
Příručka aplikace Base 7.3
Kapitola 8
Úlohy databáze
Tento dokument je chráněn autorskými právy © 2022 týmem pro dokumentaci LibreOffice. Přispěvatelé jsou uvedeni níže. Dokument lze šířit nebo upravovat za podmínek licence GNU General Public License (https://www.gnu.org/licenses/gpl.html), verze 3 nebo novější, nebo the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0/), verze 4.0 nebo novější.
Všechny ochranné známky uvedené v této příručce patří jejich vlastníkům.
|
Vasudev Narayanan |
Steve Fanning |
|
|
Robert Großkopf |
Pulkit Krishna |
Jost Lange |
|
Dan Lewis |
Hazel Russman |
Jochen Schiffers |
|
Jean Hollis Weber |
|
|
Jakékoli připomínky nebo návrhy k tomuto dokumentu prosím směřujte do fóra dokumentačního týmu na adrese https://community.documentfoundation.org/c/documentation/loguides/ (registrace je nutná) nebo pošlete e-mail na adresu: loguides@community.documentfoundation.org.
Poznámka
Vše, co napíšete do fóra, včetně vaší e-mailové adresy a dalších osobních údajů, které jsou ve zprávě napsány, je veřejně archivováno a nemůže být smazáno. E-maily zaslané do fóra jsou moderovány.
Vydáno Srpen 2022. Založeno na LibreOffice 7.3 Community.
Jiné verze LibreOffice se mohou lišit vzhledem a funkčností.
Některé klávesové zkratky a položky nabídek jsou v systému macOS jiné než v systémech Windows a Linux. V následující tabulce jsou uvedeny nejdůležitější rozdíly, které se týkají informací v této knize. Podrobnější seznam se nachází v nápovědě aplikace.
|
Windows nebo Linux |
Ekvivalent pro macOS |
Akce |
|
Výběr v nabídce Nástroje > Možnosti |
LibreOffice > Předvolby |
Otevřou se možnosti nastavení. |
|
Klepnutí pravým tlačítkem |
Ctrl + klepnutí a/nebo klepnutí pravým tlačítkem v závislosti na operačním systému počítače |
Otevře se místní nabídka. |
|
Ctrl (Control) |
⌘ (Command) |
Používá se také s dalšími klávesami. |
|
Alt |
⌥ (Option) |
Používá se také s dalšími klávesami. |
|
Ctrl + Q |
⌘ + Q |
Ukončí LibreOffice |
Tato kapitola popisuje některá řešení problémů, které se vyskytují u mnoha uživatelů databáze.
Filtrování dat pomocí grafického uživatelského rozhraní je popsáno v kapitole 3, Tabulky. Zde popíšeme řešení problému, na který upozornilo mnoho uživatelů: jak pomocí seznamových polí vyhledávat obsah polí v tabulkách, které se pak zobrazí filtrované v základní části formuláře a lze je upravovat.
Základem tohoto filtrování je upravitelný dotaz (viz kapitola 5, Dotazy) a další tabulka, ve které jsou uložena filtrovaná data. Dotaz zobrazí z podkladové tabulky pouze záznamy, které odpovídají hodnotám filtru. Pokud není zadána žádná hodnota filtru, dotaz zobrazí všechny záznamy.
Následující příklad vychází z ukázkové tabulky 'Media', která obsahuje mimo jiné následující pole: ID (primární klíč), Title, Category. Typy polí jsou INTEGER, VARCHAR a VARCHAR.
Nejprve potřebujeme ukázkovou tabulku „Filtr“. Tato tabulka obsahuje primární klíč a dvě filtrační pole (samozřejmě jich můžeme mít více, pokud chceme): ID (primární klíč), Filter_1, Filter_2. Protože pole příkladové tabulky „Media“, která má být filtrována, jsou typu VARCHAR, jsou pole Filter_1 a Filter_2 také tohoto typu. Pole ID může být nejmenší číselný typ TINYINT, protože tabulka Filter nikdy nebude obsahovat více než jeden záznam.
Můžeme také filtrovat pole, která se v ukázkové tabulce „Média“ vyskytují pouze jako cizí klíče. V takovém případě je třeba dát odpovídajícím polím v ukázkové tabulce „Filter“ typ odpovídající cizím klíčům, obvykle INTEGER.
Následující dotaz je určitě možné upravit:
SELECT * FROM "Media"
Zobrazí se všechny záznamy z ukázkové tabulky Media včetně primárního klíče.
SELECT * FROM "Media"
WHERE "Title" = IFNULL( ( SELECT "Filter_1" FROM "Filter" ), 'Title' )
Pokud pole Filtr není NULL, zobrazí se ty záznamy, jejichž Název je stejný jako Filter_1. Pokud je pole Filter NULL, použije se hodnota pole Title. Protože je Title stejný jako "Title", zobrazí se všechny záznamy. Tento předpoklad však neplatí, pokud je pole Title některého záznamu prázdné (obsahuje NULL). To znamená, že se nikdy nezobrazí ty záznamy, které nemají žádný záznam názvu (hodnotu v poli Title). Proto musíme dotaz vylepšit:
SELECT "Media".* , IFNULL( "Media"."Title", '' ) AS "T" FROM "Media"
WHERE "T" = IFNULL( ( SELECT "Filter_1" FROM "Filter" ), 'T' )
Tip
IFNULL(výraz, 'hodnota') vyžaduje, aby výraz měl stejný typ pole jako hodnota.
Pokud má výraz pole typu VARCHAR, použijeme jako hodnotu dvě jednoduché uvozovky.
Pokud je typ pole DATE, zadáme jako hodnotu datum, které není obsaženo v poli filtrované tabulky. Použijeme tento formát: {D 'RRRR-MM-DD'}.
Pokud se jedná o některý z typů číselných polí, použijeme pro hodnotu typ pole NUMERIC. Zadáme číslo, které se nevyskytuje v poli filtrované tabulky.
Tato varianta povede k požadovanému cíli. Místo přímého filtrování pole Title se filtruje pole, které nese alias T. Ani toto pole nemá žádný obsah, ale není NULL. V podmínkách se uvažuje pouze pole T. Všechny záznamy se tedy zobrazí, i když má pole Title hodnotu NULL.
Tento příkaz je k dispozici pouze přímo v jazyce SQL a nelze jej provést pomocí grafického uživatelského rozhraní. Aby jej bylo možné upravovat v grafickém uživatelském rozhraní, je třeba provést další úpravy:
SELECT "Media".* , IFNULL( "Media"."Title", '' ) AS "T"
FROM "Media"
WHERE "T" = IFNULL( ( SELECT "Filter_1" FROM "Filter" ), 'T' )
Pokud je nyní nastaven vztah tabulky k polím, je dotaz v grafickém uživatelském rozhraní upravitelný. Jako test můžeme vložit název do pole "Filter". "Filter_1".
Protože "Filter". "ID" nastaví hodnotu "0", záznam se uloží a filtrování je pochopitelné. Pokud je položka "Filter". "Filter_1" prázdná, grafické uživatelské rozhraní ji považuje za NULL. Při novém testu se zobrazí všechna média. V každém případě by měl být před vytvořením a otestováním formuláře do tabulky Filter zadán pouze jeden záznam s primárním klíčem. Musí se jednat pouze o jeden záznam, protože poddotazy, jak je uvedeno výše, mohou přenášet pouze jednu hodnotu.
Dotaz lze nyní rozšířit o filtrování dvou polí:
SELECT "Media".* , IFNULL( "Media"."Title", '' ) AS "T", IFNULL( "Media"."Category", '' ) AS "K"
FROM "Media"
WHERE "T" = IFNULL( ( SELECT "Filter_1" FROM "Filter" ), "T" ) AND "K" = IFNULL( ( SELECT "Filter_2" FROM "Filter" ), "K" )
Tím je tvorba upravitelného dotazu ukončena. Nyní základní dotaz pro dva seznamy:
SELECT DISTINCT "Title", "Title"
FROM "MediaExample" ORDER BY "Title" ASC
Pole se seznamem by mělo zobrazit hodnotu pole Title a poté také přenést tuto hodnotu do pole Filter_1 v tabulce Filter, která je základem formuláře. Také by se neměly zobrazovat žádné duplicitní hodnoty (podmínka DISTINCT). A celou věc je samozřejmě třeba seřadit do správného pořadí.
Pro pole Category je pak vytvořen odpovídající dotaz, který má zapsat jeho data do pole Filter_2 v tabulce Filter.
Pokud jedno z těchto polí obsahuje cizí klíč, je dotaz upraven tak, aby byl cizí klíč předán podkladové tabulce Filter.
Formulář se skládá ze dvou částí. Form 1 je formulář založený na tabulce Filter. Form 2 je formulář založený na dotazu. Form 1 nemá lištu navigace a cyklus je nastaven na Aktuální záznam. Kromě toho je vlastnost Povolit přidávání nastavena na Ne. První a jediný záznam pro tento formulář již existuje.
Form 1 obsahuje dva seznamy s příslušnými popisky. Listbox 1 vrací hodnoty pro Filter_1 a je propojeno s dotazem pro pole Title. Listbox 2 vrací hodnoty pro Filter_2 a vztahuje se k dotazu pro pole Category.
Form 2 obsahuje kontrolní pole tabulky, ve kterém lze uvést všechna pole z dotazu kromě polí T a K. Formulář by fungoval i v případě, že by tato pole byla přítomna. Jsou vynechána, aby nedocházelo k matoucí duplikaci obsahu polí. Form 2 navíc obsahuje tlačítko propojené s funkcí Aktualizovat formulář. Aby se zabránilo blikání obrazovky při každé změně formuláře v důsledku přítomnosti lišty navigace v jednom formuláři a ne ve druhém, lze do něj zabudovat další lištu navigace.
Po dokončení formuláře začíná testovací fáze. Při změně pole se seznamem se pomocí tlačítka na Form 2 uloží tato hodnota a aktualizuje se Form 2. To se nyní vztahuje k hodnotě, kterou poskytuje pole se seznamem. Filtrování lze provést zpětně výběrem prázdného pole v seznamu.
Hlavní rozdíl mezi vyhledáváním dat a filtrováním dat je v technice dotazování. Cílem je poskytnout v reakci na volné jazykové výrazy výsledný seznam záznamů, které mohou tyto aktuální výrazy obsahovat pouze částečně. Nejprve jsou popsány podobné přístupy k tabulce a formuláři.
Tabulka pro obsah vyhledávání může být stejná jako tabulka, která již obsahuje hodnoty filtru. Tabulka Filter je jednoduše rozšířena o pole s názvem Searchterm. V případě potřeby lze tedy přistupovat ke stejné tabulce a pomocí formulářů ji současně filtrovat a vyhledávat. Searchterm má typ pole VARCHAR.
