klávesové zkratky a položky nabídek jsou v systému macOS jiné než v systémech Windows a Linux. V následující tabulce jsou uvedeny nejdůležitější rozdíly, které se týkají informací v této knize. Podrobnější seznam se nachází v nápovědě aplikace.
|
Windows nebo Linux |
Ekvivalent pro macOS |
Akce |
|
Výběr v nabídce Nástroje > Možnosti |
LibreOffice > Předvolby |
Otevřou se možnosti nastavení. |
|
Klepnutí pravým tlačítkem |
Ctrl + klepnutí a/nebo klepnutí pravým tlačítkem v závislosti na operačním systému počítače |
Otevře se místní nabídka. |
|
Ctrl (Control) |
⌘ (Command) |
Používá se také s dalšími klávesami. |
|
Ctrl + Q |
⌘ + Q |
Ukončí LibreOffice |
Sestavy slouží k prezentaci dat způsobem, který je snadno pochopitelný i lidé bez znalosti databáze. Sestavy mohou:
Prezentovat data v přehledných tabulkách.
Vytvářet grafy pro zobrazení dat.
Umožnit použití dat pro tisk štítků.
Vytvářet formáty dopisů, jako jsou účty, oznámení o odvolání nebo oznámení lidem, kteří vstupují do sdružení nebo z něj vystupují.
Vytvoření sestavy vyžaduje pečlivou přípravu podkladové databáze. Na rozdíl od formuláře nemůže sestava obsahovat dílčí sestavy, a tedy ani další zdroje dat. Ani sestava nemůže prezentovat jiné datové prvky, než které jsou k dispozici v podkladovém zdroji dat, jako to může dělat formulář pomocí polí se seznamem.
Sestavy se nejlépe připravují pomocí dotazů. Tímto způsobem lze určit všechny proměnné. Zejména pokud je v rámci sestavy vyžadováno řazení, vždy použijeme dotaz, který řazení umožňuje. To znamená, že za těchto podmínek je třeba se vyhnout dotazům v přímém režimu SQL. Pokud musíme v databázi použít dotaz tohoto typu, můžeme řazení provést tak, že nejprve vytvoříme z tohoto dotazu pohled. Takové zobrazení lze vždy řadit a filtrovat pomocí grafického uživatelského rozhraní (GUI) aplikace Base.
Upozornění
Při používání nástroje Návrhář sestav bychom měli svou práci během úprav často ukládat. Kromě ukládání v samotném nástroji Návrhář sestav bychom měli po každém významném kroku uložit také celou databázi.
Chceme-li spustit nástroj Návrhář sestav z prostředí aplikace Base, použijeme příkaz Sestavy > Vytvořit sestavu v režimu návrhu.
Úvodní okno nástroje Návrhář sestav (obrázek 1) obsahuje tři části. Vlevo je aktuální rozdělení sestavy na Záhlaví stránky, Podrobnosti a Zápatí stránky, uprostřed jsou příslušné oblasti, do kterých se bude vkládat obsah, a vpravo jsou zobrazeny vlastnosti těchto oblastí.
Současně se zobrazí dialogové okno Přidat pole. Tento dialog odpovídá dialogu při vytváření formuláře. Vytvoří pole s odpovídajícími popisky polí.
Bez obsahu z databáze nemá sestava správnou funkci. Z tohoto důvodu se dialogové okno otevře na kartě Data, kde lze nastavit obsah sestavy. Jako příklad se používá tabulka View_Report_Recall. Pokud je příkaz Analyzovat SQL nastaven na hodnotu Ano, lze sestavu třídit, seskupovat a filtrovat. Jako základ této sestavy byl vybrán pohled, takže nebude použit žádný filtr; ten již byl zahrnut do dotazu, který je základem pohledu.
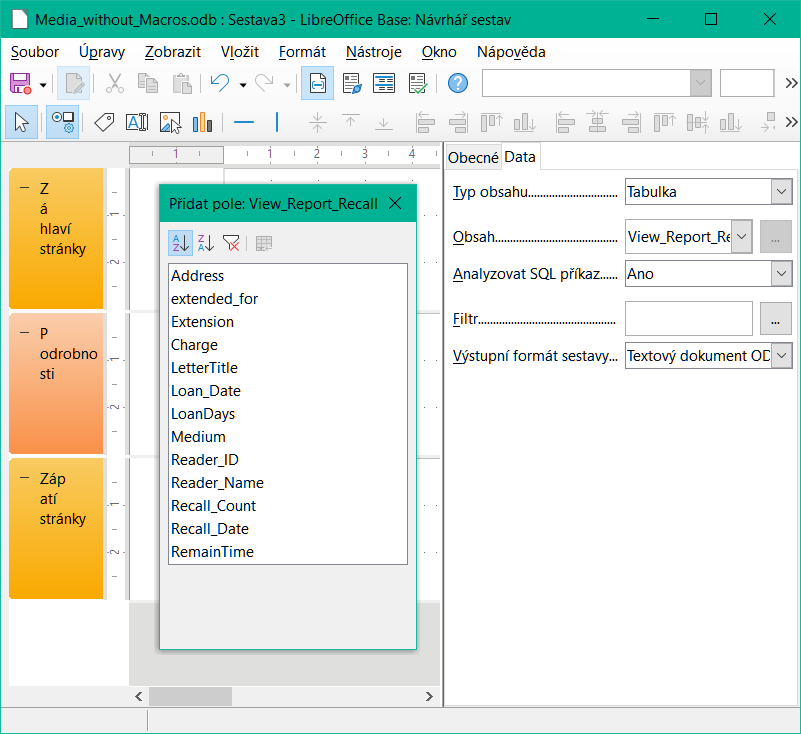
Obrázek 1: Počáteční rozložení okna nástroje Návrhář sestav
Poznámka
Zadaným typem obsahu může být tabulka, pohled, dotaz nebo přímé kódování SQL. Nástroj Návrhář sestav pracuje nejlépe, pokud má k dispozici data, která byla pokud možno předem připravena. Tak lze například předem provést výpočty v dotazech a v případě potřeby omezit rozsah záznamů, které se mají v sestavě objevit.
Na výběr jsou dva výstupní formáty sestav: Textový dokument ODF (dokument Writer) nebo Tabulkový procesor ODF (dokument Calc). Pokud chceme pouze tabulkové zobrazení dat, rozhodně bychom měli pro sestavu zvolit dokument Calc. Jeho vytvoření je výrazně rychlejší a je také snazší jej následně formátovat, protože je třeba zvážit méně možností a sloupce lze snadno přetáhnout na požadovanou šířku.
Ve výchozím nastavení hledá nástroj Návrhář sestav zdroj dat v první tabulce databáze. Tím je zajištěno, že je možné provést alespoň test funkcí. Před tím, než je možné sestavu vybavit poli, je třeba zvolit zdroj dat.
Nástroj Návrhář sestav nabízí mnoho dalších tlačítek, která jsou spolu s popisem zobrazena na obrázcích 2 a 3. Tlačítka pro zarovnání prvků nejsou v této kapitole dále popsána. Jsou užitečná pro rychlou úpravu polí v jedné oblasti nástroje Návrhář sestav, ale v zásadě lze vše provést přímou úpravou vlastností polí.
Obrázek 2: Tlačítka pro úpravu obsahu – Standardní nástrojová lišta (vlevo) a nástrojová lišta Ovládací prvky sestavy (vpravo)

Obrázek 3: Tlačítka pro zarovnání prvků – nástrojové lišty Zarovnat, Změna velikosti objektu, Zarovnat v sekci a Zmenšení v sekci (zleva doprava).
Stejně jako u formulářů je užitečné použít příslušný navigátor. Tak například neopatrné klepnutí na začátku nástroje Návrhář sestav může ztížit nalezení vlastností dat pro sestavu. Taková data mohou být dostupná pouze prostřednictvím navigátoru sestavy. Klepneme levým tlačítkem myši na položku Sestava a vlastnosti sestavy jsou opět přístupné.
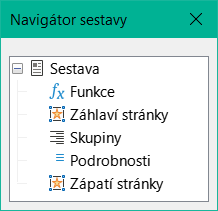
Obrázek 4: Navigátor sestavy
Zpočátku se v navigátoru (viz obrázek 4) zobrazují části sestavy, a to kromě viditelných (Záhlaví stránky, Skupiny, Detail a Zápatí stránky) i neviditelné (Funkce). Skupiny lze použít například k přiřazení všech médií zapůjčených osobě, která si je vypůjčila, aby se předešlo vícenásobnému volání dotazu. Oblasti podrobností zobrazují záznamy patřící do skupiny. Funkce se používají k výpočtům, například k součtům.
Aby bylo možné v příkladu získat užitečný výstup, musí být obsah zobrazení reprodukován s vhodným seskupením. Každý čtenář by měl být propojen s oznámeními o stažení všech svých vypůjčených a nevrácených médií.
Zobrazit > Řazení a seskupení nebo odpovídajícím tlačítkem spustíme funkci seskupování.
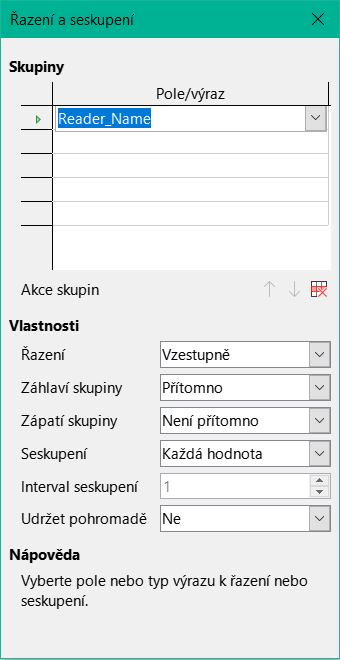
Obrázek 5: Dialogové okno Řazení a seskupení
Zde se seskupování a řazení provádí podle pole Reader_Name. Do výše uvedené tabulky lze zahrnout i další pole. Chceme-li například seskupovat a třídit také podle pole Loan_Date, zvolíme toto pole jako druhý řádek.
Přímo pod tabulkou je k dispozici několik akcí seskupení. Skupinu můžeme přesunout nahoru nebo dolů v seznamu nebo ji úplně odstranit. Vzhledem k tomu, že pro plánovanou sestavu je zapotřebí pouze jedna skupina, je na obrázku 5 zobrazen jako dostupný pouze symbol Odstranit v pravém krajním rohu skupinových akcí.
Vlastnost Řazení je zřejmá.
Po vytvoření položky se v levé části nástroje Návrhář sestav okamžitě zobrazilo nové rozdělení. Vedle popisu pole Reader_Name nyní vidíme položku Header. Tato část je určena pro záhlaví skupiny v sestavě. Záhlaví může obsahovat jméno osoby, která obdrží upomínku k vrácení médií. V tomto případě není zápatí skupiny. Taková patička by mohla obsahovat dlužnou pokutu nebo místo a aktuální datum a prostor pro podpis osoby, která oznámení odesílá.
Ve výchozím nastavení je pro každou hodnotu vytvořena nová skupina. Pokud se tedy změní hodnota pole Reader_Name, založí se nová skupina. Můžeme je také seskupit podle počátečního písmene. V případě upomínky by však všichni čtenáři se stejnou iniciálou byli zařazeni do jedné skupiny. Schmidt, Schulze a Schulte by obdrželi společnou upomínku, což by v tomto příkladu bylo zcela zbytečné.
Při seskupování podle počátečního písmene můžeme navíc určit, o kolik písmen později má začínat další skupina. Lze si představit například seskupení pro malý telefonní seznam. Podle velikosti seznamu kontaktů si lze představit seskupení na každé druhé počáteční písmeno. Takže A a B by tvořily první skupinu, pak C a D a tak dále.
Skupinu lze nastavit buď tak, aby byla vedena společně s prvním oddílem údajů, nebo pokud možno jako kompletní skupina. Ve výchozím nastavení je tato možnost nastavena na hodnotu Ne. Pro oznámení o odvolání bychom pravděpodobně chtěli skupinu uspořádat tak, aby se pro každou osobu, která má obdržet odvolání, vytiskla samostatná stránka. V další nabídce můžeme zvolit, aby za každou skupinou (v tomto případě za každým jménem čtenáře) následoval před zpracováním další hodnoty zlom stránky.
Pokud jsme zvolili záhlaví skupiny a případně i zápatí skupiny, zobrazí se tyto prvky jako sekce v navigátoru sestavy pod odpovídajícím názvem pole Reader_Name. I zde máme možnost používat funkce, které pak budou omezeny na tuto skupinu.
Chceme-li přidat pole, použijeme funkci Přidat pole, stejně jako u formulářů. V tomto případě však popisek a obsah pole nejsou svázány dohromady. Oběma lze nezávisle pohybovat, měnit jejich velikost a přetahovat je do různých částí.
Obrázek 6 zobrazuje návrh sestavy pro oznámení o odvolání. V záhlaví stránky je nadpis Knihovna Libre Office, vložený jako pole s popiskem. Zde můžeme mít také hlavičkový papír s logem, protože může obsahovat grafiku. Tato úroveň se nazývá Záhlaví stránky, ale to neznamená, že nad ní není žádný prostor. To závisí na nastavení stránky; pokud byl nastaven horní okraj, nachází se tento okraj nad záhlavím stránky.