Formulář je vytvořen stejně jako pro filtrování. Namísto pole se seznamem potřebujeme pole pro zadání textu pro hledaný výraz a také pole s popiskem a názvem Hledat. Pole pro hledaný výraz může být ve formuláři samostatné nebo společně s poli pro filtrování, pokud jsou obě funkce žádoucí.
Rozdíl mezi filtrováním a vyhledáváním spočívá v technice dotazování. Zatímco filtrování používá termín, který se již vyskytuje v základní tabulce, vyhledávání používá libovolné položky. (Koneckonců pole se seznamem je vytvořeno z obsahu tabulky.)
SELECT * FROM "Media"
WHERE "Title" = ( SELECT "Searchterm" FROM "Filter" )
Tento dotaz obvykle vede k prázdnému seznamu výsledků z těchto důvodů:
Při zadávání vyhledávacích výrazů lidé málokdy vědí úplně a přesně, o jaký název se jedná. Proto se nezobrazí správný název. Chceme-li najít knihu "The Hitchhiker's Guide to the Galaxy", stačí do pole pro vyhledávání zadat "Hitchhiker" nebo dokonce jen "Hit".
Pokud je pole Searchterm prázdné, zobrazí se pouze záznamy, u nichž není uveden žádný název. K tomu dojde pouze v případě, že položka nemá název nebo někdo nezadal její název.
Poslední podmínku lze odstranit, pokud je podmínka filtrování:
SELECT * FROM "Media"
WHERE "Title" = IFNULL( ( SELECT "Searchterm" FROM "Filter" ), "Title" )
Po tomto zpřesnění filtrování (co se stane, když je název NULL?) získáme výsledek, který více odpovídá očekávání. První podmínka však stále není splněna. Vyhledávání by mělo dobře fungovat, i když jsou k dispozici pouze dílčí znalosti. Technika dotazování proto musí používat podmínku LIKE:
SELECT * FROM "Media"
WHERE "Title" LIKE ( SELECT '%' || "Searchterm" ||'%' FROM "Filter" )
nebo ještě lépe:
SELECT * FROM "Media" WHERE "Title" LIKE IFNULL( ( SELECT '%' || "Searchterm" ||'%' FROM "Filter" ), "Title" )
LIKE ve spojení s % znamená, že se zobrazí všechny záznamy, které obsahují hledaný výraz. % je zástupný znak pro libovolný počet znaků před nebo za hledaným výrazem. Po sestavení této verze dotazu stále zůstávají různé otázky:
Pro vyhledávací výrazy se běžně používají malá písmena. Jaký výsledek dostanu, když místo "Hitch" zadám "hitch"?
Jaké další písemné konvence je třeba vzít v úvahu?
A co pole, která nejsou formátována jako textová pole? Můžeme vyhledávat data nebo čísla pomocí stejného vyhledávacího pole?
A co když chceme, jako v případě filtru, zabránit tomu, aby hodnoty NULL v poli způsobily zobrazení všech záznamů?
Následující varianta zahrnuje jednu nebo dvě z těchto možností:
SELECT * FROM "Media" WHERE
LOWER("Title") LIKE IFNULL( ( SELECT '%' || LOWER("Searchterm") ||'%' FROM "Filter" ), LOWER("Title") )
Podmínka změní hledaný výraz a obsah pole na malá písmena. To také umožňuje porovnávat celé věty.
SELECT * FROM "Media" WHERE
LOWER("Title") LIKE IFNULL( ( SELECT '%' || LOWER("Searchterm") ||'%' FROM "Filter" ), LOWER("Title") ) OR
LOWER("Category") LIKE ( SELECT '%' || LOWER("Searchterm") ||'%' FROM "Filter" )
Funkce IFNULL se musí vyskytnout pouze jednou, takže když Searchterm je NULL, dotazuje se LOWER("Title") LIKE LOWER("Title"). A protože název by měl být polem, které nemůže být NULL, zobrazí se v takových případech všechny záznamy. V případě vyhledávání ve více polích se tento kód samozřejmě odpovídajícím způsobem prodlouží. V takových případech je lepší použít makro, aby kód pokryl všechna pole najednou.
Funguje však tento kód i v případě polí, která nejsou textová? Ačkoli je podmínka LIKE skutečně přizpůsobena pro text, funguje také pro čísla, data a časy, aniž by bylo nutné ji jakkoli upravovat. Konverze textu tedy ve skutečnosti nemusí proběhnout. Pole s časem, které je směsí textu a čísel, však nemůže s výsledky vyhledávání interagovat – pokud není dotaz rozšířen tak, aby byl jeden hledaný výraz rozdělen na všechny mezery mezi textem a čísly. Tím se však dotaz značně rozšíří.
Tip
Dotazy, které se používají pro filtrování a vyhledávání záznamů, lze vložit přímo do formuláře.
Celou podmínku, která byla sestavena výše, lze zadat do filtru řádků pomocí vlastností formuláře.
SELECT * FROM "Media" WHERE "Title" = IFNULL( ( SELECT "Searchterm" FROM "Filter" ), "Title" )
se pak stane formulářem, který používá obsah tabulky Media.
V části "Filter" máme
("Media"."Title" = IFNULL( ( SELECT "Searchterm" FROM "Filter" ), "Media"."Title" ))
V zadání filtru dbáme na to, aby podmínka byla uvedena v závorkách a pracovala s pojmem "Tabulka". "Pole".
Výhodou této varianty je, že filtr lze zapínat a vypínat při otevřeném formuláři.
Vyhledávání pomocí LIKE je obvykle vyhovující pro databáze s poli obsahujícími text v množství, které lze snadno prohledat okem. Ale co pole Memo, která mohou obsahovat několik stránek textu? V takovém případě musí vyhledávání určit, kde lze zadaný text nalézt.
Pro přesné vyhledání textu má HSQLDB funkci LOCATE. Funkce LOCATE přijímá jako argument hledaný výraz (text, který chceme vyhledat). Můžeme také přidat pozici, která má být vyhledávána. Stručně: LOCATE(Hledaný výraz, Textové pole databáze, Pozice).
Následující výklad používá tabulku s názvem Table. Primární klíč se nazývá ID a musí být jedinečný. Existuje také pole s názvem Memo, které bylo vytvořeno jako pole typu Memo (LONGVARCHAR). Toto pole Memo obsahuje několik vět z této příručky.
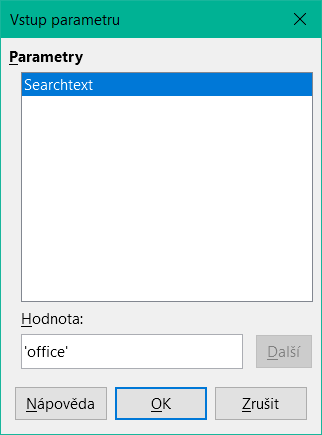
Obrázek 1: Zadání řetězce „office“ v dialogovém okně Zadávání parametrů
Poznámka
Snímky obrazovky pro tuto kapitolu pocházejí ze souboru Example_Autotext_Searchmark_Spelling.odb, který je součástí ukázkových databází pro tuto knihu.
Příklady dotazů jsou prezentovány jako dotazy s parametry. Hledaný text, který se má zadat, je vždy „office“.
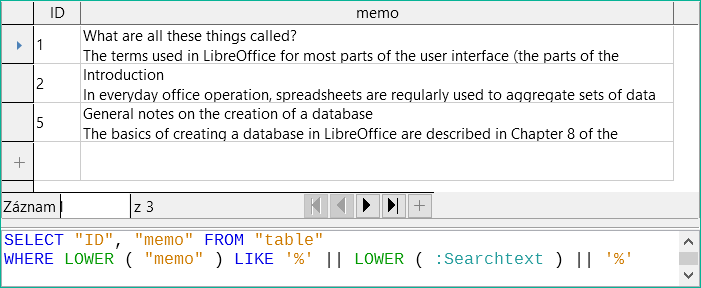
Obrázek 2: Výsledky hledání a kód SQL pomocí LIKE
Nejprve použijeme LIKE. LIKE lze použít pouze v podmínkách. Pokud je hledaný text kdekoli nalezen, zobrazí se odpovídající záznam. Porovnává se verze obsahu pole s malými písmeny pomocí LOWER("Memo") a verze textu hledání s malými písmeny pomocí LOWER(:Searchtext), aby se při hledání nerozlišovala velká a malá písmena. Čím delší je text v poli typu Memo, tím obtížnější je zobrazit výraz ve vyhledaném textu.
Funkce LOCATE nám přesněji ukáže, kde se hledaný výraz vyskytuje. V záznamech 1 a 2 se tento pojem nevyskytuje. V tomto případě LOCATE udává polohu '0'. Obrázek uvedený u záznamu 5 lze snadno potvrdit: řetězec „Office“ začíná na pozici 6. Samozřejmě by bylo možné zobrazit výsledky z LOCATE stejným způsobem jako u LIKE.
Ve sloupci Hits se výsledky hledání zobrazují přesněji. Předchozí dotaz byl použit jako základ pro tento dotaz. Díky tomu lze ve vnějším dotazu použít slovo "Position", místo aby bylo nutné pokaždé opakovat LOCATE(LOWER(:Searchtext),LOWER("Memo")). V zásadě se to neliší od uložení předchozího dotazu a jeho použití jako zdroje pro tento dotaz.
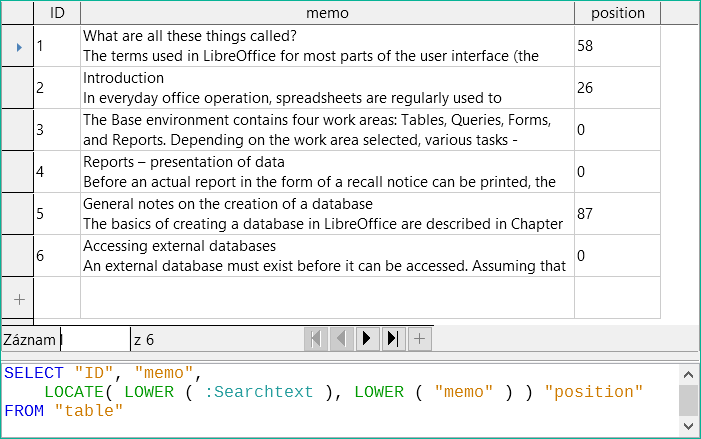
Obrázek 3: Výsledky hledání a kód SQL pomocí LOCATE (verze 1 – bez pokusu o zobrazení textu kolem místa shody)
"Position" = 0 znamená, že není žádný výsledek. V tomto případě se zobrazí zpráva '**not found**'.