Záhlaví Reader_Name je záhlaví seskupených a seřazených dat. V polích, která mají obsahovat data, jsou názvy příslušných datových polí zobrazeny světle šedou barvou. Tak například zobrazení, které je základem sestavy, má pole s názvem Address, které obsahuje kompletní adresu příjemce s ulicí a městem. Vložení tohoto údaje do jediného pole vyžaduje v dotazu zalomení řádku. K jejich vytvoření můžeme použít CHAR(13)||CHAR(10).
Příklad:
SELECT "Salutation"||CHAR(13)||CHAR(10)||"FirstName"||' '||"LastName"||CHAR(13)||CHAR(10)||"Street"||' '||"No"||CHAR13||CHAR(10)||"Postcode"||' '||"Town" AS "Adress" FROM "Reader"
Pole =TODAY() představuje vestavěnou funkci, která na tuto pozici vloží aktuální datum.
V Záhlaví Reader_Name se kromě pozdravu zobrazují záhlaví sloupců pro následující zobrazení tabulky. Tyto prvky by se měly objevit pouze jednou, i když je v seznamu uvedeno několik médií.
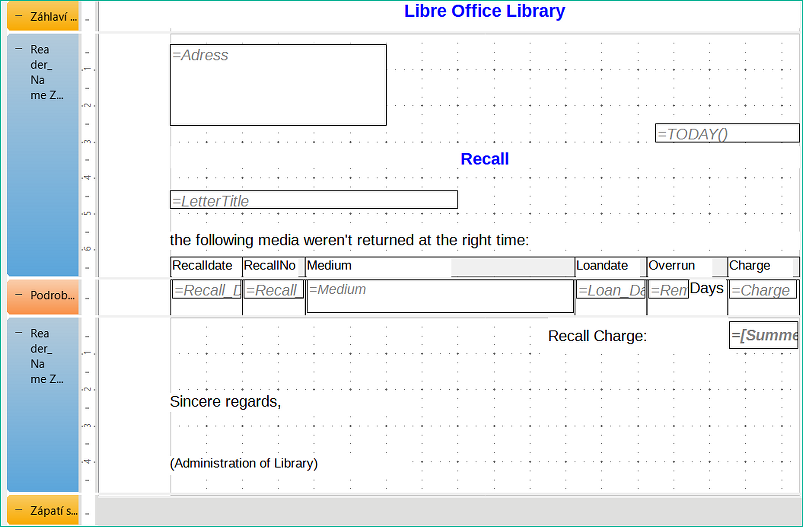
Obrázek 6: Návrh zprávy pro příklad oznámení upomínky
Na pozadí těchto záhlaví sloupců je šedý obdélník, který slouží také jako rámec pro data.
Oblast Podrobnosti se opakuje tolikrát, kolikrát existují samostatné záznamy se stejným údajem Reader_Name. Zde jsou uvedena všechna média, která nebyla vrácena včas. V pozadí je další obdélník, který rámuje obsah. Tento obdélník je vyplněn bílou barvou, nikoli šedou.
Poznámka
LibreOffice v zásadě umožňuje přidávat vodorovné a svislé čáry. Tyto linie mají tu nevýhodu, že jsou interpretovány pouze jako vlasové linie. Lze je lépe reprodukovat, pokud se použijí obdélníky. Nastavíme pozadí obdélníku na černou barvu a jeho velikost například na šířku 17 cm a výšku 0,03 cm. Tím se vytvoří vodorovná čára o tloušťce 0,03 cm a délce 17 cm.
Tato varianta má však také nevýhodu: grafické prvky nelze správně umístit, pokud se oblast rozprostírá na více než jedné stránce.
Zápatí Reader_Name uzavírá dopis pozdravem a prostorem pro podpis. Zápatí je definováno tak, že za touto oblastí dojde k dalšímu zalomení stránky. Na rozdíl od výchozího nastavení je také stanoveno, že tato oblast by měla být ve všech případech pohromadě. Koneckonců by vypadalo poněkud podivně, kdyby více upomínek obsahovalo podpis na samostatné stránce.
Udržet pohromadě zde odkazuje na zalomení stránky. Pokud chceme, aby obsah záznamu zůstal pohromadě nezávisle na zalomení, je to v současné době možné pouze v případě, že záznam není načten jako Podrobnosti, ale je použit jako základ pro seskupení. Můžeme zvolit možnost Udržet pohromadě = Ano, ale nefunguje to; oblast Podrobnosti se oddělí. Abychom udrželi obsah Podrobnosti pohromadě, musíme jej zařadit do samostatné skupiny.
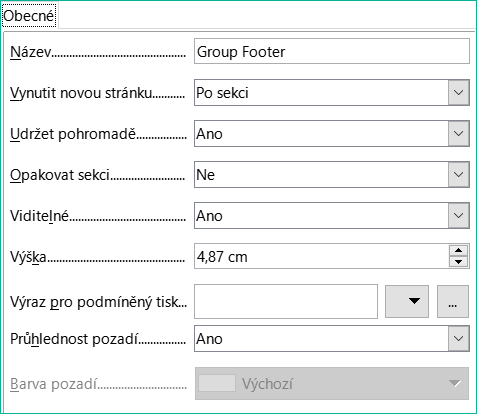
Obrázek 7: Vlastnosti pro zápatí Reader_Name
K výpočtu celkových pokut se používá vestavěná funkce.
Upomínka je zobrazena na obrázku 8. Oblast s podrobnostmi obsahuje položky médií, které si čtenář vypůjčil. Zápatí skupiny obsahuje celkovou dlužnou pokutu.
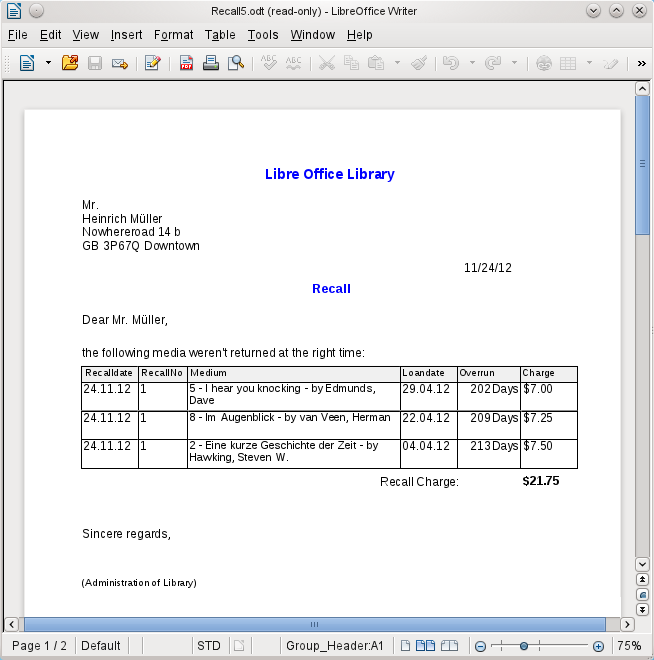
Obrázek 8: Sestava upomínky
Poznámka
Sestavy pro jednotlivé záznamy mohou být také rozsáhlejší než jedna stránka. Velikost reportu je zcela odlišná od velikosti stránky. Roztažení oblasti s podrobnostmi na více než jednu stránku však může vést k chybným zlomům. Zde má nástroj Návrhář sestav stále problémy se správným výpočtem rozestupů. Pokud jsou zahrnuty jak oblasti seskupení, tak grafické prvky, může to vést k nepředvídatelným velikostem některých oblastí.
Jednotlivé prvky lze zatím přesouvat na pozice mimo velikost jedné stránky pouze pomocí myši a kurzorových kláves. Vlastnosti prvků udávají vždy stejnou maximální vzdálenost od horního rohu libovolné oblasti, která leží na první stránce.
Existují pouze tři typy polí pro prezentaci dat. Kromě textových polí (která mohou v rozporu se svým názvem obsahovat také čísla a formátování) existuje také typ pole, které může obsahovat obrázky z databáze. V poli Charge se zobrazí souhrn údajů na obrázku 9.
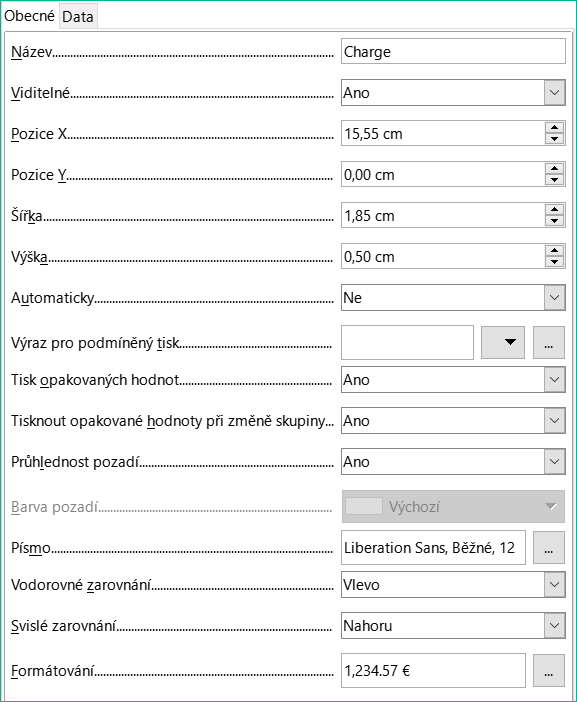
Obrázek 9: Vlastnosti (karta Obecné) pro pole Charge
Stejně jako u formulářů jsou pole pojmenována. Ve výchozím nastavení se použije název podkladového databázového pole.
Pole lze nastavit jako neviditelné. V případě polí se to může zdát poněkud zbytečné, ale je to užitečné pro záhlaví a zápatí skupin, které mohou být vyžadovány k provádění jiných funkcí seskupení, aniž by obsahovaly cokoli, co je třeba zobrazit.
Pokud je možnost Tisk opakovaných hodnot deaktivována, zobrazení pole se zablokuje, pokud je bezprostředně předtím načteno pole se stejným obsahem. To funguje správně pouze pro datová pole, která obsahují text. Číselná pole nebo pole s datem pokyn k deaktivaci ignorují, pole Popisku jsou při deaktivaci zcela vybledlá, i když se vyskytnou pouze jednou.
V nástroji Návrhář sestav lze pomocí podmíněného tiskového výrazu zakázat zobrazení určitého obsahu nebo lze hodnotu pole použít jako základ pro formátování textu a pozadí. Více o podmíněných výrazech je uvedeno v části „Podmíněný tisk“ na straně 1.
Nastavení kolečka myši nemá žádný vliv, protože pole sestavy nelze upravovat. Zdá se, že jde o pozůstatek z dialogového okna definice formuláře.
Funkci Tisk při změně skupiny nebylo možné reprodukovat ani v sestavách.
Pokud není pozadí definováno jako průhledné, lze pro každé pole definovat barvu pozadí.
Ostatní položky se týkají vnitřního obsahu daného pole. Jedná se o písmo (pro barvu písma, váhu písma atd., viz obrázek 10), zarovnání textu v poli a formátování pomocí příslušného dialogového okna Znaky (viz obrázek 11).