"Position" < 10 znamená, že se hledaný výraz vyskytuje hned na začátku textu. 10 znaků lze snadno naskenovat pouhým okem. Proto se zobrazí celý text. Zde jsme místo SUBSTRING("Memo",1) mohli použít pouze "Memo".
Ve všech ostatních případech hledání se hledá mezera ' ' až do 10 znaků před hledaným výrazem. Zobrazený text nezačíná uprostřed slova, ale až za mezerou. SUBSTRING("Memo",LOCATE(' ', "Memo", "Position"-10)+1) zajistí, že text začíná na začátku slova, které leží maximálně 10 znaků před hledaným výrazem.
V praxi bychom chtěli použít více znaků, protože existuje mnoho delších slov a hledaný výraz se může nacházet v jiném slově, které má před sebou více než 10 znaků. LibreOffice obsahuje hledaný výraz „office“ s písmenem „O“ jako šestým znakem. Pokud by hledaný výraz byl „hand“, záznam 4 by byl pro zobrazení fatální. Obsahuje slovo „LibreOffice-Handbooks“, které má 12 znaků nalevo od slova „hand“. Pokud by se hledaly mezery maximálně 10 znaků vlevo, byl by prvním nalezeným znakem znak následující za čárkou. Ve sloupci „Hits“ se zobrazí jako začátek slova „the built-in help system...“.
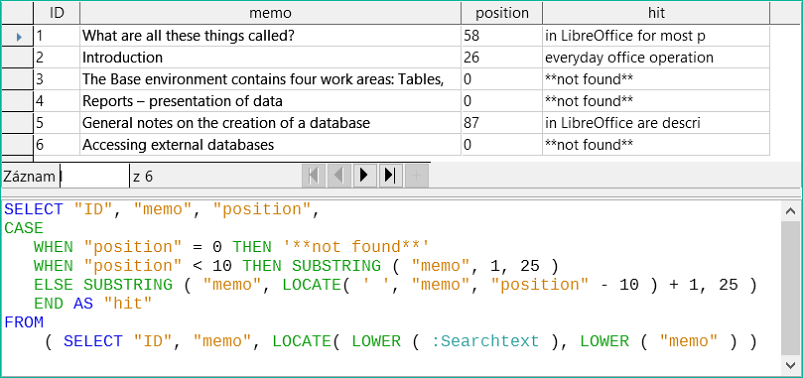
Obrázek 4: Výsledky hledání a kód SQL pomocí LOCATE (verze 2 – zobrazuje text kolem místa shody, ale ve sloupci shody se zobrazují částečná slova)
Technika dotazování je stejná jako u předchozího dotazu. Pouze délka zobrazovaného zásahu byla zkrácena na 25 znaků. Funkce SUBSTRING vyžaduje jako argumenty text, který má být vyhledán, dále počáteční pozici pro výsledek a jako třetí nepovinný argument délku textového řetězce, který má být zobrazen. Zde je pro demonstrační účely nastaven poměrně krátce. Výhodou zkrácení je, že se sníží nároky na ukládání velkého počtu záznamů a umístění je snadno viditelné. Viditelnou nevýhodou tohoto typu zkracování řetězců je, že se zkracování provádí striktně podle limitu 25 znaků, aniž by se bralo v úvahu, kde slova začínají.
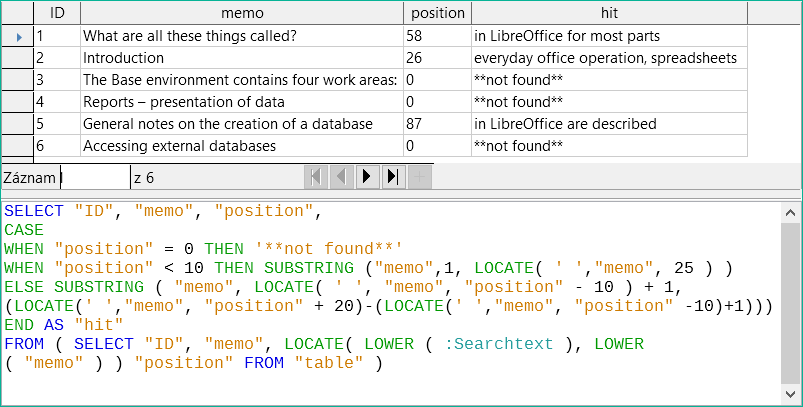
Obrázek 5: Výsledky hledání a kód SQL pomocí LOCATE (verze 3 – zobrazuje text kolem místa shody bez dílčích slov ve sloupci shody)
Zde hledáme od 25. znaku v poli „Hits“ po další znak mezery. Obsah, který se má zobrazit, leží mezi těmito dvěma pozicemi.
Je mnohem jednodušší, když se shoda objeví na začátku pole. Zde LOCATE(' ', "Memo",25) udává přesnou pozici, kde text začíná. Protože chceme, aby se text zobrazoval od začátku, odpovídá to přesně délce zobrazitelného výrazu.
Hledání prostoru následujícího za hledaným výrazem není o nic složitější, pokud výraz leží dále v poli. Hledání jednoduše začíná tam, kde se nachází shoda. Poté se počítá dalších 20 znaků, které mají následovat za všech okolností. Následující mezera je umístěna pomocí LOCATE(' ', "Memo", "Position "+20). Tímto způsobem se zadává pouze umístění v rámci pole jako celku, nikoli délka řetězce, který se má zobrazit. K tomu je třeba odečíst pozici, na které má začít zobrazování odpovídajícího textu. To již bylo nastaveno v rámci dotazu pomocí LOCATE(' ', "Memo", "Position"-10)+1. Tímto způsobem lze zjistit správnou délku textu.
Stejnou techniku lze použít i pro řetězení dotazů. Předchozí dotaz se nyní stane zdrojem dat pro nový dotaz. Byl vložen v závorce pod výraz FROM. Pouze pole jsou do jisté míry přejmenována, protože nyní existuje více pozic a shod. Kromě toho je další pozici přiřazen odkaz pomocí LOCATE(LOWER(:Searchtext),LOWER("Memo"), "Position01"+1). To znamená, že vyhledávání začíná znovu na pozici za předchozím odpovídajícím textem.
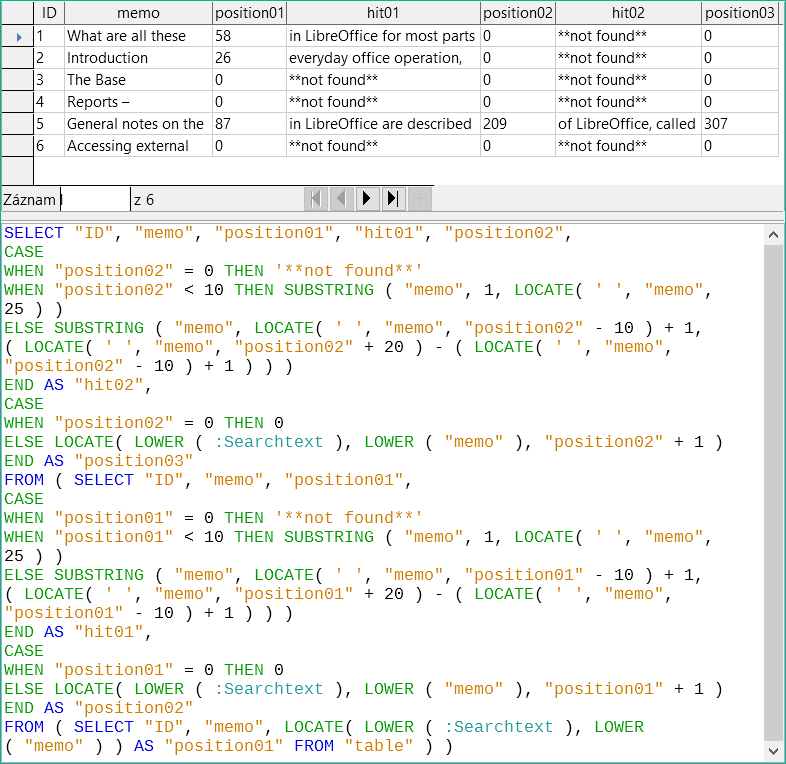
Obrázek 6: Výsledky hledání a kód SQL pomocí LOCATE (verze 4 – zobrazí až tři shody na záznam)
Nejvzdálenější dotaz nastaví odpovídající pole pro ostatní dva dotazy a také poskytne „hit02“ stejnou metodou, jaká byla použita pro „hit01“. Tento nejvzdálenější dotaz navíc určuje, zda existují další shody. Odpovídající pozice je uvedena jako „Pozice03“. Další shody má pouze záznam 5, který by mohl být nalezen v dalším poddotazu.
Zde uvedené skládání dotazů lze v případě potřeby provádět dále. Přidání každého nového vnějšího dotazu však představuje další zátěž pro systém. Bylo by nutné provést několik testů, aby se zjistilo, jak daleko je užitečné a reálné zajít. Kapitola 9, Makra, ukazuje, jak lze makra použít k vyhledání všech odpovídajících textových řetězců v poli pomocí formuláře.
Formuláře aplikace Base používají grafické ovládací prvky pro práci s obrázky. Pokud používáme interní databázi HSQLDB, jsou grafické ovládací prvky jediným způsobem, jak načíst obrázky z databáze bez použití maker. Lze je také použít jako odkazy na obrázky mimo databázový soubor.
Databáze vyžaduje tabulku, která splňuje alespoň následující podmínky:
Tabulka 1: Požadavky na tabulku pro načítání obrázků do databáze
|
Název pole |
Typ pole |
Popis |
|
ID |
Integer |
ID je primárním klíčem této tabulky. |
|
Image |
Image |
Obsahuje obrázek jako binární data. |
Primární klíč musí být přítomen, ale nemusí to být celé číslo. Měla by být přidána další pole, která přidávají informace o obrázku.
Data, která budou načtena do pole obrázku, nejsou v tabulce viditelná. Místo toho se zobrazí slovo <OBJECT>. Stejně tak nelze obrázky zadávat přímo do tabulky. Musíme použít formulář, který obsahuje grafický ovládací prvek. Po klepnutí se otevře grafický ovládací prvek, který zobrazí dialogové okno pro výběr souboru. Následně se zobrazí obrázek, který byl načten z vybraného souboru.
Obrázky, které mají být vloženy přímo do databáze, by měly být co nejmenší. Vzhledem k tomu, že aplikace Base neposkytuje žádný způsob (kromě použití maker), jak exportovat obrázky v jejich původní velikosti, má smysl používat pouze nezbytnou velikost, například pro tisk v sestavě. Původní snímky v rozsahu megapixelů jsou zcela zbytečné a zahlcují databázi. Po přidání pouze několika obrázků interní HSQLDB vyhodí Java.NullPointerException a nemůže již záznam uložit. I když obrázky nejsou tak velké, může se stát, že se databáze stane nepoužitelnou.