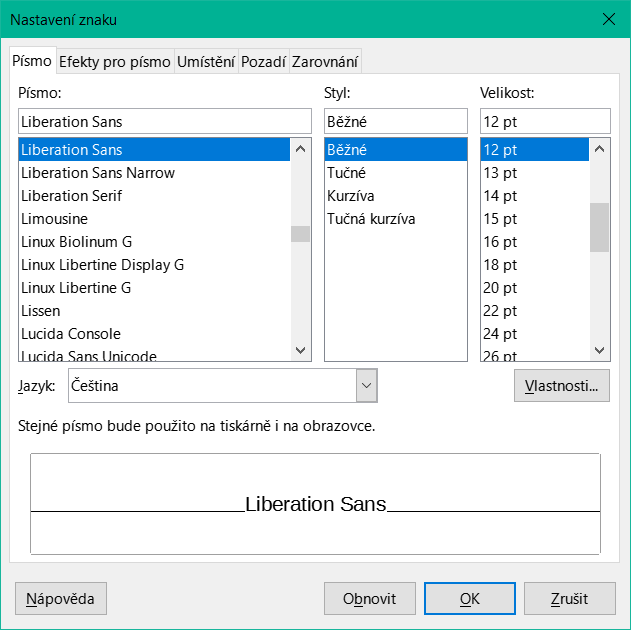
Obrázek 10: Dialogové okno Nastavení znaků
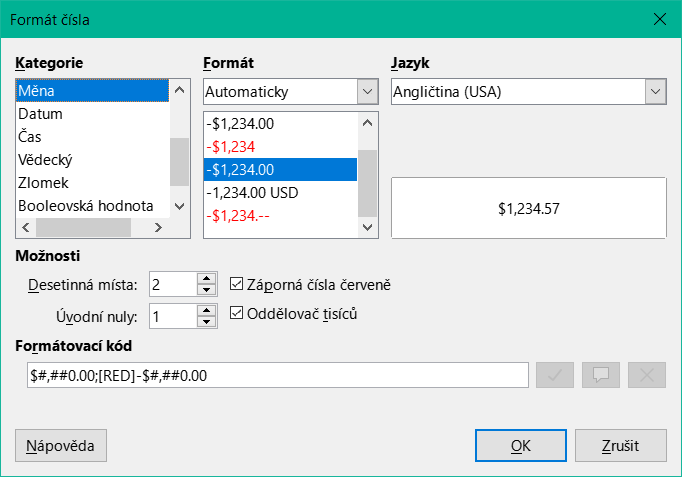
Obrázek 11: Dialogové okno Formát čísla
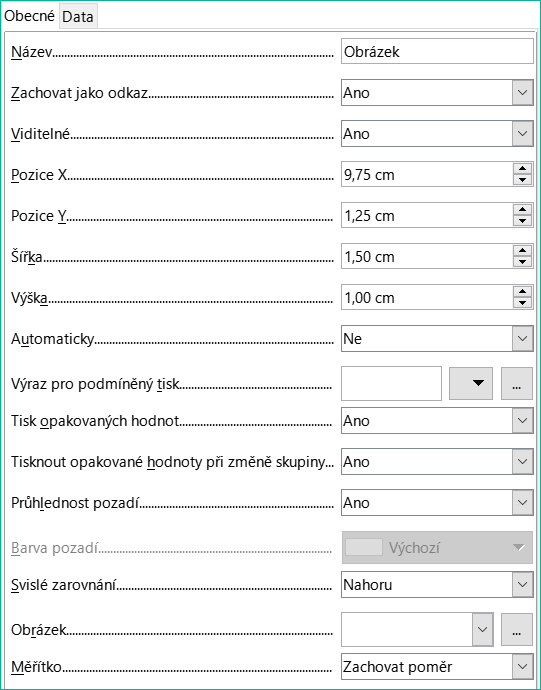
Obrázek 12: Vlastnosti (karta Obecné) pro ovládací prvek obrázku
Grafický ovládací prvek (viz obrázek 12) může obsahovat grafiku z databáze i mimo ni. V současné době však není možné uložit grafiku, například logo, trvale do databáze aplikace Base. Proto je nezbytné, aby grafika byla k dispozici v cestě vyhledávání, i když je nám nabídnuta volba vložení, nikoli propojení obrázků, a první pole Nastavit jako odkaz lze nastavit (doslova uzavřít) na odpovídající plánovanou funkci. Jedná se o jednu z několika funkcí, které jsou plánovány pro aplikaci Base a jsou v grafickém uživatelském rozhraní, ale ve skutečnosti ještě nebyly implementovány – takže tlačítka a zaškrtávací políčka nemají žádný účinek.
Případně může být grafika uložena v samotné databázi, takže je k dispozici interně. V takovém případě však musí být přístupný prostřednictvím jednoho z polí v dotazu, který je základem sestavy.
Chceme-li načíst externí grafiku, použijeme tlačítko výběru vedle pole Grafika. Chceme-li načíst grafické databázové pole, zadáme pole na kartě Data.
Zdá se, že nastavení vertikálního zarovnání nemá ve fázi návrhu žádný vliv. Po vyvolání sestavy se však grafika zobrazí na správném místě.
Při škálování můžeme vybrat možnost Ne, Zachovat poměr stran nebo Automatická. velikost. To odpovídá nastavení formuláře:
Ne: Obrázek není přizpůsoben ovládacímu prvku. Pokud je příliš velký, zobrazí se oříznutá verze. Původní obrázek tím není ovlivněn.
Zachovat poměr stran: Obrázek je přizpůsoben ovládacímu prvku, ale není zkreslený.
Automatická velikost: Obraz se přizpůsobí ovládacímu prvku a v některých případech může být zkreslený.
Při úpravách sestav obsahujících obrázky se může stát, že se databáze výrazně zvětší. Uvnitř souboru *.odb zobrazeného na obrázku 13 umístí Base z ne zcela pochopitelných důvodů do adresáře sestavy složku ObjectReplacements. Tato složka obsahuje soubor „report“, který je zodpovědný za zvětšení.
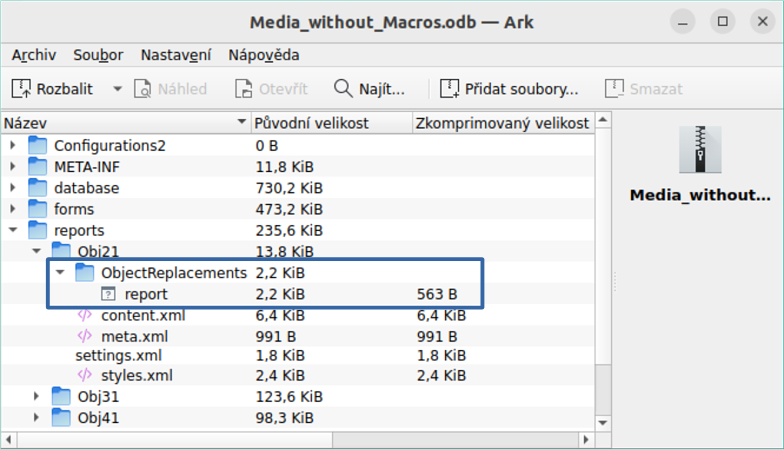
Obrázek 13: Obsah souboru ODB zobrazený pomocí správce archivu souborů Ark
Pokud je databáze otevřena v archivačním programu, je tato složka s obsahem viditelná v podadresáři Reports. Složku můžeme bezpečně najít a odstranit pomocí archivačního programu.
Poznámka
Pokud se sestavy nebudou opakovaně upravovat, stačí složku ObjectReplacements odstranit jednou. Velikost této složky může velmi rychle růst. To závisí na počtu a velikosti zahrnutých souborů. Test ukázal, že jediný soubor jpg o velikosti 2,8 MB zvětšil soubor *.odb o 11 MB! Viz Bug 80320.
Grafy můžeme do sestavy vložit pomocí příslušného ovládacího prvku nebo pomocí Vložit > Ovládací prvky sestavy > Graf. Graf je jediným způsobem, jak reprodukovat data, která se nenacházejí ve zdroji dat zadaném pro sestavu. Graf lze tedy považovat za jakousi dílčí sestavu, ale také za samostatnou součást sestavy.

Obrázek 14: Výběr typu grafu na kartě Vlastnosti (karta Obecné)
Místo pro graf musíme nakreslit myší. V obecných vlastnostech (viz obrázek 14) můžeme kromě známých polí vybrat typ grafu (viz příslušné typy v Calcu). Kromě toho můžeme nastavit maximální počet záznamů pro náhled, který poskytne představu o tom, jak bude graf nakonec vypadat.
Grafy lze formátovat stejným způsobem jako v aplikaci Calc (poklepeme na graf). Další informace nalezneme v popisu v příručce Průvodce programem LibreOffice Calc.
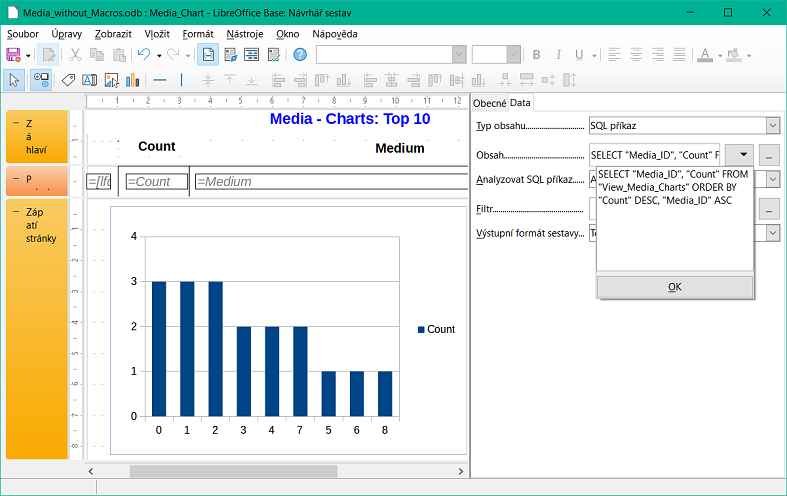
Obrázek 15: Použití příkazu SQL k vyplnění grafu zobrazujícího četnost výpůjček médií
Graf je propojen v části Data s potřebnými datovými poli. Příklad seznamu Media Top 10 na obrázku 15 grafu ukazuje četnost výpůjček jednotlivých médií. Editor dotazů slouží k vytvoření vhodného příkazu SQL, stejně jako v případě pole se seznamem ve formuláři. První sloupec v dotazu se použije k označení svislých sloupců v grafu, zatímco druhý sloupec poskytuje celkový počet výpůjčních transakcí, který je uveden ve výšce sloupců.
Ve výše uvedeném příkladu graf zpočátku ukazuje jen velmi málo, protože před vydáním příkazu SQL byly provedeny pouze omezené testovací výpůjčky.
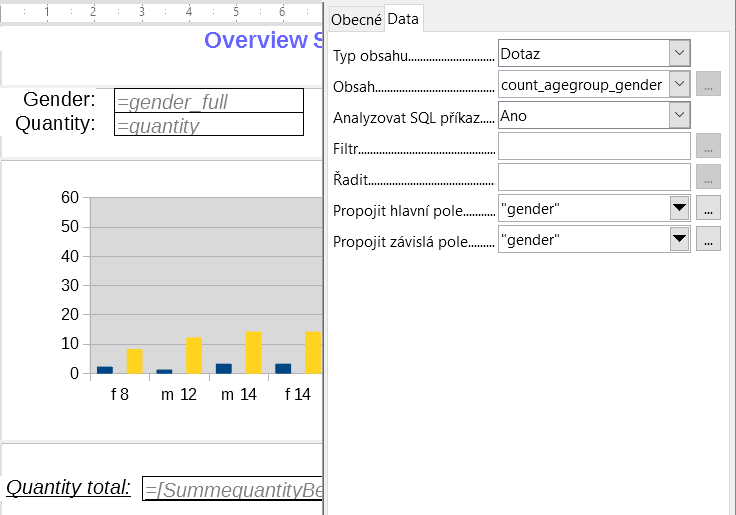
Obrázek 16: Naplnění grafu pomocí dotazu
Graf lze vyplnit pomocí dotazu ve Vlastnostech dat, jak je znázorněno na obrázku 16. Tento graf z databáze Example_sport.odb ukazuje kromě základů tvorby grafů v sestavách i něco zvláštního: náhled grafu zobrazuje více sloupců, než se předpokládalo. To vyplývá z obsahu dotazu, který vytváří další sloupce, které se všechny nezobrazí v samotném grafu.
Poznámka
Databáze Example_sport.odb je součástí balíčku ukázkových databází pro tuto příručku.
Filtrování a třídění pomocí interních nástrojů nástroje Návrháře sestav není nutné, protože to již bylo v rámci možností provedeno v dotazu.
Tip
V zásadě chceme z vytváření sestav odstranit co nejvíce úkolů. Cokoli lze zvládnout na začátku procesu pomocí dotazů, není třeba znovu provádět během relativně pomalého procesu vytváření samotné sestavy.
Stejně jako u hlavních formulářů a podformulářů jsou nyní některá pole propojena. V aktuální zprávě jsou věkové skupiny účastníků a účastnic sportovních táborů uvedeny v tabulce. Jsou rozděleny do skupin podle pohlaví. V každé skupině je nyní samostatný graf. Aby bylo zajištěno, že graf používá pouze údaje pro správné pohlaví, jsou obě pole nazvaná „Gender“ – ve zprávě a v grafu – propojena.
Osa X grafu je automaticky propojena s prvním sloupcem v tabulce zdroje dat. Pokud jsou v tabulce více než dva sloupce, do grafu se automaticky vloží další sloupce. Další nastavení grafu jsou dostupná po výběru celého grafu dvojitým klepnutím. Klepnutím pravým tlačítkem myši se nad diagramem otevře místní nabídka, jejíž obsah závisí na tom, který prvek byl vybrán. Obsahuje možná nastavení pro datové rozsahy uvedené na obrázku 17:
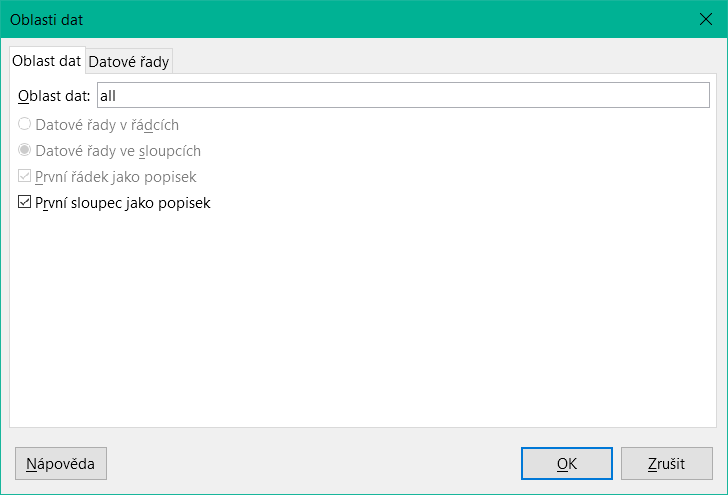
Obrázek 17: Dialogové okno Oblasti dat (karta Oblasti dat)
Volba Datové řady ve sloupcích je šedá, a proto ji nelze změnit. Nelze změnit ani zaškrtávací políčko První řádek jako popisek. Zbývající nastavení na kartě Oblast dat by se neměla měnit, protože zde existuje více možností, než kolik jich sestava Návrhář sestav skutečně zvládne.
Karta Datové řady naopak skrývá několik nastavení, která mohou výrazně změnit výchozí vzhled grafu. Zobrazí všechny datové řady, které jsou k dispozici pro první sloupec dotazu. Všechny, které nechceme zobrazit, můžeme v tomto okamžiku odstranit.
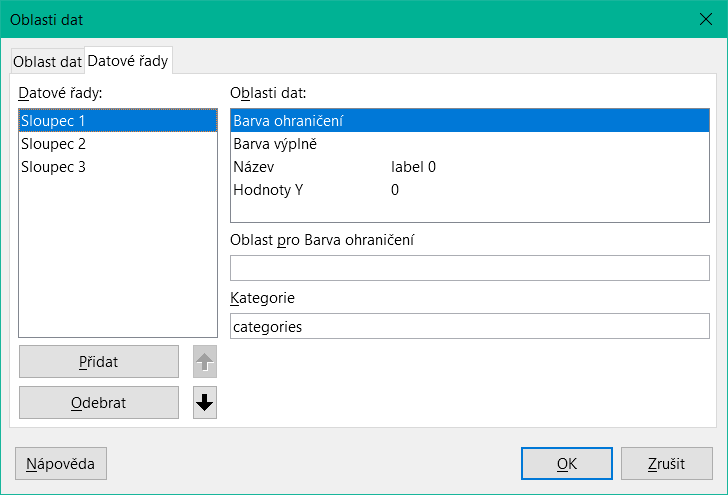
Obrázek 18: Dialogové okno Oblasti dat (karta Datové řady)
V příkladu na obrázku 18 bylo v grafu viditelných příliš mnoho sloupců. To vyžaduje zlepšení! Gender ani age_group_sort, jejichž názvy pocházejí z podkladového dotazu, zde nejsou k ničemu. Řada pohlaví (gender) slouží k provázání grafu se zdrojem dat sestavy a v žádném případě ji nelze znázornit číselně. A age_group_sort slouží pouze k zajištění správného seřazení hodnot v dotazu, protože jinak by kód jako „m8“ přišel bezprostředně před „m80“ místo na začátek (řazení v textových polích často vede k podobným nežádoucím výsledkům).
Po odstranění všech řádků před řádkem Celkem vypadá náhled grafu tak, jak je znázorněno na obrázku 19:
Obrázek 19: Náhled grafu zobrazujícího počet účastníků soutěže pro každou kombinaci pohlaví / věková skupina
Tento náhled zobrazuje 10 sloupců – prvních deset sloupců dotazu. Při skutečném spuštění se zobrazí pouze ty sloupce, které patří ke správnému pohlaví: sloupce „m“ pro muže a „f“ pro ženy.
Osa Y stále vykazuje nešťastnou vlastnost. Koneckonců neexistuje poloviční člověk! I to by se dalo zlepšit. Při automatickém spuštění s tímto nastavením se však tato čísla změní na celá čísla, pokud se rozsah hodnot nezastaví, jako ve výše uvedeném příkladu, na hodnotě „3“. Pokud by se toto automatické zpracování vypnulo, bylo by skutečně nutné provést určité ruční vylepšení.
Všechna další nastavení jsou podobná těm, která Calc používá pro vytváření grafů.
Obrázek 20: Vlastnosti (záložka Data) pro pole Charge
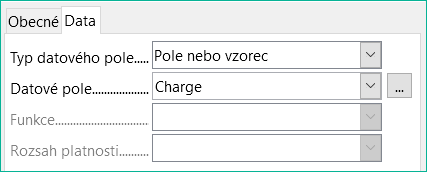
V dialogovém okně Vlastnosti je na kartě Data na obrázku 20 ve výchozím nastavení zobrazeno pouze pole databáze, ze kterého budou načtena data pro toto pole sestavy. Kromě typů polí Pole nebo vzorec jsou však k dispozici také typy Funkce, Počítadlo a Uživatelsky definovaná funkce.
Můžeme předem vybrat funkce Nárůst, Minimum a Maximum. Budou se vztahovat buď na aktuální skupinu, nebo na celou sestavu. Tyto funkce mohou vést k problémům, pokud je pole prázdné (NULL). Pokud jsou tato pole formátována jako čísla, zobrazí se NaN, tj. není v nich uvedena žádná číselná hodnota. U prázdných polí se neprovádí žádný výpočet a výsledkem je vždy 0.
Taková pole lze přeformátovat tak, aby zobrazovala hodnotu 0, a to pomocí následujícího vzorce v oblasti Data zobrazení.
IF([numericfield];[numericfield];0)
Tato funkce počítá se skutečnou hodnotou pole, které nemá žádnou hodnotu. Zdá se, že by bylo jednodušší formulovat základní dotaz pro sestavu tak, aby se u číselných polí místo NULL uváděla 0.
Počítadlo počítá pouze záznamy, které se vyskytnou buď ve skupině, nebo v celé sestavě. Pokud je počítadlo vloženo do oblasti Podrobnosti, bude každý záznam opatřen průběžným číslem. Číslování se použije pouze pro záznamy ve skupině nebo v celé sestavě.
Obrázek 21: Vlastnosti (karta Data) s typem datového pole nastaveným na hodnotu Uživatelem definovaná funkce
Nakonec je k dispozici podrobná funkce definovaná uživatelem, jak je znázorněno na obrázku 21. Může se stát, že nástroj Návrhář sestav sám zvolí tuto variantu, pokud byl požadován výpočet, ale z nějakého důvodu nedokáže správně interpretovat zdroj dat.
Nástroj Návrhář sestav nabízí řadu funkcí pro zobrazení dat i pro nastavení podmínek. Pokud tyto funkce nestačí, lze pomocí jednoduchých výpočetních kroků vytvořit uživatelsky definované funkce, které jsou užitečné zejména v zápatí skupin a v souhrnech.
Nástroj Návrhář sestav je založen na nástroji Pentaho Report Builder. Malá část jeho dokumentace je na adrese http://wiki.pentaho.com/display/Reporting/9.+Report+Designer+Formula+Expressions.
Dalším zdrojem jsou specifikace pro standard OpenFormula:
http://www.oasis-open.org/committees/download.php/16826/openformula-spec-20060221.html se základními zásadami pro zadávání vzorců shrnutými v tabulce 1.
Tabulka 1: Základní zásady pro zadávání vzorců
|
Princip |
Detail |
|
Vzorce začínají znaménkem rovnítka. |
= |
|
Odkazy na datová pole se uvádějí v hranatých závorkách. |
[Název pole] |
|
Pokud datová pole obsahují speciální znaky (včetně mezer), musí být název pole rovněž uzavřen v uvozovkách. |
["Tento název pole by měl být v uvozovkách"] |
|
Zadávání textu musí být vždy v dvojitých uvozovkách. |
"Zadaný textu" |
|
Povoleny jsou následující operátory. |
+, -, |
|
Možné jsou následující relace. |
= , <> , < , <= , > , >= |
|
Kulaté závorky jsou povoleny. |
( ) |
|
Výchozí chybová zpráva. |
NA (není k dispozici) |
|
Chybová zpráva pro prázdné pole, které bylo definováno jako číslo. |
NaN (Možná "not a number" ("není číslo", pozn. překl.)?) |
Všechny zadané vzorce se vztahují pouze k aktuálnímu záznamu. Relace s předchozími nebo následujícími záznamy proto nejsou možné.

Obrázek 22: Klepnutím na tlačítko elipsy vedle pole Data přejdeme do Průvodce funkcí.
Vedle datového pole je tlačítko se třemi tečkami, kdykoli lze zadat vzorec, jak je znázorněno na obrázku 22. Tímto tlačítkem se spustí Průvodce funkcí zobrazený na obrázku 23.
Obrázek 23: Dialogové okno Průvodce funkcí
Je zde mnohem méně funkcí než v Calcu, i když mnoho funkcí má ekvivalenty z Calcu. Zde Průvodce vypočítá výsledek funkce přímo.
Průvodce funkcemi nefunguje vždy dokonale. Například textové položky nejsou zabírány dvojitými uvozovkami. Při spuštění funkce se však zpracovávají pouze položky s dvojitými uvozovkami.
K dispozici jsou funkce uvedené v tabulce 2.
Tabulka 2: Funkce dostupné v Průvodci funkcí
|
Funkce |
Popis |
|
Funkce data a času |
|
|
DATE |
Vytvoří platné datum z číselných hodnot roku, měsíce a dne. |
|
DATEDIF |
Vrátí celkový počet let, měsíců nebo dnů mezi dvěma hodnotami data. |
|
DATEVALUE |
Převede americký údaj o datu v textové podobě (uvozovky) na hodnotu data. Vytvořenou americkou variantu data lze následně přeformátovat. |
|
DAY |
Vrátí den v měsíci pro zadané datum. |
|
DAYS |
Vrátí počet dní mezi dvěma daty. |
|
HOUR |
Vrátí hodiny zadaného času ve 24hodinovém formátu. |
|
MINUTE |
Vrací minuty data v interním číselném formátu |
|
MONTH |
Vrátí měsíc pro zadané datum jako číslo. |
|
NOW |
Vrátí aktuální datum a čas. |
|
SECOND |
Vrací sekundy data v interním číselném formátu |
|
TIME |
Zobrazuje aktuální čas. |
|
TIMEVALUE |
Převede textový údaj o čase na hodnotu času pro výpočty. |
|
TODAY |
Zobrazuje aktuální datum. |
|
WEEKDAY |
Vrátí den v týdnu jako číslo. Den číslo 1 je neděle. |
|
YEAR |
Vrátí část roku v položce data. |
|
Logické funkce |
|
|
AND |
Výsledek je TRUE, pokud jsou všechny jeho argumenty TRUE. |
|
FALSE |
Definuje logickou hodnotu jako FALSE. |
|
IF |
Pokud je podmínka TRUE, pak tato hodnota, jinak jiná hodnota. |
|
IFNA |
|
|
NOT |
Obrátí logickou hodnotu argumentu. |
|
OR |
Výsledek je TRUE, pokud je jedna z jeho podmínek TRUE. |
|
TRUE |
Definuje logickou hodnotu jako TRUE. |
|
XOR |
Výsledek je TRUE, pokud je pouze jedna z propojených hodnot TRUE. |
|
Funkce zaokrouhlování |
|
|
INT |
Zaokrouhluje směrem dolů na předchozí celé číslo. |
|
Matematické funkce |
|
|
ABS |
Vrací absolutní (nezápornou) hodnotu čísla. |
|
ACOS |
Vypočítá arcsin čísla. – argumenty mezi –1 a 1. |
|
ACOSH |
Vypočítá areakosinus (inverzní hyperbolický kosinus) – argument >= 1. |
|
ASIN |
Vypočítá arcsin čísla – argument mezi –1 a 1. |
|
ATAN |
Vypočítá arkustangens čísla. |
|
ATAN2 |
Vypočítá arkustangens souřadnice x a souřadnice y. |
|
AVERAGE |
Uvádí průměr zadaných hodnot. |
|
AVERAGEA |
Uvádí průměr zadaných hodnot. Text je považován za nulu. |
|
COS |
Argumentem je úhel v radiánech, jehož kosinus se má vypočítat. |
|
EVEN |
Zaokrouhluje kladné číslo nahoru nebo záporné číslo dolů na nejbližší sudé celé číslo. |
|
EXP |
Vypočítá exponenciální funkci (základ „e“). |
|
LN |
Vypočítá přirozený logaritmus čísla. |
|
LibreOfficeG10 |
Vypočítá logaritmus čísla (se základem '10'). |
|
MAX |
Vrátí maximum z řady čísel. |
|
MAXA |
Vrací maximální hodnotu v řádku. Jakýkoli text je nastaven na hodnotu nula. |
|
MIN |
Vrací nejmenší z řady hodnot. |
|
MINA |
Vrací minimální hodnotu v řádku. Jakýkoli text je nastaven na hodnotu nula. |
|
MOD |
Vrátí zbytek pro dělení po zadání dividendy a dělitele. |
|
ODD |
Zaokrouhluje kladné číslo nahoru nebo záporné číslo dolů na nejbližší liché celé číslo. |
|
PI |
Udává hodnotu čísla 'π'. |
|
POWER |
Zvyšuje základ na mocninu exponentu. |
|
SIN |
Vypočítá sinus čísla. |
|
SQRT |
Vypočítá druhou odmocninu čísla. |
|
SUM |
Sčítá seznam číselných hodnot. |
|
SUMA |
Sčítá seznam číselných hodnot. Povolena jsou textová pole a pole Ano/Ne. Tato funkce bohužel končí chybovou zprávou. |
|
VAR |