Obrázky by navíc neměly být integrovány do tabulek, které jsou určeny k vyhledávání. Máme-li například personální databázi a chceme-li do ní zahrnout obrázky pro použití v průkazech, je nejvhodnější uložit je do samostatné tabulky s cizím klíčem v hlavní tabulce. To znamená, že v hlavní tabulce lze vyhledávat podstatně rychleji, protože samotná tabulka nevyžaduje tolik paměti.
Díky pečlivě navržené struktuře složek je pohodlnější přistupovat k externím souborům přímo. Soubory mimo databázi mohou být libovolně velké, aniž by to mělo vliv na fungování samotné databáze. To však také znamená, že přejmenování složky ve vlastním počítači nebo na internetu může způsobit ztrátu přístupu k souboru.
Pokud nechceme načítat obrázky přímo do databáze, ale pouze na ně odkazovat, musíme provést malou změnu v předchozí tabulce:
Tabulka 2: Požadavky na tabulku pro odkaz na externí obrázky
|
Název pole |
Typ pole |
Popis |
|
ID |
Integer |
ID je primárním klíčem této tabulky. |
|
Image |
Text |
Obsahuje cestu k obrázku. |
Pokud je typ pole nastaven na text, grafický ovládací prvek na formuláři přenese cestu k souboru. K obrázku lze stále přistupovat pomocí grafického ovládání stejně jako k internímu obrázku.
Totéž nelze provést s dokumentem. Není možné ani načíst cestu, protože grafické ovládací prvky jsou určeny pro grafické obrázky a dialogové okno pro výběr souborů zobrazuje pouze soubory s grafickým formátem.
V případě obrázku lze obsah zobrazit alespoň v grafickém ovládacím prvku pomocí cesty k souboru. U dokumentu nelze zobrazit cestu, i když je uložena v tabulce. Nejprve musíme tabulku poněkud zvětšit, aby bylo vidět alespoň malé množství informací o dokumentu.
Tabulka 3: Požadavky na tabulku pro propojení s externími dokumenty
|
Název pole |
Typ pole |
Popis |
|
ID |
Integer |
ID je primárním klíčem této tabulky. |
|
Popis |
Text |
Popis dokumentu, výrazy pro vyhledávání |
|
Soubor |
Text |
Obsahuje cestu k dokumentu. |
Aby byla cesta k dokumentu viditelná, musíme do formuláře zabudovat pole pro výběr souboru.

Obrázek 7: Dialogové okno Vlastnosti (karta Obecné) pro pole pro výběr souboru
Pole pro výběr souboru nemá v dialogu vlastností žádnou kartu pro data. Není tedy vázán na žádné pole v podkladové tabulce.
Pomocí pole pro výběr souboru lze cestu zobrazit, ale nelze ji uložit. K tomu je nutný zvláštní postup, který je vázán na Události > Text změněn:
SUB PathRead(oEvent AS OBJECT)
DIM oForm AS OBJECT
DIM oField AS OBJECT
DIM oField2 AS OBJECT
DIM stUrl AS STRING
oField = oEvent.Source.Model
oForm = oField.Parent
oField2 = oForm.getByName("graphical_control")
IF oField.Text <> "" THEN
stUrl = ConvertToUrl(oField.Text)
oField2.BoundField.updateString(stUrl)
END IF
END SUB
Je jí předána událost, která proceduru spouští, a pomáhá najít formulář a pole, do kterého má být cesta uložena. Použití oEvent AS OBJECT zjednodušuje přístup, pokud chce jiný uživatel použít makro se stejným názvem v podformuláři. Zpřístupňuje pole pro výběr souboru prostřednictvím oEvent.Source.Model. Formulář je přístupný jako nadřízený pole pro výběr souboru. Název formuláře je proto irelevantní. Z formuláře je nyní přístupné pole s názvem „graphical_control“. Toto pole se obvykle používá k ukládání cest k souborům obrázků. V tomto případě se do něj zapíše adresa URL vybraného souboru. Aby bylo zajištěno, že adresa URL bude fungovat v souladu s konvencemi operačního systému, převede se text v poli pro výběr souboru do obecně platné podoby pomocí funkce ConvertToUrl.
Databázová tabulka nyní obsahuje cestu v absolutním formátu: file:///....
Pokud jsou položky cesty načítány pomocí grafického ovládání, získáme relativní cestu. Aby byla použitelná, je třeba ji vylepšit. Tento postup je mnohem zdlouhavější, protože zahrnuje porovnání vstupní a skutečné cesty.
Následující makro je vázáno na vlastnost „Text modified“ pole pro výběr souboru.
SUB PathRead
DIM oDoc AS OBJECT
DIM oDrawpage AS OBJECT
DIM oForm AS OBJECT
DIM oField AS OBJECT
DIM oField2 AS OBJECT
DIM arUrl_Start()
DIM ar()
DIM ar1()
DIM ar2()
DIM stText AS STRING
DIM stUrl_complete AS STRING
DIM stUrl_Text AS STRING
DIM stUrl AS STRING
DIM stUrl_cut AS STRING
DIM ink AS INTEGER
DIM i AS INTEGER
oDoc = thisComponent
oDrawpage = oDoc.Drawpage
oForm = oDrawpage.Forms.getByName("Form")
oField = oForm.getByName("graphical_control")
oField2 = oForm.getByName("filecontrol")
Nejprve se stejně jako ve všech procedurách deklarují proměnné. Poté se vyhledají pole, která jsou důležitá pro zadávání cest. Celý následující kód se pak provede pouze v případě, že v poli pro výběr souboru skutečně něco je, tj. nebylo vyprázdněno změnou záznamu.
IF oField2.Text <> "" THEN
arUrl_Start = split(oDoc.Parent.Url,oDoc.Parent.Title)
ar = split(ConvertToUrl(oFeld2.Text),"/")
stText = ""
Čte se cesta k databázovému souboru. To se provádí, jak je uvedeno výše, nejprve načtením celé adresy URL a jejím rozdělením do pole tak, aby první prvek pole obsahoval přímou cestu.
Poté se všechny prvky cesty nalezené v poli pro výběr souboru načtou do pole ar. Oddělovač je /. Takto to lze provést přímo v systému Linux. V systému Windows musí být obsah oField2 převeden na adresu URL, která jako oddělovač cesty použije lomítko (nikoli zpětné lomítko).
Účelem rozdělení je získat cestu k souboru jednoduchým odříznutím názvu souboru na konci. Proto se v dalším kroku opět sestaví cesta k souboru a vloží se do proměnné stText. Smyčka nekončí posledním prvkem pole ar, ale předchozím prvkem.
FOR i = LBound(ar()) TO UBound(ar()) - 1
stText = stText & ar(i) & "/"
NEXT
stText = Left(stText,Len(stText)-1)
arUrl_Start(0) = Left(arUrl_Start(0),Len(arUrl_Start(0))-1)
Konečné / je opět odstraněno, protože jinak by se v následujícím poli objevila prázdná hodnota, což by narušilo porovnávání cest. Pro správné porovnání musí být text převeden na správnou adresu URL začínající file:///. Nakonec se porovná cesta k databázovému souboru s cestou, která byla vytvořena.
stUrl_Text = ConvertToUrl(stText)
ar1 = split(stUrl_Text,"/")
ar2 = split(arUrl_Start(0),"/")
stUrl = ""
ink = 0
stUrl_cut = ""
Pole ar1ar2 se porovnává krok za krokem ve smyčce.
FOR i = LBound(ar2()) TO UBound(ar2())
IF i <= UBound(ar1()) THEN
Následující kód se provede pouze tehdy, pokud číslo i není větší než počet prvků v ar1. Pokud je hodnota v ar2 stejná jako odpovídající hodnota v ar1 a do této chvíle nebyla nalezena žádná nekompatibilní hodnota, je společný obsah uložen do proměnné, kterou lze nakonec od hodnoty cesty odříznout.
IF ar2(i) = ar1(i) AND ink = 0 THEN
stUrl_cut = stUrl_cut & ar1(i) & "/"
ELSE
Pokud je v některém bodě mezi oběma poli rozdíl, pak se pro každou odlišnou hodnotu přidá do proměnné stUrl znaménko pro přechod o jeden adresář výše.
stUrl = stUrl & "../"
ink = 1
END IF
Jakmile je index uložený v i větší než počet prvků v ar1, každá další hodnota v ar2 způsobí uložení dalšího ../ do proměnné stUrl.
ELSE
stUrl = stUrl & "../"
END IF
NEXT
stUrl_complete = ConvertToUrl(oFeld2.Text)
oFeld.boundField.UpdateString(stUrl & Right(stUrl_complete,Len(stUrl_complete)-Len(stUrl_cut)))
END IF
END SUB
Po dokončení smyčky ar2 jsme zjistili, zda a o kolik je soubor, ke kterému se má přistupovat, ve stromu výše než databázový soubor. Nyní lze z textu v poli pro výběr souboru vytvořit stUrl_complete. Obsahuje také název souboru. Nakonec se hodnota přenese do grafického ovládání. Hodnota URL začíná znakem stUrl, který obsahuje potřebný počet teček (../). Pak je začátek stUrl_complete, část, která se ukázala být stejná pro databázi i externí soubor, odříznut. Způsob rozřezání řetězce je uložen v stUrl_cut.
Propojené obrázky lze zobrazit přímo v grafickém ovládacím prvku. Větší displej by však lépe zobrazoval detaily.
Dokumenty nejsou v aplikaci Base běžně viditelné.
Aby bylo možné tento typ zobrazení provést, musíme opět použít makra. Toto makro se spouští pomocí tlačítka na formuláři, které obsahuje grafický ovládací prvek.
SUB View(oEvent AS OBJECT)
DIM oDoc AS OBJECT
DIM oForm AS OBJECT
DIM oField AS OBJECT
DIM oShell AS OBJECT
DIM stUrl AS STRING
DIM stField AS STRING
DIM arUrl_Start()
oDoc = thisComponent
oForm = oEvent.Source.Model.Parent
oField = oForm.getByName("graphical_control")
stUrl = oField.BoundField.getString
Grafický ovládací prvek je ve formuláři umístěn. Protože tabulka neobsahuje samotný obrázek, ale pouze cestu k němu uloženou jako textový řetězec, načte se tento text pomocí getString.