Vypočítá rozptyl, počínaje vzorkem. |
|
Textové funkce |
|
|
EXACT |
Zobrazí, zda se dva textové řetězce přesně rovnají. |
|
FIND |
Udává odsazení textového řetězce v rámci jiného řetězce. |
|
LEFT |
Zadaný počet znaků textového řetězce se reprodukuje zleva. |
|
LEN |
Udává počet znaků v textovém řetězci. |
|
LOWER |
Převede text na malá písmena. |
|
MESSAGE |
Zformátuje hodnotu do zadaného výstupního formátu. |
|
MID |
Zadaný počet znaků textového řetězce se reprodukuje od zadané pozice znaku. |
|
REPLACE |
Nahradí podřetězec jiným podřetězcem. Musí být zadána počáteční pozice a délka nahrazovaného podřetězce. |
|
REPT |
Opakuje text tolikrát, kolikrát je zadáno v argumentu funkce. |
|
RIGHT |
Zadaný počet znaků textového řetězce se reprodukuje od pravého okraje. |
|
SUBSTITUTE |
Nahradí určité části zadaného textového řetězce novým textem. Navíc můžeme určit, který z několika výskytů cílového řetězce má být nahrazen. |
|
T |
Vrací text nebo prázdný textový řetězec, pokud hodnota není text (například číslo). |
|
TEXT |
Převod čísel nebo časů na text. |
|
TRIM |
Odstraňuje počáteční a koncové mezery a redukuje více mezer na jednu. |
|
UNICHAR |
Převede desetinné číslo Unicode na znak Unicode. Například 196 se změní na „Ä“ („Ä“ má hexadecimální hodnotu 00C4, což je 196 v desetinných číslech bez počátečních nul). |
|
UNICODE |
Převede znak Unicode na desetinné číslo Unicode. |
|
UPPER |
Vrací textový řetězec napsaný velkými písmeny. |
|
URLENCODE |
Převede zadaný text na text, který odpovídá platné adrese URL. Pokud není zadán žádný konkrétní standard, postupuje se podle ISO-8859-1. |
|
Informační funkce |
|
|
CHOOSE |
Prvním argumentem je index, za kterým následuje seznam hodnot. Vrátí se hodnota reprezentovaná indexem. |
|
COUNT |
Započítávají se pouze pole obsahující číslo nebo datum. |
|
COUNTA |
Zahrnuje také pole obsahující text. Započítává se i NULL a logická pole. |
|
COUNTBLANK |
Spočítá prázdná pole v oblasti. |
|
HASCHANGED |
Zkontroluje, zda se pojmenovaný sloupec změnil. O sloupci však nejsou uvedeny žádné informace. |
|
INDEX |
Pracuje s regiony |
|
ISBLANK |
Testuje, zda má pole hodnotu NULL (je prázdné). |
|
ISERR |
Vrací hodnotu TRUE, pokud má záznam jinou chybu než NA. |
|
ISERROR |
Stejně jako ISERR s tím rozdílem, že NA také vrací TRUE. |
|
ISEVEN |
Testuje, zda je číslo sudé. |
|
ISLOGICAL |
Testuje, zda se jedná o hodnotu Ano/Ne. |
|
ISNA |
Testuje, zda je výraz chybou typu NA. |
|
ISNONTEXT |
Testuje, zda hodnota není text. |
|
ISNUMBER |
Testuje, zda je něco číselné. |
|
ISODD |
Testuje, zda je číslo liché. |
|
ISREF |
Testuje, zda je něco odkazem na pole. |
|
ISTEXT |
Testuje, zda je obsahem pole text. |
|
NA |
Vrací kód chyby NA. |
|
VALUE |
|
|
Definováno uživatelem |
|
|
CSVARRAY |
Převede text CSV na pole. |
|
CSVTEXT |
Převede pole na text CSV. |
|
NORMALIZEARRAY |
|
|
NULL |
Vrací hodnotu NULL. |
|
PARSEDATE |
Převede text na datum. Používá formát SimpleDateFormat. Vyžaduje datum v textu, jak je popsáno v tomto formátu data. Příklad: PARSEDATE("9.10.2012"; "dd.MM.rrrr") dává interně použitelné číslo pro datum. |
|
Informace o dokumentu |
|
|
AUTHOR |
Autor, jak je načten z nastavení Nástroje > Možnosti > LibreOffice > Uživatelské údaje. Nejedná se tedy o skutečného autora, ale o aktuálního uživatele databáze. |
|
TITLE |
Vrací název sestavy. |
Pomocí uživatelsky definovaných funkcí můžeme vracet konkrétní mezivýsledky pro skupinu záznamů. V našem příkladu byla taková funkce použita k výpočtu pokut v oblasti Reader_Name_Footer.
V Navigátoru sestavy se funkce zobrazí ve skupině Reader_Name. Klepnutím pravým tlačítkem myši na tuto funkci můžeme definovat další funkce podle názvu (viz obrázek 24).
Vlastnosti funkce SummeGebuehrLeser_Name jsou uvedeny výše. Vzorec přidá pole Charge k hodnotě již uložené v samotné funkci. Počáteční hodnota je hodnota pole Charge při prvním průchodu skupinou. Tato hodnota je uložena ve funkci pod názvem funkce a je znovu použita ve vzorci, dokud není ukončena smyčka a zapsána patička skupiny.
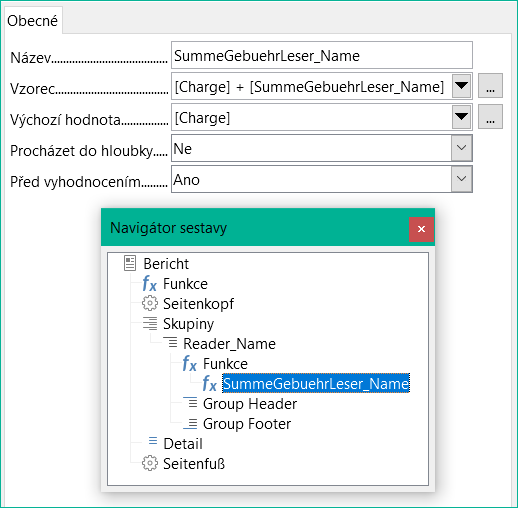
Obrázek 24: Výběrem uživatelsky definované funkce v navigátoru sestavy získáme přístup k jejím vlastnostem.
Zdá se, že procházení do hloubky zatím nemá žádnou funkci, pokud se zde grafy nepovažují za dílčí sestavy.
Pokud je pro funkci aktivováno předběžné vyhodnocení, může být výsledek umístěn také v záhlaví skupiny. Jinak záhlaví skupiny obsahuje pouze odpovídající hodnotu prvního pole skupiny.
Uživatelsky definované funkce mohou také odkazovat na jiné uživatelsky definované funkce. V takovém případě je třeba zajistit, aby použité funkce již byly vytvořeny. Předběžný výpočet ve funkcích, které odkazují na jiné funkce, musí být vyloučen.
[SumMarksClass] / ([ClassNumber]+1)
Vztahuje se ke skupině Class. Obsah pole Marks se sečte a vrátí se součet za všechny záznamy. Součet známek se vydělí součtem záznamů. Abychom získali správné číslo, je třeba přičíst 1, jak je uvedeno v položce [ClassNumber]. Z toho pak vyplynou průměrné známky.
Pomocí Data > Datové pole můžeme zadávat vzorce, které ovlivňují pouze jedno pole v oblasti Podrobnosti.
IF([boolean_field];"Yes";"No")
nastaví přípustné hodnoty na "Yes" nebo "No" namísto TRUE a FALSE.
Může se stát, že se v poli se vstupním vzorcem objeví pouze jedno číslo. V textových polích je to nula. Chceme-li to napravit, musíme změnit textové pole z výchozího „Number“ na „Text“.

Obrázek 25: Pole podmíněného tiskového výrazu na kartě Obecné v okně Vlastnosti
Obecné vlastnosti záhlaví skupin, zápatí skupin a polí zahrnují pole Podmíněný tiskový výraz (viz obrázek 25). Vzorce zapsané v tomto poli ovlivňují obsah pole nebo zobrazení celé oblasti. I zde můžeme využít Průvodce funkcí.
[Názevpole]="true"
způsobí, že se obsah pojmenovaného pole zobrazí pouze v případě, že je true.
Poznámka
Viz také databáze Example_Report_conditional_Overlay_Graphics.odb, která je součástí ukázkových databází k této knize.
Mnoho forem podmíněného zobrazení není plně určeno zadanými vlastnostmi. Pokud má být například za desáté místo seznamu výsledků soutěže vložena grafická oddělovací čára, nelze pro grafické zobrazení jednoduše použít následující příkaz podmíněného zobrazení:
[Place]=10
Tento příkaz nefunguje. Namísto toho se grafika bude nadále zobrazovat v části Podrobnosti po každém dalším záznamu. Viz chyba 73707.
Pokud chceme v tomto místě pouze překrýt obdélníkový tvar, lze to provést pomocí grafického ovládacího prvku, kterému lze zadat adresu (černobílého) grafického souboru. V obecných vlastnostech tohoto ovládacího prvku by měla být vybrána možnost Měřítko > Autom.. Pak bude grafika odpovídat formuláři a podmínka bude splněna.
Není-li to jinak nutné, je bezpečnější vázat podmíněné zobrazení na zápatí skupiny než na grafiku. Čára je umístěna v zápatí skupiny. Pak se čára skutečně objeví za 10. místem, pokud je formulována výše uvedeným způsobem. Protože je podmínka spojena se zápatím skupiny, řádek se zobrazí pouze tehdy, je-li to skutečně nutné. V opačném případě může podmíněné zobrazení vést k tomu, že se místo čáry objeví prázdné místo.
Zde můžeme také použít tvary poskytované Vložit > Tvary > Standardní tvary, například vodorovnou čáru, která se prolíná se zápatím skupiny.
Podmíněné formátování lze použít například na obrázku 26 k formátování kalendáře tak, aby se víkendy zobrazovaly odlišně. Zvolíme Formát > Podmíněné formátování a zadáme:
WEEKDAY([Date])=1
a odpovídající formátování pro neděle.
Pokud v podmíněném formátování použijeme výraz „Výraz je“, můžeme zadat vzorec. Jak je v programu Calc obvyklé, lze formulovat několik podmínek, které se vyhodnocují postupně. Ve výše uvedeném příkladu se nejprve testuje neděle a poté sobota. Nakonec se může objevit dotaz na obsah pole. Například obsah „Holiday“ by vedl k jinému formátu.
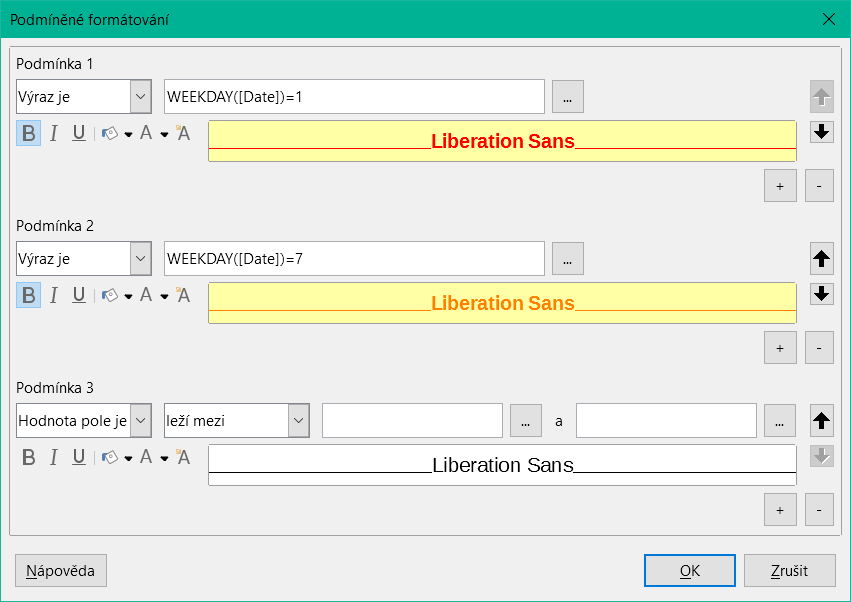
Obrázek 26: Dialogové okno Podmíněné formátování
Poznámka
Pokud se vyskytnou další neopravitelné chyby (neimplementované vzorce, příliš dlouhý text zobrazený jako prázdné pole apod.), je někdy nutné části sestavy odstranit nebo ji jednoduše vytvořit znovu.
Použití nástroje Návrhář sestav může být obtížné, protože některé funkce se zdají být k dispozici, ale nefungují tak, jak mají. Systém nápovědy navíc v současné době tyto problémové oblasti neřeší. Z tohoto důvodu je zde uvedeno několik příkladů, které ukazují, jak lze nástroj Návrhář sestav použít pro různé typy sestav.
Vytvoření účtu vyžaduje následující úvahy:
Jednotlivé položky musí být očíslovány.
Účty, které vyžadují více než jednu stranu, musí být očíslovány.
Účty, které vyžadují více než jednu stranu, by měly mít na každé straně průběžnou sumu, která se přenese na další stranu.
Zdá se, že několik současných chyb to znemožňuje:
Bug 51452: Je-li skupina nastavena na „Opakovat sekci“, vloží se před a za skupinu automaticky zlom stránky.
Bug 51453: Skupiny s individuálním stránkováním jsou povoleny, ale ve skutečnosti nefungují.
Bug 51959: Zápatí skupiny nelze opakovat. Může se objevit pouze na konci skupiny, nikoli na konci každé stránky. A pokud zvolíme možnost „Opakovat sekci“, zmizí úplně.
Kromě toho se objevují problémy s vkládáním čar do sestav. Vestavěné vodorovné a svislé čáry se objevují pouze ve verzích LibreOffice 4.0.5 a 4.1.1. Jako náhradu můžeme použít obdélníky, které však nelze správně umístit, pokud je v sekci zalomení stránky.
Zpráva v jednoduchém tvaru by měla vypadat jako na obrázku 27:
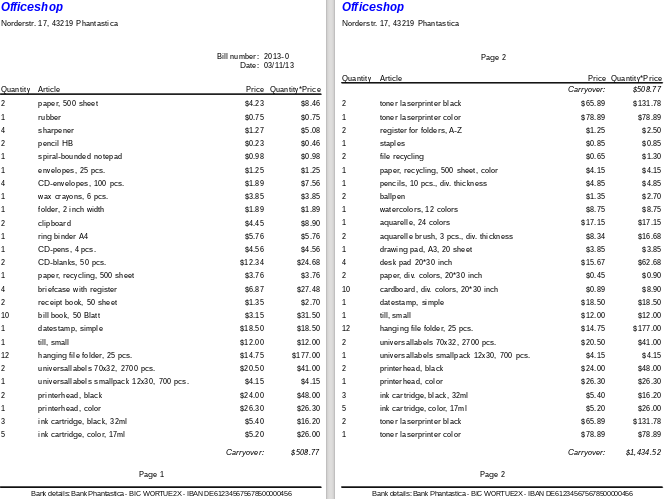
Obrázek 27: Počáteční návrh zprávy o činnosti úřadu Officeshop
Aby bylo možné překonat výše popsaná omezení, je při tvorbě odpovídajícího účtu nutné přesně dbát na rozměry stránek ve výsledném tištěném dokumentu. Tento příklad na obrázku 28 vychází z formátu DIN-A4. Celková výška každé stránky je tedy 29,7 cm.
Sestavu je třeba rozdělit do několika skupin. Dvě skupiny se vztahují ke stejnému poli tabulky a obsahují stejný prvek tabulky.
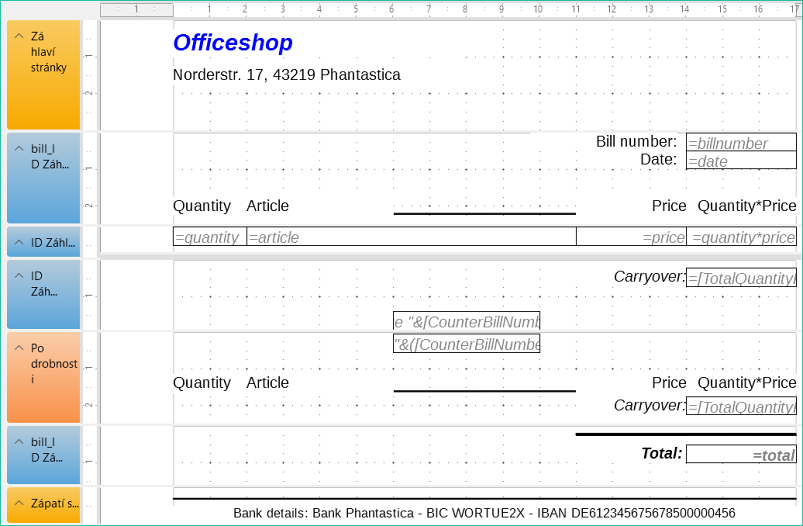
Obrázek 28: Úprava sestavy Officeshopu
Tabulka 3 ukazuje rozdělení stránky na jednotlivé části sestavy.
Tabulka 3: Rozdělení stránky do oddílů pro sestavu Officeshopu
|
Karta Umístění |
Popis |
Hodnota |
|
A |
Horní okraj |
2,00 cm |
|
B |
Záhlaví stránky (zobrazuje se na každé stránce, neobsahuje žádný obsah databáze, pouze materiál, jako je logo společnosti nebo adresa dodavatele). |
3,00 cm |
|
C |
Záhlaví skupiny pro účet (později by měly být přidány pouze položky, které patří k číslu účtu. Záhlaví skupiny se objevuje pouze na začátku účtu). |
2,50 cm |
|
D |
Záhlaví skupiny pro jednotlivé položky. (Sekce Detail je vyžadována pro jiný účel. Proto zde vzniká skupina, která také třídí obsah po zadání. Tato skupina obsahuje pouze jednu hodnotu.) |
0,70 cm |
|
E |
Záhlaví skupiny, rovněž vázané na položky. (Tato sekce se zobrazí pouze v případě, že se vyskytuje tolik položek, že je nutná další stránka. Obsahuje průběžný součet a číslo stránky v dolní části stránky. Po této části následuje přerušení stránky.) |
2,00 cm |
|
F |
Sekce s podrobnostmi. (Tato sekce se zobrazuje pouze v případě, že se vyskytuje tolik položek, že je potřeba další stránka. Obsahuje přenesenou částku a číslo stránky v horní části stránky.) |
2,50 cm |
|
G |
Zápatí skupiny pro číslo účtu. (Zde je uvedena celková částka za účet, případně s připočtenou DPH. Zápatí skupiny se objevuje pouze na poslední straně účtu.) |
1,60 cm |
|
H |
Zápatí stránky (např. bankovní údaje) |
1,00 cm |
|
I |
Okraj stránky |
1,00 cm |
Zalomení stránky následuje pouze v případě, že je položek příliš mnoho. Pro položky máme následující volná místa, jak je uvedeno v tabulce 4:
Tabulka 4: Volné místo pro položky v sestavě Officeshop
|
|
29,70 cm |
(DIN A 4) |
|
- |
2,00 cm |
(Poz. A) |
|
- |
3,00 cm |
(Poz. B) |
|
- |
2,50 cm |
(Poz. C) |
|
- |
1,60 cm |
(Poz. G) |
|
- |
1,00 cm |
(Poz. H) |
|
- |
1,00 cm |
(Poz. I) |
|
= |
18,60 cm |
|
Zbývající volný prostor je tedy maximálně 18,60 cm/0,70 cm = 26,57. Zaokrouhlením nahoru získáme 26 řádků položek.
Jakmile se objeví 27. položka, musí okamžitě následovat zalomení stránky. To znamená, že se musí zobrazit záhlaví skupiny E a oddíl Podrobnosti. Potřebujeme tedy počítadlo položek (oddíl C). Jakmile toto počítadlo dosáhne hodnoty 27, zobrazí se sekce Podrobnosti (F).
Počítadlo položek je definováno takto:
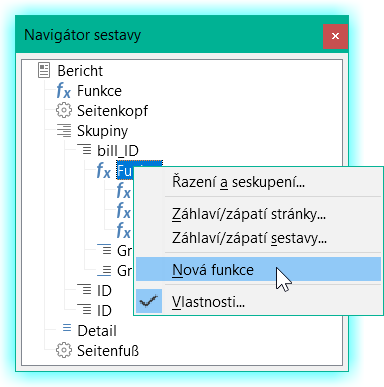
Obrázek 29: Vytvoření nové funkce pomocí navigátoru sestavy
Pomocí nástroje Navigátor sestavy vyhledáme skupinu Bill_ID (viz obrázek 29). Naše nová funkce se jmenuje CounterBillNumber. Vzorec je [CounterBillNumber] + 1. Počáteční hodnota je 1. Žádné podsestavy nejsou vázány (taková funkce neexistuje). Není ani předem vypočtena. Pro pokročilé výpočty používáme samostatné počítadlo CounterTotal.
Záhlaví skupiny E a sekce Podrobnosti F se zobrazí, pokud je na účtu celkem více než 26 položek a aktuální pozice záznamu dosáhla 26. Výraz pro podmíněné zobrazení je tedy pro obě varianty stejný:
AND([CounterBillNumber]=26;[CounterTotal]>26)
Obsah této sekce se proto zobrazí pouze v případě, že se očekává alespoň 27 položek. Na první straně se zobrazí záhlaví skupiny E. Následuje přerušení stránky a obsah oddílu Podrobnosti se zobrazí na další stránce.
Nyní musíme vypočítat počet oddílů, které se musí objevit na první stránce, jak je uvedeno v tabulce 5.
Tabulka 5: Výpočet počtu oddílů na první stránce
|
|
29,70 cm |
(DIN A 4) |
|
- |
2,00 cm |
(Poz. A) |
|
- |
3,00 cm |
(Poz. B) |
|
- |
2,50 cm |
(Poz. C) |
|
- |
18,20 cm |
(Poz. D * 26) |
|
- |
1,00 cm |
(Poz. H) |
|
- |
1,00 cm |
(Poz. I) |
|
= |
2,00 cm |
|
Zápatí skupiny není pro první stránku povinné. Celkem je k dispozici 26 řádků položek. Záhlaví skupiny E tak může na první straně zabírat maximálně 2 cm. Do těchto 2 cm se musí vejít průběžný součet a číslo stránky. Aby byl za všech okolností zajištěn správný zlom stránky, měla by být tato část ve skutečnosti o něco menší než 2 cm. V příkladu použijeme 1,90 cm.
V horní části další stránky se nachází sekce Podrobnosti. Protože se na této stránce nevyskytuje záhlaví skupiny položek (C), může sekce Podrobnosti zabírat stejně místa jako záhlaví, tedy 2,50 cm. Poté začneme další sérii položek se stejným uspořádáním jako na předchozí straně.
Přenesená částka se vypočítá prostým sečtením předchozích položek.
K vyhledání skupiny Bill_number se používá nástroj Navigátor sestavy. Nově vytvořená funkce se bude jmenovat TotalPrice. Vzorec je [Price] + [TotalPrice]. Počáteční hodnota je [Price]. Žádné podsestavy nejsou vázány. Ani tento údaj není třeba předem vypočítávat.
Přenášená částka se zobrazuje jak v záhlaví skupiny E, tak v sekci Podrobnosti. V záhlaví skupiny je hned na začátku stránky. Na první stránce se objeví v dolní části. V sekci Podrobnosti je součet uveden úplně dole. Je uveden na straně 2 přímo pod záhlavím tabulky.
Dotaz pro určení čísla stránky je podobný dotazu pro určení zobrazení záhlaví skupiny a části s podrobnostmi:
IF([CounterBillNumber]=26; "Page 1";"")
Tímto způsobem získáme číslo první stránky. Další podmínky IF lze použít pro ostatní stránky.
Stejným způsobem lze snadno nastavit číslo stránky pro následující stránku na „Page 2“.
Pokud vzorce pokračují stejným způsobem, mohou pokrýt libovolný počet stran.
Výraz pro podmíněné zobrazení se mění z
AND([CounterBillNumber]=26;[CounterBillComplete]>26)
na
AND(MOD([CounterBillNumber];26)=0;[CounterBillComplete]>[CounterBillNumber])
Záhlaví skupiny E a sekce Podrobnosti F se zobrazí pouze tehdy, když vydělením počítadla položek číslem 26 nevznikne žádný zbytek a celkový počet položek je větší než počítadlo položek.
Výraz pro číslo stránky se změní z
IF([CounterBillNumber]=26; "Page 1";"")
na
"Pag "&[CounterBillNumber]/26
pro aktuální stránku a
"Page "&([CounterBillNumber]/26)+1
pro následující stránku.
Sestava zobrazená na obrázku 30 při použití těchto nastavení ještě není zcela připravena k použití:
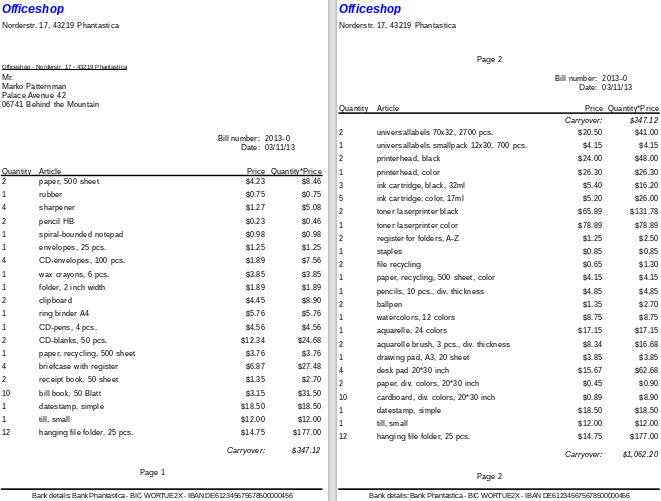
Obrázek 30: Revidovaný návrh sestavy Officeshop
Kvůli adresnímu poli je na první straně účtu méně položek než na druhé straně. Sekce Podrobnosti vpravo nahoře na druhé straně je proto výrazně menší než záhlaví skupiny účtu (C).
Aby bylo možné na prvních dvou stranách zohlednit různé počty položek, je třeba upravit vzorce.
Následující výpočet zajistí správné zobrazení příslušných sekcí.