Poté se určí cesta k databázovému souboru. Soubor odb, kontejner pro formuláře, je přístupný pomocí oDoc.Parent. Celá adresa URL včetně názvu souboru se načte pomocí oDoc.Parent.Url. Název souboru je také uložen v oDoc.Parent.Title. Text je oddělen pomocí funkce split s názvem souboru jako oddělovačem. Jako první a jediný prvek pole je uvedena cesta k databázovému souboru.
arUrl_Start = split(oDoc.Parent.Url,oDoc.Parent.Title)
oShell = createUnoService("com.sun.star.system.SystemShellExecute")
stField = convertToUrl(arUrl_Start(0) + stUrl)
oShell.execute(stField,,0)
END SUB
Externí programy lze spouštět pomocí struktury com.sun.star.system.SystemShellExecute. Absolutní cesta k souboru, sestavená z cesty k databázovému souboru a interně uložené relativní cesty z databázového souboru, je předána externímu programu. Grafické rozhraní operačního systému určuje, který program bude zavolán k otevření souboru.
Příkaz oShell.execute přijímá tři argumenty. Prvním je spustitelný soubor nebo cesta k datovému souboru, který je systémem propojen s programem. Druhým je seznam argumentů pro program. Třetí je číslo, které určuje, jak se mají chyby hlásit. Možnosti jsou 0 (výchozí chybová zpráva), 1 (žádná zpráva) a 2 (povolit pouze otevření absolutních URL adres).
Při čtení v dokumentech je třeba vždy dodržovat následující podmínky:
Čím větší je počet dokumentů, tím je databáze těžkopádnější. Proto je pro rozsáhlé dokumenty vhodnější externí databáze než interní.
Stejně jako v případě obrázků nelze v dokumentech vyhledávat. Jsou uloženy jako binární data, a proto je lze vložit do pole obrázku.
Dokumenty načtené do interní databáze HSQLDB lze načíst pouze pomocí maker. Pomocí SQL dotazů to provést nelze.
Následující makra pro načítání a odesílání závisí na tabulce, která obsahuje popis dat a původní název souboru a také binární verzi souboru. Název souboru není automaticky ukládán spolu se souborem, ale může poskytnout užitečné informace o typu dat uložených v souboru, který má být načten. Teprve potom mohou soubor bezpečně číst jiné programy.
Tabulka obsahuje následující pole:
Tabulka 4: Požadavky na tabulku pro načítání dokumentů dovnitř a ven
|
Název pole |
Typ pole |
Popis |
|
ID |
Integer |
ID je primárním klíčem této tabulky. |
|
Popis |
Text |
Popis dokumentu, vyhledávací termíny atd. |
|
Soubor |
Image |
Obrázek nebo soubor v binární podobě. |
|
Filename |
Text |
Název souboru včetně jeho přípony. Důležité pro další čtení. |
Formulář pro načítání a odesílání souborů vypadá takto:
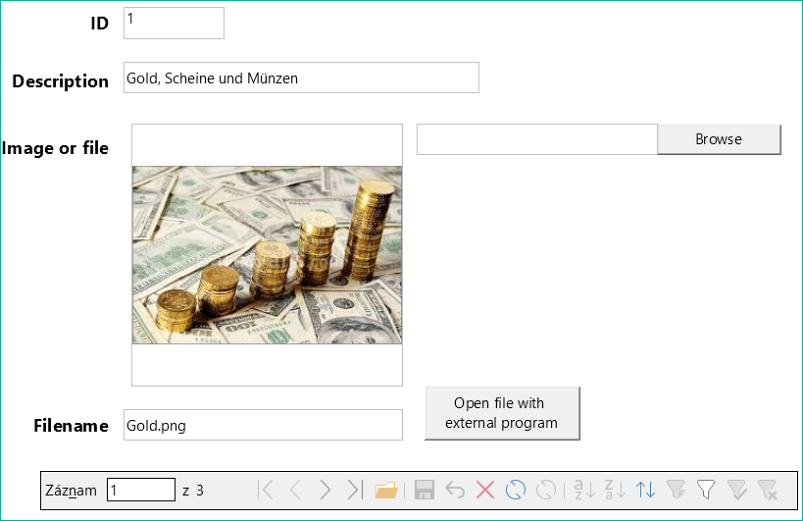
Obrázek 8: Formulář pro načítání souborů dovnitř a ven
Pokud jsou v databázi přítomny soubory obrázků, lze je zobrazit v grafickém ovládacím prvku formuláře. Všechny ostatní typy souborů jsou skryté.
Následující makro pro načtení souboru je spuštěno příkazem Vlastnosti: Výběr souboru → Události → Text změněn.
SUB FileInput_withName(oEvent AS OBJECT)
DIM oForm AS OBJECT
DIM oField AS OBJECT
DIM oField2 AS OBJECT
DIM oField3 AS OBJECT
DIM oStream AS OBJECT
DIM oSimpleFileAccess AS OBJECT
DIM stUrl AS STRING
DIM stName AS STRING
oField = oEvent.Source.Model
oForm = oField.Parent
oField2 = oForm.getByName("txt_filename")
oField3 = oForm.getByName("graphical_control")
IF oField.Text <> "" THEN
stUrl = ConvertToUrl(oField.Text)
ar = split(stUrl,"/")
stName = ar(UBound(ar))
oField2.BoundField.updateString(stName)
oSimpleFileAccess = createUnoService("com.sun.star.ucb.SimpleFileAccess")
oStream = oSimpleFileAccess.openFileRead(stUrl)
oField3.BoundField.updateBinaryStream(oStream, oStream.getLength())
END IF
END SUB
Vzhledem k tomu, že spouštěcí událost makra poskytuje název jiného pole formuláře, není nutné kontrolovat, zda se pole nachází v hlavním formuláři nebo v podformuláři. Je pouze nutné, aby všechna pole byla ve stejném tvaru.
V poli „txt_filename“ je uložen název souboru, který se má vyhledat. V případě obrázků je třeba tento název zadat ručně bez použití makra. Místo toho je název souboru určen pomocí adresy URL a automaticky zadán při načítání dat.
V poli „graphical_control“ jsou uložena aktuální data jak pro obrázky, tak pro ostatní soubory.
Kompletní cesta včetně názvu souboru se načte z pole pro výběr souboru pomocí oFeld.Text. Aby se zajistilo, že adresa URL nebude ovlivněna podmínkami specifickými pro operační systém, převede se načtený text do standardního formátu URL pomocí příkazu ConvertToUrl. Tato univerzálně platná adresa URL je rozdělena do pole. Oddělovač je /. Posledním prvkem cesty je název souboru. Ubound(ar) udává index tohoto posledního prvku. Skutečný název souboru pak lze přečíst pomocí ar(Ubound(ar)) a přenést do pole jako řetězec.
Pro samotné čtení souboru je vyžadována UnoService com.sun.star.ucb.SimpleFileAccess. Tato služba může číst obsah souboru jako datový proud. Ten je dočasně uložen v objektu oStream a poté vložen jako datový tok do pole vázaného na pole „File“ v tabulce. To vyžaduje zadání délky datového toku a objektu oStream.
Údaje jsou nyní uvnitř pole formuláře stejně jako při běžném zadávání. Pokud je však formulář v tomto okamžiku jednoduše uzavřen, data se neuloží. Uložení vyžaduje stisknutí tlačítka Uložit na liště navigace; k uložení dojde také automaticky při přechodu na další záznam.
Ve výše uvedené metodě bylo stručně zmíněno, že název souboru používaného pro vstup do grafického ovládání nelze přímo určit. Zde je makro pro určení tohoto názvu souboru, které odpovídá výše uvedenému formuláři. Název souboru nelze s jistotou určit pomocí události přímo vázané na grafický ovládací prvek. Makro se tedy spouští pomocí Vlastnosti formuláře > Události > Před záznamem.
SUB ImagenameRead(oEvent AS OBJECT)
oForm = oEvent.Source
IF InStr(oForm.ImplementationName, "ODatabaseForm") THEN
oField = oForm.getByName("graphical_control")
oField2 = oForm.getByName("txt_filename")
IF oField.ImageUrl <> "" THEN
stUrl = ConvertToUrl(oFeld.ImageUrl)
ar = split(stUrl,"/")
stName = ar(UBound(ar))
oField2.BoundField.updateString(stName)
END IF
END IF
END SUB
Před záznamem se provedou dvě implementace s různými názvy implementací. Formulář je nejsnáze přístupný pomocí implementace ODatabaseForm.
V grafickém ovládacím prvku lze adresu URL zdroje dat získat pomocí ImageUrl. Tato URL adresa je načtena, název souboru je určen pomocí předchozí procedury FileInput_withName a je přenesen do pole txt_filename.
Pokud po spuštění výše uvedeného makra přejdeme na další záznam, cesta k původnímu obrázku je stále k dispozici. Pokud je nyní pomocí pole pro výběr souboru načten jiný soubor než obrázek, název souboru pro obrázek se přepíše názvem tohoto souboru, pokud nepoužijeme následující makro.
Cestu nelze odstranit pomocí předchozího makra, protože soubor s obrázkem se načte až při ukládání záznamu. Odstraněním cesty v tomto bodě by se obrázek odstranil.
Makro se spouští pomocí Vlastnosti formuláře > Události > Po záznamu.
SUB ImagenameReset(oEvent AS OBJECT)
oForm = oEvent.Source
IF InStr(oForm.ImplementationName, "ODatabaseForm") THEN
oField = oForm.getByName("graphical_control")
IF oField.ImageUrl <> "" THEN
oField.ImageUrl = ""
END IF
END IF
END SUB
Stejně jako v proceduře „ImageRead“ se přistupuje k ovládacímu prvku grafiky. Pokud existuje položka ImageUrl, je odstraněna.
U negrafických souborů i obrázků původní velikosti je třeba stisknout tlačítko Otevřít soubor pomocí externího programu. Soubory v dočasné složce pak lze číst a zobrazovat pomocí programu spojeného s příponou souboru v operačním systému.
Makro se spouští pomocí Vlastnosti: Tlačítko > Události > Provést akci.
SUB FileDisplay_withName(oEvent AS OBJECT)
DIM oDoc AS OBJECT
DIM oDrawpage AS OBJECT
DIM oForm AS OBJECT
DIM oField AS OBJECT
DIM oField2 AS OBJECT
DIM oStream AS OBJECT
DIM oShell AS OBJECT
DIM oPath AS OBJECT
DIM oSimpleFileAccess AS OBJECT
DIM stName AS STRING
DIM stPath AS STRING
DIM stField AS STRING
oForm = oEvent.Source.Model.Parent
oField = oForm.getByName("graphical_control")
oField2 = oForm.getByName("txt_filename")
stName = oField2.Text
IF stName = "" THEN
stName = "file"
END IF
oStream = oField.BoundField.getBinaryStream
oPath = createUnoService("com.sun.star.util.PathSettings")
stPath = oPath.Temp & "/" & stName
oSimpleFileAccess = createUnoService("com.sun.star.ucb.SimpleFileAccess")
oSimpleFileAccess.writeFile(stPath, oStream)
oShell = createUnoService("com.sun.star.system.SystemShellExecute")
stField = convertToUrl(stPath)
oShell.execute(stField,,0)
END SUB
Pozice ostatních dotčených polí ve formuláři je dána tlačítkem. Pokud název souboru chybí, soubor se jednoduše pojmenuje „File“.