AND(MOD([CounterBillNumber]-20;24)=0;[CounterBillComplete]>[CounterBillNumber])
Od počítadla položek odečteme počet položek na první stránce. Tento rozdíl se vydělí možným celkovým počtem položek na druhé stránce. Pokud je dělení přesné beze zbytku, je splněna první podmínka pro zobrazení záhlaví skupiny E a sekce Podrobnosti F. Kromě toho, jak bylo uvedeno výše, musí být aktuální hodnota počítadla položek menší než očekávaná celková hodnota. V opačném případě by na aktuální stránce bylo místo pro vypočtený celkový součet.
Možný celkový počet položek na druhé stránce je nyní menší, protože tato stránka nyní obsahuje číslo účtu a datum.
Číslo stránky lze nyní vypočítat jednodušeji:
"Page "&INT([CounterBillNumber]/24)+1
Funkce INT zaokrouhluje dolů na nejbližší celé číslo. První stránka obsahuje maximálně 20 položek. Výsledkem dělení je tedy hodnota <1 pro tuto první stránku. Tato hodnota se zaokrouhluje směrem dolů na nulu. Proto musíme k vypočtenému číslu stránky přidat 1, aby se 1 objevilo na první stránce. Podobně je tomu na straně 2.
Sestava stále vykazuje estetickou chybu. Při pečlivém pohledu na položky účtu zjistíme, že tři spodní položky na stránkách jsou stejné. Je to proto, že záznamy byly jednoduše zkopírovány. Ve skutečnosti se nejedná o stejné záznamy, ale o různé záznamy pro stejný produkt, které byly zpracovány nezávisle na sobě. Bylo by lepší seskupit je podle typu výrobku, aby se každý výrobek zobrazil pouze jednou s celkovým počtem objednaného množství.
V zásadě bychom se měli snažit odstranit z nástroje Návrhář sestav co nejvíce výpočtů a seskupení. Namísto použití skupin nástroje Návrhář sestav je lepší použít funkce seskupování v editoru dotazů. Aby nástroj Návrhář sestav mohl dotaz snadno zpracovat, změníme jej na pohled. V opačném případě se nástroj Návrhář sestav pokusí dotaz vylepšit vlastními funkcemi pro seskupování a třídění, což může rychle vést ke zcela nepraktickému kódování.
Konečný výsledek je zobrazen na obrázku 31:
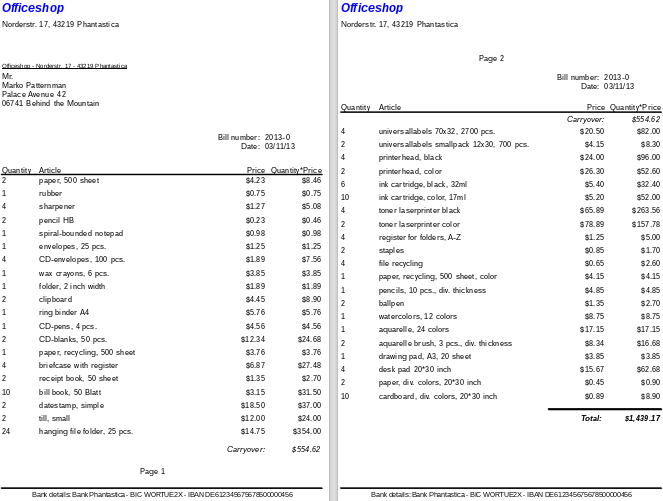
Obrázek 31: Konečný návrh sestavy Officeshopu
Zde se všechny položky vyskytují pouze jednou. Z původních 12 závěsných složek v dolní části strany 1 je nyní 24 závěsných složek. Quantity*Price bylo odpovídajícím způsobem přepočítáno.
Zejména v případě výroby účtů, jak je uvedeno v předchozím příkladu, může být užitečné připravit a zobrazit náhled nového tisku po každém zadání položky. Obsah účtu by měl být stanoven pomocí formuláře a následovat by měl tisk jednotlivých dokumentů.
Sestavy nelze spouštět s filtrem pomocí maker. Dotaz, který se použije k sestavení sestavy, však lze předem filtrovat. To se provádí buď pomocí parametrizovaného dotazu ve tvaru
SELECT * FROM "bill" WHERE "ID" = :ID
nebo dotazem, který je opatřen daty pomocí jednořádkové filtrační tabulky:
SELECT * FROM "bill" WHERE "ID" = (SELECT "Integer" FROM "Filter" WHERE "ID" = TRUE)
V dotazu s parametry je třeba po jeho spuštění vložit obsah do příslušného dialogového pole.
Pokud se k řízení procesu používá filtrační tabulka , její obsah se zapisuje pomocí makra. Proto již není nutný samostatný záznam, což uživateli usnadňuje život. Postup je popsán níže.
Filtrační tabulka by měla obsahovat vždy pouze jeden záznam. To znamená, že jeho primárním klíčem může být pole Ano/Ne. Ostatní pole v tabulce jsou pojmenována tak, aby bylo zřejmé, jaký typ obsahu obsahují. V příkladu uvedeném v tabulce 6 se pole, které má filtrovat primární klíč tabulky Bill, nazývá Integer, protože samotný klíč je tohoto typu. Pro další možnosti filtrování lze později přidat další pole. Filtr Integer lze použít v různých časech pro několik různých tabulek, protože starý obsah se před tiskem vždy přepíše novým. Toto vícenásobné použití však funguje pouze v databázi pro jednoho uživatele (aplikace Base s interní HSQLDB). Ve víceuživatelské databázi vždy existuje možnost, že některý jiný uživatel změní hodnotu filtru v některé z běžných tabulek, zatímco je prováděn dotaz, který filtr používá.
Tabulka 6: Filtrovací tabulka určená k filtrování primárního klíče tabulky Bill
|
Název pole |
Typ pole |
|
ID |
Ano/Ne [BOOLEAN] |
|
Integer |
Integer [INTEGER] |
Tato tabulka je na začátku vyplněna jedním záznamem. Za tímto účelem musí být v poli ID nastavena hodnota Ano (v jazyce SQL „TRUE“).
Pro vyvolání jedné sestavy musí formulář někde obsahovat primární klíč tabulky Bill. Tento primární klíč je načten a přenesen do tabulky filtrů pomocí makra. Makro pak spustí požadovanou sestavu.
SUB Filter_and_Print
DIM oDoc AS OBJECT
DIM oDrawpage AS OBJECT
DIM oForm AS OBJECT
DIM oField AS OBJECT
DIM oDatasorce AS OBJECT
DIM oConnection AS OBJECT
DIM oSQL_Command AS OBJECT
DIM stSQL AS STRING
oDoc = thisComponent
oDrawpage = oDoc.Drawpage
oForm = oDrawpage.Forms.getByName("MainForm")
oField = oForm.getByName("fmtID")
oDatasource = ThisComponent.Parent.CurrentController
If NOT (oDatasorce.isConnected()) THEN
oDatasource.connect()
END IF
oConnection = oDatasource.ActiveConnection()
oSQL_Command = oConnection.createStatement()
stSql = "UPDATE ""Filter"" SET ""Integer"" = '"+oField.GetCurrentValue()+"' WHERE
""ID"" = TRUE"
oSQL_Command.executeUpdate(stSql)
ThisDatabaseDocument.ReportDocuments.getByName("bill").open
END SUB
V tomto příkladu se formulář nazývá MainForm. Primární klíč se nazývá fmtID. Toto klíčové pole nemusí být viditelné, aby k němu makro mělo přístup. Hodnota pole se načte a příkaz UPDATE ji zapíše do tabulky. Poté je sestava spuštěna. Zobrazení, na které se hlášení vztahuje, je rozšířeno na podmínku:
… WHERE "bill_ID" = IFNULL((SELECT "Integer" FROM "Filter" WHERE "ID" = TRUE),"bill_ID") …
Odečte se pole Integer. Pokud nemá žádnou hodnotu, nastaví se na bill_ID. To znamená, že se zobrazí všechny záznamy, nikoli pouze filtrovaný záznam. Ze stejného zobrazení lze tedy vytisknout všechny uložené záznamy.
Při čtení jednotlivých řádků v tabulce v rámci sestavy může oko snadno sklouznout o řádek nahoru nebo dolů. Zabránit tomu pomáhá obarvení pozadí alespoň jednoho řádku. V příkladu na obrázku 32 jsou čáry jednoduše střídavě barevné. Výsledek vypadá takto:
Obrázek 32: Příklad zobrazující alternativní řádky barevně zvýrazněné pro zvýšení použitelnosti
Základem zprávy je dotaz se jmény a daty. Původní tabulka je dotazována s řazením podle data (měsíc a den), aby se zobrazilo pořadí narozenin v průběhu roku. K tomu slouží:
... ORDER BY MONTH("birthday") ASC, DAY("birthday") ASC
Abychom získali střídavé barvy, musíme vytvořit funkci, která může později pomocí určité hodnoty nastavit podmínky, které následně určí barvu pozadí. V sestavě vytvoříme textové pole a pomocí Vlastnosti > Data > Typ datového pole definujeme počítadlo, jak je znázorněno na obrázku 33.
Poznámka
Databáze Example_Report_Rows_Color_change_Columns.odb je součástí ukázkových databází k této knize.
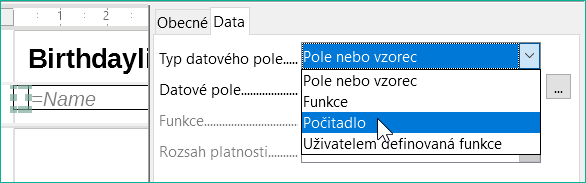
Obrázek 33: Nastavení vlastnosti Typ datového pole textového pole na hodnotu Counter
Potřebujeme název funkce pro podmíněné formátování. Skutečný čítač se ve výrazu nemusí objevit. Název lze přečíst přímo z pole. Pokud je pole opět smazáno, je název funkce přístupný pomocí Zobrazení > Navigátor sestavy (viz obrázek 34).
Obrázek 34: Název funkce zvýrazněný v navigátoru sestavy
Nyní je třeba použít čítač, aby každé textové pole mělo svůj vlastní formát, jak je znázorněno na obrázku 35. Podmínkou je výraz, který není přímo spojen s polem. Proto je nastaven jako Podmínka 1 > Výraz je > MOD([CounterReport];2)>0. MOD vypočítá zbytek po dělení. Pro všechna lichá čísla je větší než 0; pro sudá čísla je to přesně 0. Řádkům 1, 3 a 5 bude proto přiřazen tento formát.
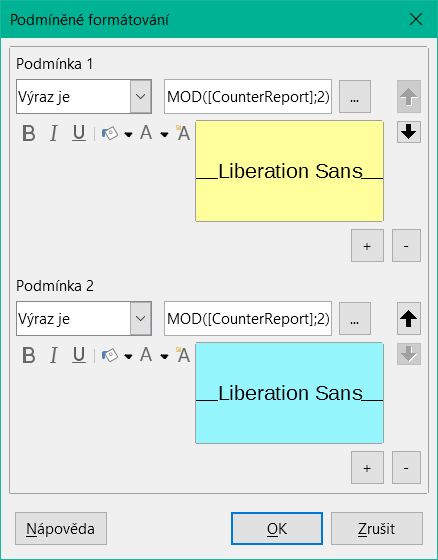
Obrázek 35: Podmíněné formátování pro střídání barev mezi sousedními řádky
Druhá podmínka je formulována přesně opačně a je jí přiřazen odpovídající formát. Ve skutečnosti by bylo možné tuto druhou podmínku vynechat a ve vlastnostech každého pole nastavit výchozí formát. Podmíněný formát zadaný v první podmínce by pak nahradil toto výchozí nastavení, kdykoli by byla podmínka splněna.
Vzhledem k tomu, že podmíněný formát přepíše veškeré výchozí formátování, je třeba zarovnání textu pro tento formát zahrnout pomocí nastavení znaků uvedených na obrázku 36.
Obrázek 36: Použití dialogu Nastavení znaků pro zarovnání textu
Zde mají být písmena zarovnána svisle na střed na barevné textové pole. Vodorovné zarovnání je standardní, ale je třeba přidat odsazení, aby se písmena netlačila na sebe na levé straně textového pole.
Pokusy s přidáváním mezer do obsahu dotazu nebo vzorce nevedly ke správnému odsazení textu. Úvodní mezery se jednoduše vyříznou.
Obrázek 37: Použití samostatného textového pole k dosažení konzistentního odsazení
Úspěšnější metodou je umístění textového pole před vlastní text, ale bez vazby na datové pole. Toto textové pole je podmíněně formátováno stejným způsobem jako ostatní, takže se při tisku objeví konzistentní viditelné odsazení (viz obrázek 37).
Pomocí chytrých technik dotazování můžeme vytvořit sestavu s více sloupci tak, aby vodorovná posloupnost odpovídala po sobě jdoucím záznamům, jak je znázorněno na obrázku 38:
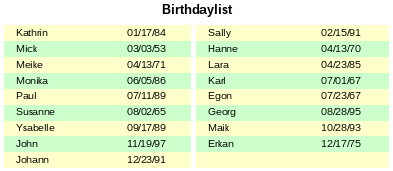
Obrázek 38: Příklad zobrazující dvousloupcový seznam narozenin
První záznam se vloží do levého sloupce, druhý do pravého. Záznamy jsou řazeny podle pořadí narozenin v rámci roku.