Obsah ovládacího prvku formuláře „graphical_control“ odpovídá obsahu pole File v tabulce. Čte se jako datový proud. Cesta k dočasné složce se používá jako cesta k těmto datům; lze ji nastavit pomocí Nástroje > Možnosti > LibreOffice > Cesty. Pokud mají být data následně použita k jiným účelům, a ne pouze zobrazena, lze je z této cesty zkopírovat. V rámci makra se soubor po úspěšném přečtení otevře přímo pomocí programu, který byl grafickým uživatelským rozhraním operačního systému vázán na příponu souboru.
Tyto úryvky kódu pocházejí z dotazů do poštovních konferencí. Vyvstávají konkrétní problémy, které by mohly být užitečné jako řešení pro vaše vlastní databázové experimenty.
Dotaz potřebuje vypočítat skutečný věk osoby z data narození. Viz také funkce v dodatku k této příručce Průvodce aplikací Base.
SELECT DATEDIFF('yy',"Birthdate",CURDATE()) AS "Age" FROM "Person"
Tento dotaz uvádí věk jako rozdíl v letech. Věk dítěte narozeného 31. prosince 2011 by se však 1. ledna 2012 počítal jako 1 rok, protože se jedná o přestupný rok. Musíme tedy vzít v úvahu také postavení dne v rámci roku. To je dostupné pomocí funkce DAYOFYEAR(). Porovnání provede jiná funkce.
SELECT CASEWHEN
(DAYOFYEAR("Birthdate") > DAYOFYEAR(CURDATE()),
DATEDIFF ('yy',"Birthdate",CURDATE())-1,
DATEDIFF ('yy',"Birthdate",CURDATE()))
AS "Age" FROM "Person"
Nyní získáme správný aktuální věk v letech.
CASEWHEN lze také použít k tomu, aby se text Birthday dnes objevil v jiném poli, pokud DAYOFYEAR("Birthdate") = DAYOFYEAR(CURDATE()).
Nyní se může objevit jemná námitka: "A co přestupné roky?". U osob narozených po 28. únoru se jedná o chybu jednoho dne. Při každodenním používání to není závažný problém, ale neměli bychom se snažit o přesnost?
CASEWHEN (
(MONTH("Birthdate") > MONTH(CURDATE())) OR
((MONTH("Birthdate") = MONTH(CURDATE())) AND (DAY("Birthdate") > DAY(CURDATE()))),
DATEDIFF('yy',"Birthdate",CURDATE())-1,
DATEDIFF('yy',"Birthdate",CURDATE()))
Výše uvedený kód tohoto cíle dosahuje. Pokud je měsíc data narození větší než aktuální měsíc, odečte funkce rozdílu roku jeden rok. Stejně tak se odečte jeden rok, pokud jsou oba měsíce stejné, ale den v měsíci pro datum narození je větší než den v aktuálním datu. Tento vzorec však není pro grafické uživatelské rozhraní srozumitelný. Tento dotaz úspěšně zpracuje pouze Přímý SQL příkaz , který by zabránil úpravě našeho dotazu. Dotaz však musí být editovatelný, takže zde je návod, jak grafické uživatelské rozhraní obelstít:
CASE
WHEN MONTH("Birthdate") > MONTH(CURDATE())
THEN DATEDIFF('yy',"Birthdate",CURDATE())-1
WHEN (MONTH("Birthdate") = MONTH(CURDATE()) AND DAY("Birthdate") > DAY(CURDATE()))
THEN DATEDIFF('yy',"Birthdate",CURDATE())-1
ELSE DATEDIFF('yy',"Birthdate",CURDATE())
END
Při této formulaci již grafické uživatelské rozhraní nereaguje chybovou zprávou. Věk je nyní uváděn přesně i v přestupných letech a dotaz je stále editovatelný.
Pomocí malého úryvku výpočtu můžeme z tabulky zjistit, kdo bude v následujících osmi dnech slavit narozeniny.
SELECT *
FROM "Table"
WHERE
DAYOFYEAR("Date") BETWEEN DAYOFYEAR(CURDATE()) AND
DAYOFYEAR(CURDATE()) + 7
OR DAYOFYEAR("Date") < 7 -
DAYOFYEAR(CAST(YEAR(CURDATE())||'-12-31' AS DATE)) +
DAYOFYEAR(CURDATE())
Dotaz zobrazí všechny záznamy, jejichž datum leží mezi aktuálním dnem roku a následujícími 7 dny.
Aby bylo i na konci roku uvedeno 8 dní, je třeba důkladně zkontrolovat den, kdy rok začal. Tato kontrola se provádí pouze pro čísla dnů, která jsou nejvýše o 7 dní pozdější než poslední číslo dne v aktuálním roce (obvykle 365) plus číslo dne v aktuálním datu. Pokud je aktuální datum vzdáleno od konce roku více než 7 dní, je součet <1. Žádný záznam v tabulce nemá takové datum, takže v takových případech není tato dílčí podmínka splněna.
Ve výše uvedeném vzorci budou přestupné roky dávat špatný výsledek, protože jejich data jsou posunuta o výskyt 29. února. Kód musí být rozsáhlejší, aby se této chybě předešlo:
SELECT *
FROM "Table"
WHERE
CASE
WHEN
DAYOFYEAR(CAST(YEAR("Date")||'-12-31' AS DATE)) = 366
AND DAYOFYEAR("Date") > 60 THEN DAYOFYEAR("Date") - 1
ELSE
DAYOFYEAR("Date")
END
BETWEEN
CASE
WHEN
DAYOFYEAR(CAST(YEAR(CURDATE())||'-12-31' AS DATE)) = 366
AND DAYOFYEAR(CURDATE()) > 60 THEN DAYOFYEAR(CURDATE()) - 1
ELSE
DAYOFYEAR(CURDATE())
END
AND
CASE
WHEN
DAYOFYEAR(CAST(YEAR(CURDATE())||'-12-31' AS DATE)) = 366
AND DAYOFYEAR(CURDATE()) > 60 THEN DAYOFYEAR(CURDATE()) + 6
ELSE
DAYOFYEAR(CURDATE()) + 7
END
OR DAYOFYEAR("Datum") < 7 -
DAYOFYEAR(CAST(YEAR(CURDATE())||'-12-31' AS DATE)) +
DAYOFYEAR(CURDATE())
Přestupný rok poznáme podle toho, že celkový počet dní je 366, nikoli 365. To se používá pro odpovídající určení.
Jednak je třeba u každé hodnoty data ověřit, zda leží v přestupném roce, a také správný počet 60. dne (31 dní v lednu a 29 dní v únoru). V tomto případě je třeba všechny následující hodnoty DAYOFYEAR pro datum zvýšit o 1. Pak bude 1. březen přestupného roku přesně odpovídat 1. březnu běžného roku.
Na druhou stranu je třeba otestovat, zda je aktuální rok (CURDATE()) skutečně přestupný. I zde je třeba zvýšit počet dní o 1.
Zobrazení koncové hodnoty pro následujících 8 dní také není tak jednoduché, protože rok stále není v dotazu zahrnut. Tuto podmínku by však bylo snadné přidat: YEAR("Date") = YEAR(CURDATE()) pro aktuální rok nebo YEAR("Date") = YEAR(CURDATE()) + 1 pro následující rok.
Při půjčování médií by knihovna mohla chtít znát přesný den, kdy má být médium vráceno. Interní HSQLDB neposkytuje funkci DATEADD(), která je k dispozici v mnoha externích databázích a také v interním Firebirdu. Zde je uveden nepřímý způsob, jak toho dosáhnout na omezený časový úsek.
Nejprve se vytvoří tabulka obsahující posloupnost dat pokrývající požadované časové období. Za tímto účelem se otevře program Calc a do pole A1 se vloží název „ID“ a do pole B1 „Date“. Do pole A2 zadáme 1 a do pole B2 počáteční datum, například 15. 1. 2015 (anglický formát 01/15/2015) Vybereme A2 a B2 a přetáhneme je dolů. Tím se vytvoří posloupnost čísel ve sloupci A a posloupnost dat ve sloupci B.
Poté je celá tato tabulka včetně nadpisů sloupců vybrána a importována do databáze Base: klepnutí pravým tlačítkem myši > Vložit > Název tabulky > Date. V části Možnosti klepneme na možnost Definice a data a na možnost Použít první řádek jako názvy sloupců. Všechny sloupce jsou přeneseny. Poté se ujistíme, že pole ID má typ Integer [INTEGER] a pole Date typ Date [DATE]. Primární klíč není nutný, protože záznamy nebudou později měněny. Protože nebyl definován primární klíč, je tabulka chráněna proti zápisu.
Tip
K vytvoření takového zobrazení můžeme použít také techniku dotazování. Pokud použijeme filtrační tabulku, můžeme dokonce kontrolovat počáteční datum a rozsah hodnot data.
SELECT DISTINCT CAST
( "Y"."Nr" + (SELECT "Year" FROM "Filter" WHERE "ID" = True) - 1 || '-' ||
CASEWHEN( "M"."Nr" < 10, '0' || "M"."Nr", '' || "M"."Nr" ) || '-' ||
CASEWHEN( "D"."Nr" < 10, '0' || "D"."Nr", '' || "D"."Nr" )
AS DATE ) AS "Date"
FROM "Nrto31" AS "D", "Nrto31" AS "M", "Nrto31" AS "Y"
WHERE "Y"."Nr" <= (SELECT "Year" FROM "Filter" WHERE "ID" = True) AND "M"."Nr" <= 12 AND "D"."Nr" <= 31
Toto zobrazení přistupuje k tabulce, která obsahuje pouze čísla od 1 do 31 a je chráněna proti zápisu. Další filtrační tabulka obsahuje počáteční rok a rozsah roků, které má zobrazení pokrýt. Z nich se sestaví datum a vytvoří se textový výraz pro datum (rok, měsíc, den), který lze následně převést na datum. HSQLDB přijímá všechny dny až do 31. dne v měsíci a řetězce jako 31. 02. 2015. Datum 31. 2. 2015 je však přeneseno jako datum 3. 3. 2015. Při přípravě zobrazení proto musíme použít funkci DISTINCT, abychom vyloučili duplicitní hodnoty dat.
Zde je účinný následující pohled:
SELECT "a"."Date",
(SELECT COUNT(*) FROM "View_date" WHERE "Date" <=
"a"."Date")
AS "lfdNr"
FROM "View_Date" AS "a"
Pomocí číslování řádků se hodnota data převede na číslo. Vzhledem k tomu, že data v zobrazení nelze odstranit, není třeba žádná další ochrana proti zápisu.
Pomocí dotazu nyní můžeme určit konkrétní datum, například datum za 14 dní:
SELECT "a"."Loan_Date",
(SELECT "Date" FROM "Date" WHERE "ID" =
(SELECT "ID" FROM "Date" WHERE "Date" = "a"."Loan_Date")+14)
AS "Returndate"
FROM "Loans" AS "a"
V prvním sloupci je uvedeno datum půjčky. K tomuto sloupci se přistupuje pomocí korelačního poddotazu, který je opět rozdělen do dvou dotazů. SELECT "ID" FROM "Date" poskytne hodnotu pole ID, která odpovídá datu vydání. K hodnotě se připočítává 14 dní. Výsledek je přiřazen poli ID vnějším poddotazem. Toto nové ID pak určuje, které datum se vloží do pole data.
Při zobrazení tohoto dotazu není automaticky rozpoznán typ data, takže je nutné použít formátování. Ve formuláři lze uložit odpovídající zobrazení, takže každý dotaz poskytne hodnotu data.
Přímá varianta určení hodnoty data je možná kratší cestou:
SELECT "Loan_Date",
DATEDIFF( 'dd', '1899-12-30', "Loan_Date" ) + 14
AS "Returndate"
FROM "Table"
Vrácenou číselnou hodnotu lze ve formuláři formátovat jako datum pomocí formátovaného pole. Zpřístupnění pro další zpracování SQL v dotazu však vyžaduje mnoho práce.
MySQL má funkci TIMESTAMPADD(). Podobná funkce v HSQLDB neexistuje. K sečtení nebo odečtení však lze použít interní číselnou hodnotu časového razítka pomocí formátovaného pole ve formuláři.
Na rozdíl od přidávání dnů k datu způsobují časy problém, který nemusí být na začátku zřejmý.
SELECT "DateTime"
DATEDIFF('ss', '1899-12-30', "DateTime" ) / 86400.0000000000 +
36/24 AS "DateTime+36hours"
FROM "Table"
Nový vypočtený čas je založen na rozdílu od nulového času systému. Při výpočtu data se jedná o datum 30. 12. 1899.
Poznámka
Nulté datum 30. 12. 1899 bylo údajně zvoleno proto, že rok 1900 nebyl na rozdíl od většiny let dělitelných čtyřmi přestupný. Značka „1“ interního výpočtu byla tedy přesunuta zpět na 31.12.1899, a nikoli na 1.1.1900.
Rozdíl je vyjádřen v sekundách, ale interní číslo počítá dny jako čísla před desetinnou čárkou a hodiny, minuty a sekundy jako desetinná místa. Protože den obsahuje 60*60*24 sekund, je třeba pro správný výpočet dnů a zlomků dnů vydělit počet sekund číslem 86400. Pokud má interní HSQLDB vůbec uvádět desetinná místa, musí být do výpočtu zahrnuta, takže místo 86400 musíme dělit 86400.0000000000. Desetinná místa v dotazu musí být oddělena desetinnou tečkou bez ohledu na místní zvyklosti. Výsledek bude mít za tečkou 10 desetinných míst.
K tomuto výsledku je třeba přičíst celkový počet hodin jako zlomek dne. Vypočtený údaj, vhodně naformátovaný, lze vytvořit v dotazu. Formátování se neuloží, ale lze je přenést ve správném formátu pomocí formátovaného pole ve formuláři nebo sestavě.
Pokud je třeba přidat minuty nebo sekundy, dbejme na to, aby byly uvedeny jako zlomky dne.
Pokud datum spadá do listopadu, prosince, ledna atd., nejsou s výpočtem žádné problémy. Zdá se, že jsou poměrně přesné: přičtením 36 hodin k časovému razítku 20.01.2015 13:00:00 získáme 22.01.2015 00:00:00. Pro datum 20.04.2015 13:00:00 je to ale jinak. Výsledek je 04/22/2015 00:00:00. Výpočet je špatný kvůli letnímu času. Hodina „ztracená“ nebo „získaná“ změnou času se nezohledňuje. V rámci jednoho časového pásma existují různé způsoby, jak získat „správný“ výsledek. Zde je jednoduchá varianta:
SELECT "DateTime"
DATEDIFF( 'dd', '1899-12-30', "DateTime" ) +
HOUR( "DateTime" ) / 24.0000000000 +
MINUTE( "DateTime" ) / 1440.0000000000 +
SECOND( "DateTime" ) / 86400.0000000000 +
36/24
AS "DateTime+36hours"
FROM "Table"
Místo počítání hodin, minut a sekund od počátku data se počítají od aktuálního data. Dne 20.5.2015 je čas 13:00, ale bez letního času by byl zobrazen jako 12:00. Funkce HOUR zohledňuje letní čas a jako hodinovou část času uvádí 13 hodin. Tu pak můžeme správně přidat do denní části. S minutami a sekundami se pracuje úplně stejně. Nakonec se hodiny navíc přičtou jako zlomek dne a vše se zobrazí jako vypočtené časové razítko pomocí formátování buněk.
Při tomto výpočtu je třeba mít na paměti dvě věci:
Při přechodu ze zimního času na letní se hodinové hodnoty nezobrazují správně. To lze opravit pomocí pomocné tabulky, která převezme data začátku a konce letního času a opraví hodinový počet. Poněkud komplikovaná záležitost.
Zobrazení časů je možné pouze u formátovaných polí. Výsledkem je desetinné číslo, nikoli časová značka, kterou by bylo možné uložit přímo do databáze. Buď se musí zkopírovat v rámci formuláře, nebo převést z desetinného čísla na časovou značku pomocí složitého dotazu. Zlomovým bodem převodu je hodnota data, protože se může jednat o přestupné roky nebo měsíce s různým počtem dní.
Namísto domácího deníku může databáze v počítači zjednodušit únavné sčítání výdajů na jídlo, oblečení, dopravu atd. Chceme, aby většina těchto údajů byla v databázi okamžitě viditelná, takže náš příklad předpokládá, že příjmy a výdaje budou uloženy jako podepsané hodnoty v jednom poli nazvaném Částka (Amount). V zásadě lze celou věc rozšířit tak, aby zahrnovala samostatná pole a příslušný součet pro každé z nich.
SELECT "ID", "Amount", (SELECT SUM("Amount") FROM "Cash" WHERE "ID" <= "a"."ID") AS "Balance" FROM "Cash" AS "a" ORDER BY "ID" ASC
Tento dotaz způsobí pro každý nový záznam přímý výpočet zůstatku běžného účtu. Dotaz přitom zůstává editovatelný, protože pole Balance je vytvořeno prostřednictvím korelujícího poddotazu. Dotaz závisí na automaticky vytvořeném primárním klíči ID pro výpočet stavu účtu. Zůstatky se však obvykle počítají denně. Potřebujeme tedy dotaz na datum.
SELECT "ID", "Date", "Amount", ( SELECT SUM( "Amount" ) FROM "Cash" WHERE "Date" <= "a"."Date" ) AS "Balance" FROM "Cash" AS "a" ORDER BY "Date", "ID" ASC
Výdaje se nyní zobrazují seřazené a sečtené podle data. Zbývá ještě otázka kategorie, protože chceme odpovídající zůstatky pro jednotlivé kategorie výdajů.
SELECT "ID", "Date", "Amount", "Acct_ID",
( SELECT "Acct" FROM "Acct" WHERE "ID" = "a"."Acct_ID" ) AS "Acct_name",
( SELECT SUM( "Amount" ) FROM "Cash" WHERE "Date" <= "a"."Date" AND "Acct_ID" = "a"."Acct_ID" ) AS "Balance",
( SELECT SUM( "Amount" ) FROM "Cash" WHERE "Date" <= "a"."Date" ) AS "Total_balance"
FROM "Cash" AS "a" ORDER BY "Date", "ID" ASC
Tím se vytvoří editovatelný dotaz, ve kterém se kromě vstupních polí (Date, Amount, Acct_ID) zobrazí společně název účtu, příslušný zůstatek a celkový zůstatek. Vzhledem k tomu, že korelační poddotazy jsou částečně založeny na předchozích položkách ("Date" <= "a". "Date"), projdou bez problémů pouze nové položky. Změny předchozího záznamu jsou zpočátku zjistitelné pouze v tomto záznamu. Má-li být později proveden výpočet závislý na dotazu, musí být dotaz aktualizován.
Pole s automatickým přírůstkem jsou v pořádku. Neříkají však s určitostí, kolik záznamů se v databázi nachází nebo kolik je jich skutečně k dispozici pro dotazování. Záznamy jsou často mazány a mnozí uživatelé se marně snaží zjistit, která čísla již neexistují, aby se průběžné číslo shodovalo.
SELECT "ID", ( SELECT COUNT( "ID" ) FROM "Table" WHERE "ID" <= "a"."ID" ) AS "Nr." FROM "Table" AS "a"
Pole ID je načteno a druhé pole je určeno korelačním poddotazem, který se snaží zjistit, kolik hodnot pole ID je menší nebo rovno aktuální hodnotě pole. Z toho se vytvoří číslo průběžného řádku.
Každý záznam, na který chceme tento dotaz použít, obsahuje pole. Chceme-li tento dotaz použít na záznamy, musíme nejprve do dotazu přidat tato pole. V klauzuli SELECT je můžeme umístit v libovolném pořadí. Pokud máme záznamy ve formuláři, musíme formulář upravit tak, aby data pro formulář pocházela z tohoto dotazu.
Například záznam obsahuje field1, field2 a field3. Úplný dotaz by tedy byl:
SELECT "ID", "field1", "field2", "field3", ( SELECT COUNT( "ID" ) FROM "Table" WHERE "ID" <= "a"."ID" ) AS "Nr." FROM "Table" AS "a"
Je možné také číslování pro odpovídající seskupení:
SELECT "ID", "Calculation", ( SELECT COUNT( "ID" ) FROM "Table" WHERE "ID"
<= "a"."ID" AND "Calculation" = "a"."Calculation" ) AS "Nr." FROM "Table" AS "a" ORDER BY "ID" ASC, "Nr." ASC
Zde jedna tabulka obsahuje různá vypočtená čísla. ("Calculation"). Pro každé vypočtené číslo je "Nr." vyjádřeno zvlášť vzestupně po seřazení podle pole ID. Tím se vytvoří číslování od 1 nahoru.