Třídění podle data narození způsobuje, že dotaz pro tuto zprávu je poměrně dlouhý. Pokud by se třídění provádělo podle primárního klíče základní tabulky, bylo by mnohem kratší. Kritérium třídění používá opakující se blok textu, který je vysvětlen níže.
Zde je dotaz, který je základem této sestavy:
SELECT "T1"."name" "name1", "T1"."birthday" "birthday1", "T2"."name" "name2", "T2"."birthday" "birthday2"
FROM
( SELECT "name", "birthday", "rowsNr" AS "row" FROM
( SELECT "a".*,
( SELECT COUNT( "ID" ) FROM "birthdays" WHERE
RIGHT( '0' || MONTH( "birthday" ), 2 ) ||
RIGHT( '0' || DAY( "birthday" ), 2 ) || "ID"
<= RIGHT( '0' || MONTH( "a"."birthday" ), 2 ) ||
RIGHT( '0' || DAY( "a"."birthday" ), 2 ) || "a"."ID" )
AS "rowsNr" FROM "birthdays" AS "a" )
WHERE MOD( "rowsNr", 2 ) > 0 )
AS "T1"
LEFT JOIN
( SELECT "name", "birthday", "rowsNr" - 1 AS "row" FROM
( SELECT "a".*,
( SELECT COUNT( "ID" ) FROM "birthdays" WHERE
RIGHT( '0' || MONTH( "birthday" ), 2 ) ||
RIGHT( '0' || DAY( "birthday" ), 2 ) || "ID"
<= RIGHT( '0' || MONTH( "a"."birthday" ), 2 ) ||
RIGHT( '0' || DAY( "a"."birthday" ), 2 ) || "a"."ID" )
AS "rowsNr"
FROM "birthdays" AS "a" )
WHERE MOD( "rowsNr", 2 ) = 0 )
AS "T2"
ON "T1"."row" = "T2"."row"
ORDER BY "T1"."row"
V tomto dotazu jsou dva stejné poddotazy. První dva sloupce se vztahují k poddotazu s aliasem T1 a poslední dva k poddotazu T2.
Poddotazy poskytují kromě polí v tabulce Birthdays další pole (rowsNr), které umožňuje rozlišovat řádky a třídit záznamy. Hlavní dotaz to využívá spolu s možností číslování řádků v dotazech (viz kapitola 5, Dotazy).
RIGHT( '0' || MONTH( "birthday" ), 2 ) || RIGHT( '0' || DAY( "birthday" ), 2 ) || "ID"
Tento vzorec umožňuje vytvořit jedinečnou posloupnost záznamů. Vzhledem k tomu, že záznamy příkladu mají být seřazeny podle data, bylo by snadné si myslet, že při porovnávání by se mělo použít pouze datum. V praxi je to obtížnější, protože nezáleží na samotných datech narození, ale na jejich pořadí v rámci jednoho roku. Další problémy způsobují shodné hodnoty dat, které brání vytvoření jedinečné posloupnosti. Třídění se tedy provádí nejen podle měsíce a dne, ale také podle jedinečného primárního klíče. A aby se zabránilo tomu, že měsíc 10 bude před měsícem 2, je před každý měsíc při sestavování kritéria řazení umístěna úvodní nula pomocí | |; pokud má měsíc již 2 číslice, je tato nula následně odstraněna pomocí RIGHT( ... , 2 ).
SELECT COUNT("ID" ) zobrazí počet záznamů, jejichž kombinace měsíce, dne a primárního klíče je menší nebo rovna kombinaci pro aktuální záznam v tabulce Birthday. Zde máme korelační poddotaz (viz kapitola „Dotazy“).
MOD("rowsNr", 2 ) určuje, zda je toto číslo sudé nebo liché. MOD udává zbytek po dělení, v příkladu dělení dvěma. To způsobí, že rowsNr bude střídavě nabývat hodnot '1' a '0'. Tím se zase rozlišují dotazy pro T1 a T2.
V další úrovni dotazu T2 je řádek definován jako "rowsNr"-1. Tímto způsobem jsou T1 a T2 přímo srovnatelné.
T1 je propojen s T2 pomocí LEFT JOIN, takže všechna data v tabulce Birthdays jsou zobrazena i pro lichá čísla záznamů. Při kombinaci T1 a T2 lze nyní přímo odkazovat na skutečné řádky: "T1". "řádek" = "T2". "řádek".
Nakonec se celý obsah seřadí podle hodnoty řádek, která je stejná pro T1 a T2. Tuto funkci může sestava využít také přímo pomocí funkce seskupování, která je znázorněna na obrázku 39.
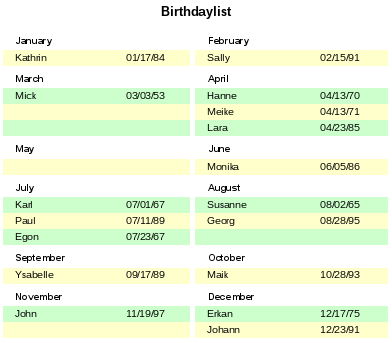
Obrázek 39: Příklad seznamu narozenin s použitím dvou sloupců pro zobrazení narozenin seskupených podle měsíců
Vytvořit techniky dotazování pro vytváření podsekcí kromě dvousloupcového formátu je mnohem složitější. V takových případech se prázdné řádky vyskytují uprostřed sestavy, zatímco v předchozím dvousloupcovém příkladu se vyskytovaly až na konci. Nástroj Návrhář sestav s tímto typem dotazu nepracuje dobře. Proto místo toho použijeme dva propojené pohledy.
Nejprve vytvoříme následující zobrazení:
SELECT "a"."ID", "a"."name", "a"."birthday",
MONTH( "a"."birthday" ) AS "monthnumber",
( SELECT COUNT( "ID" ) FROM "birthdays"
WHERE MONTH( "birthday" ) = MONTH( "a"."birthday" )
AND RIGHT( '0' || DAY( "birthday" ), 2 ) || "ID" <=
RIGHT( '0' || DAY( "a"."birthday" ), 2 ) || "a"."ID" )
AS "monthcounter"
FROM "birthdays" AS "a"
Jsou zahrnuta všechna pole tabulky Birthdays. Kromě toho je měsíc uveden jako číslo. Tabulce Birthdays je přidělen alias „a“, aby bylo možné k tabulce přistupovat pomocí odpovídajícího poddotazu.
Tento poddotaz spočítá všechny záznamy v měsíci, jejichž hodnoty data mají menší nebo stejné číslo dne. U stejných dat určuje primární klíč, které je na prvním místě. Tato technika je stejná jako v předchozím příkladu.
Pohled report_month_two_columns zpřístupňuje zobrazení monthnumber. Zde jsou uvedeny pouze výňatky z tohoto pohledu:
SELECT
"Tab1"."name" AS "name1",
"Tab1"."birthday" AS "birthday1",
1 AS "monthnumber1",
IFNULL("Tab1"."monthcounter",999) AS "monthcounter1",
'January' AS "month1",
"Tab2"."name" AS "name2",
"Tab2"."birthday" AS "birthday2",
2 AS "monthnumber2",
IFNULL("Tab2"."monthcounter",999) AS "monthcounter2",
'February' AS "month2"
FROM
(SELECT * FROM "monthnumber" WHERE "monthnumber" = 1) AS "Tab1"
RIGHT JOIN (SELECT * FROM "monthnumber" WHERE "monthnumber" = 2) AS
"Tab2" ON "Tab1"."monthcounter" = "Tab2"."monthcounter"
UNION
SELECT "Tab1"."name" AS "name1",
"Tab1"."birthday" AS "birthday1",
1 AS "monthnumber1",
IFNULL("Tab1"."monthcounter",999) AS "monthcounter1",
'January' AS "month1",
"Tab2"."name" AS "name2",
"Tab2"."birthday" AS "birthday2",
2 AS "monthnumber2",
IFNULL("Tab2"."monthcounter",999) AS "monthcounter2",
'February' AS "month2"
FROM
(SELECT * FROM "monthnumber" WHERE "monthnumber" = 1) AS "Tab1"
LEFT JOIN (SELECT * FROM "monthnumber" WHERE "monthnumber" = 2) AS
"Tab2" ON "Tab1"."monthcounter" = "Tab2"."monthcounter"
UNION
...
ORDER BY "monthnumber1", "monthcounter1", "monthcounter2"
Nejprve se z čísla měsíce načtou všechna data, pro která číslo měsíce = 1. Tomuto výběru je přiřazen alias Tab1. Současně se do tabulky Tab2 načtou všechna data pro číslo měsíce = 2. Tyto tabulky jsou propojeny pomocí RIGHT JOIN, takže se zobrazí všechny záznamy z Tab2, ale pouze ty záznamy z Tab1, které mají stejné počítadlo měsíce jako Tab2.
Sloupce zobrazení musí mít různé názvy, aby každý sloupec měl alias. Jako číslo měsíce je také přímo zadána jednička pro Tab1 a leden jako měsíc1. Tyto záznamy se objevují také v případě, že na kartě Tab1 není žádný záznam, ale na kartě Tab2 je stále několik záznamů. Pokud není k dispozici žádné počítadlo měsíců, zadá se hodnota 999. Protože je karta Tab1 propojena s kartou Tab2 pomocí RIGHT JOIN, může se stát, že pokud je na kartě Tab1 méně záznamů, zobrazí se místo nich prázdná pole. Vzhledem k tomu, že při pozdějším třídění by se takové záznamy dostaly před všechny záznamy s obsahem, je místo toho zadáno velmi vysoké číslo.
Vytvoření sloupců pro Tab2 je podobné. Zde však není nutné použít kód IFNULL("Tab2". "monthcounter",999), protože při RIGHT JOIN pro Tab2 se zobrazí všechny řádky z Tab2, ale již nebude platit, že by z Tab1 mohlo vzniknout více řádků než z Tab2.
Právě tento problém se řeší propojením dvou dotazů. Při použití UNION se zobrazí všechny záznamy z prvního dotazu a všechny záznamy z druhého dotazu. Záznamy z druhého dotazu se zobrazí pouze v případě, že nejsou totožné s předchozím záznamem. To znamená, že UNION funguje jako DISTINCT.
Pomocí UNION je znovu položen stejný dotaz, pouze Tab1 a Tab2 jsou nyní propojeny pomocí LEFT JOIN. To způsobí, že se zobrazí všechny záznamy z Tab1, i když Tab2 obsahuje méně záznamů než karta Tab1.
Pro měsíce 3 a 4, 5 a 6 atd. se použijí přesně ekvivalentní dotazy, které se opět připojí k předchozímu dotazu pomocí UNION.
Nakonec je výsledek zobrazení seřazen podle čísla monthnumber1, monthcounter1 a monthcounter2. Není třeba řadit podle monthnumber2, protože monthnumber1 již poskytuje stejnou posloupnost záznamů.
Nástroj Návrhář sestav někdy skrývá chyby, jejichž přesnou příčinu nelze dodatečně snadno určit. Zde je několik zdrojů chyb a užitečných protiopatření.
Pro simulaci prodeje zásob je vytvořena databáze. Dotaz vypočítá celkovou cenu z počtu zakoupených položek a jednotkové ceny.
SELECT "sales"."sum", "stock"."stock", "stock"."Price", "sales"."sum"*"stock"."Price" FROM "sales", "stock"
WHERE "sales"."stock_ID" = "stock"."ID"
Tento dotaz slouží jako základ sestavy. Pokud je však v sestavě vyvoláno pole "sales". "sum "*"stock". "Price", zůstane prázdné. Pokud je naopak v dotazu uveden alias, může k němu nástroj Návrhář sestav snadno přistupovat:
SELECT "sales"."sum", "stock"."stock", "stock"."Price", "sales"."sum"*"stock"."Price" AS "TPrice"
FROM "sales", "stock" WHERE "sales"."stock_ID" = "stock"."ID"
Pole nyní přistupuje k položce "Tprice" a zobrazuje odpovídající hodnotu.
Někdy se může stát, že sestava je připravena, ale pak není vytvořena nebo dokonce uložena. Zobrazí se poměrně neinformativní chybová zpráva:
„Sestavu nebylo možné vytvořit. Byla zachycena výjimka typu com.sun.star.lang.WrappedTargetExeption“.
Zde může být užitečné přečíst si doplňující informace připojené k sestavě. Pokud se zde objeví odkaz na SQL, znamená to, že nástroj Návrhář sestav nedokáže správně interpretovat kód SQL ve zdroji dat.
Zde může pomoci použít nástroj Navigátor sestavy a nastavit příkaz Data > Analyzovat SQL > Ne. Toto řešení však způsobí, že stávající skupiny přestanou fungovat.
Lepší způsob je použít jako základ sestavy spíše pohled než dotaz. Ten je nastaven tak, že se pro nástroj Návrhář sestav tváří jako tabulka a lze jej bez problémů upravovat. Dokonce i požadavky na třídění zobrazení fungují bez problémů.