Má-li skutečné pořadí v dotazu souhlasit s čísly řádků, je třeba zmapovat vhodný typ řazení. Za tímto účelem musí mít pole řazení ve všech záznamech jedinečnou hodnotu. Jinak budou mít dvě uložená čísla stejnou hodnotu. To může být užitečné například při zobrazování pořadí v soutěži, protože shodné výsledky pak vedou ke společnému umístění. Aby bylo možné pořadí míst vyjádřit tak, že v případě společných pozic bude další hodnota vynechána, je třeba dotaz sestavit poněkud jinak:
SELECT "ID", ( SELECT COUNT( "ID" ) + 1 FROM "Table" WHERE "Time" < "a"."Time" ) AS "Place" FROM "Table" AS "a"
Vyhodnocují se všechny záznamy, pro které má pole Time menší hodnotu. To se týká všech sportovců, kteří dosáhli vítězného postu před současným sportovcem. K této hodnotě se přičte číslo 1. Tím se určí místo aktuálního sportovce. Pokud je čas shodný s časem jiného sportovce, umístí se společně. To umožňuje pořadí míst, jako je 1. místo, 2. místo, 2. místo, 4. místo.
Problematičtější by bylo, kdyby se kromě pořadí míst vyžadovala i čísla řádků. To by mohlo být užitečné, pokud by bylo třeba spojit několik záznamů do jednoho řádku.
SELECT "ID", ( SELECT COUNT( "ID" ) + 1 FROM "Table" WHERE "Time" < "a"."Time" ) AS "Place",
CASE WHEN
( SELECT COUNT( "ID" ) + 1 FROM "Table" WHERE "Time" = "a"."Time" ) = 1
THEN ( SELECT COUNT( "ID" ) + 1 FROM "Table" WHERE "Time" < "a"."Time" )
ELSE (SELECT ( SELECT COUNT( "ID" ) + 1 FROM "Table" WHERE "Time" < "a"."Time" ) + COUNT( "ID" ) FROM "Table" WHERE "Time" = "a"."Time" "ID" < "a"."ID"
END
AS "LineNumber" FROM "Table" AS "a"
Ve druhém sloupci je stále uvedeno pořadí míst. Ve třetím sloupci se nejprve zkontroluje, zda čáru s tímto časem překročila pouze jedna osoba. Pokud ano, pořadí míst se převede přímo na číslo řádku. V opačném případě se k umístění přidá další hodnota. Pro stejný čas ("Time" = "a". "Time") se přidá alespoň 1, pokud existuje další osoba s primárním klíčem ID, jejíž primární klíč je menší než primární klíč v aktuálním záznamu ("ID" < "a". "ID"). Tento dotaz tedy poskytuje stejné hodnoty pro pořadí míst, pokud neexistuje druhá osoba se stejným časem. Pokud existuje druhá osoba se stejným časem, ID určí, která osoba má menší číslo řádku.
Mimochodem, toto řazení podle čísla řádku může sloužit k jakémukoli účelu, který si uživatelé databáze přejí. Pokud je například řada záznamů řazena podle jména, nejsou záznamy se stejným jménem řazeny náhodně, ale podle svého primárního klíče, který je samozřejmě jedinečný. I tímto způsobem může číslování vést k třídění záznamů.
Číslování řádků je také dobrou předehrou pro spojování jednotlivých záznamů do jednoho záznamu. Pokud je dotaz na číslování řádků vytvořen jako pohled, lze na něj aplikovat další dotaz, aniž by způsobil nějaký problém. Jako jednoduchý příklad je zde opět první dotaz na číslování s jedním polem navíc:
SELECT "ID", "Name", ( SELECT COUNT( "ID" ) FROM "Table" WHERE "ID" <= "a"."ID" ) AS "Nr." FROM "Table" AS "a"
Z tohoto dotazu se vytvoří pohled View1. Dotaz lze použít například pro spojení prvních tří jmen do jednoho řádku:
SELECT "Name" AS "Name_1", ( SELECT "Name" FROM "View1" WHERE "Nr." = 2 ) AS "Name_2", ( SELECT "Name" FROM "View1" WHERE "Nr." = 3 ) AS "Name_3" FROM "View1" WHERE "Nr." = 1
Tímto způsobem lze několik záznamů převést do sousedních polí. Toto číslování probíhá jednoduše od prvního do posledního záznamu.
Pokud mají mít všechny tyto osoby stejné příjmení, lze to provést takto:
SELECT "ID", "Name", "Surname", ( SELECT COUNT( "ID" ) FROM "Table" WHERE "ID" <= "a"."ID" AND "Surname" = "a"."Surname") AS "Nr." FROM "Table" AS "a"
Po vytvoření zobrazení lze sestavit rodinu.
SELECT "Surname", "Name" AS "Name_1", ( SELECT "Name" FROM "View1" WHERE "Nr." = 2 AND "Surname" = "a"."Surname") AS "Name_2", ( SELECT "Name" FROM "View1" WHERE "Nr." = 3 AND "Surname" = "a"."Surname") AS "Name_3" FROM "View1" AS "a" WHERE "Nr." = 1
V adresáři tak mohou být shromážděni všichni členové jedné rodiny ("Surname"), takže při odesílání dopisu je třeba každou adresu zohlednit pouze jednou, ale jsou v ní uvedeni všichni, kteří mají dopis obdržet.
Zde musíme být opatrní, protože nechceme, aby se funkce donekonečna opakovala ve smyčce. Dotaz ve výše uvedeném příkladu omezuje počet paralelních záznamů, které mají být převedeny do polí, na 3. Tento limit byl zvolen záměrně. Žádná další jména se nezobrazí, i když je hodnota "Nr." větší než 3.
V několika případech je takové omezení jasně pochopitelné. Pokud například vytváříme kalendář, řádky mohou představovat týdny v roce a sloupce dny v týdnu. Stejně jako v původním kalendáři určuje obsah pole pouze datum, číslování řádků slouží k průběžnému číslování dnů každého týdne a týdny v roce se pak stávají záznamy. To vyžaduje, aby tabulka obsahovala pole data s průběžnými daty a pole pro události. Také nejstarší datum vždy vytvoří „Nr.“. = 1. Pokud tedy chceme, aby kalendář začínal v pondělí, musí být nejbližší datum v pondělí. Sloupec 1 je pak pondělí, sloupec 2 úterý atd. Poddotaz pak končí na "Nr.". = 7. Tímto způsobem lze zobrazit všech sedm dní v týdnu vedle sebe a vytvořit odpovídající zobrazení kalendáře.
Někdy je užitečné sestavit několik polí pomocí dotazu a oddělit je zalomením řádku, například při načítání kompletní adresy do sestavy.
Zalomení řádku v dotazu je reprezentováno znakem Char(13). Příklad:
SELECT "Firstname"||' '||"Surname"||Char(13)||"Road"||Char(13)||"Town" FROM "Table"
Tím se získá:
Firstname Surname
Road
Town
Takový dotaz s číslováním řádků do 3 umožňuje tisknout adresní štítky ve třech sloupcích vytvořením sestavy. Číslování je v této souvislosti nutné, aby bylo možné v jednom záznamu umístit tři adresy vedle sebe. Jen tak zůstanou při čtení do zprávy vedle sebe.
V některých operačních systémech je nutné do kódu vedle char(13) zahrnout i char(10).
SELECT "Firstname"||' '||"Surname"||Char(13)||Char(10)||"Street"||Char(13)||Char(10)||"Town" FROM "Table"
Pro ostatní databáze a novější verze HSQLDB je k dispozici příkaz Group_Concat(). Lze jej použít ke seskupení jednotlivých polí v záznamu do jednoho pole. Je tedy například možné ukládat křestní jména a příjmení do jedné tabulky a pak prezentovat data tak, že v jednom poli jsou příjmení zobrazena jako rodová jména, zatímco druhé pole obsahuje všechna příslušná křestní jména postupně oddělená čárkami.
Tento příklad je v mnoha ohledech podobný číslování řádků. Seskupení do společného pole je jakýmsi doplňkem.
Tabulka 5: Názvy osob, které mají být seskupeny
|
Surname |
Firstname |
|
Müller |
Karin |
|
Schneider |
Gerd |
|
Müller |
Egon |
|
Schneider |
Volker |
|
Müller |
Monika |
|
Müller |
Rita |
je dotazem převedeno na:
Tabulka 6: Jména seskupená podle příjmení
|
Surname |
Firstnames |
|
Müller |
Karin, Egon, Monika, Rita |
|
Schneider |
Gerd, Volker |
Tento postup lze v rámci možností vyjádřit v HSQLDB. Následující příklad se týká tabulky s názvem Name s poli ID, Firstname a Surname. Následující dotaz je nejprve spuštěn na tabulku a uložen jako pohled s názvem View_Group.
SELECT "Surname", "Firstname", ( SELECT COUNT( "ID" ) FROM "Name" WHERE "ID" <= "a"."ID" AND "Surname" = "a"."Surname" ) AS "GroupNr" FROM "Name" AS "a"
V kapitole Dotazy si můžeme přečíst, jak tento dotaz přistupuje k obsahu pole ve stejném řádku dotazu. Výsledkem je vzestupně číslovaná sekvence seskupená podle Surname. Toto číslování je nutné pro následující dotaz, takže v příkladu je uvedeno maximálně 5 křestních jmen.
SELECT "Surname",
( SELECT "Firstname" FROM "View_Group" WHERE "Surname" = "a"."Surname" AND "GroupNr" = 1 ) ||
IFNULL( ( SELECT ', ' || "Firstname" FROM "View_Group" WHERE "Surname" = "a"."Surname" AND "GroupNr" = 2 ), '' ) ||
IFNULL( ( SELECT ', ' || "Firstname" FROM "View_Group" WHERE "Surname" = "a"."Surname" AND "GroupNr" = 3 ), '' ) ||
IFNULL( ( SELECT ', ' || "Firstname" FROM "View_Group" WHERE "Surname" = "a"."Surname" AND "GroupNr" = 4 ), '' ) ||
IFNULL( ( SELECT ', ' || "Firstname" FROM "View_Group" WHERE "Surname" = "a"."Surname" AND "GroupNr" = 5 ), '' )
AS "Firstnames"
FROM "View_Group" AS "a"
Pomocí dílčích dotazů se postupně vyhledají a zkombinují křestní jména členů skupiny. Od druhého poddotazu musíme zajistit, aby hodnoty „NULL“ nenastavily celou kombinaci na hodnotu „NULL“. Proto se zobrazí výsledek '', a ne 'NULL'.