
Příručka aplikace Base 7.3
Kapitola 10
Údržba databáze
Tento dokument je chráněn autorskými právy © 2022 týmem pro dokumentaci LibreOffice. Přispěvatelé jsou uvedeni níže. Dokument lze šířit nebo upravovat za podmínek licence GNU General Public License (https://www.gnu.org/licenses/gpl.html), verze 3 nebo novější, nebo the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0/), verze 4.0 nebo novější.
Všechny ochranné známky uvedené v této příručce patří jejich vlastníkům.
|
Pulkit Krishna |
Steve Fanning |
Vasudev Narayanan |
|
Robert Großkopf |
Pulkit Krishna |
Jost Lange |
|
Dan Lewis |
Hazel Russman |
Jean Hollis Weber |
Jakékoli připomínky nebo návrhy k tomuto dokumentu prosím směřujte do fóra dokumentačního týmu na adrese https://community.documentfoundation.org/c/documentation/loguides/ (registrace je nutná) nebo pošlete e-mail na adresu: loguides@community.documentfoundation.org.
Poznámka
Vše, co napíšete do fóra, včetně vaší e-mailové adresy a dalších osobních údajů, které jsou ve zprávě napsány, je veřejně archivováno a nemůže být smazáno. E-maily zaslané do fóra jsou moderovány.
Vydáno Srpen 2022. Založeno na LibreOffice 7.3 Community.
Jiné verze LibreOffice se mohou lišit vzhledem a funkčností.
Některé klávesové zkratky a položky nabídek jsou v systému macOS jiné než v systémech Windows a Linux. V následující tabulce jsou uvedeny nejdůležitější rozdíly, které se týkají informací v této knize. Podrobnější seznam se nachází v nápovědě aplikace.
|
Windows nebo Linux |
Ekvivalent pro macOS |
Akce |
|
Výběr v nabídce Nástroje > Možnosti |
LibreOffice > Předvolby |
Otevřou se možnosti nastavení. |
|
Klepnutí pravým tlačítkem |
Ctrl + klepnutí a/nebo klepnutí pravým tlačítkem v závislosti na operačním systému počítače |
Otevře se místní nabídka. |
|
Ctrl (Control) |
⌘ (Command) |
Používá se také s dalšími klávesami. |
|
Alt |
⌥ (Option) |
Používá se také s dalšími klávesami. |
|
Ctrl+Q |
⌘ + Q |
Ukončí LibreOffice |
Dynamické databáze – zejména ty, které často mažou a mění data – mají dva problematické negativní efekty. Za prvé, databáze se neustále zvětšuje, i když ve skutečnosti nemusí obsahovat více dat. Za druhé, automaticky vytvořený primární klíč se nadále inkrementuje bez ohledu na to, jaká je hodnota dalšího potřebného klíče. V této kapitole jsou popsány důležité úkoly údržby databáze, které je třeba vzít v úvahu pro dobrý výkon a správu.
Databáze HSQLDB se chovají tak, že zachovávají úložný prostor i pro smazané záznamy. Databáze naplněné testovacími daty, zejména obrázky, si zachovávají stejnou velikost, i když jsou všechny tyto záznamy následně odstraněny. Důvodem je vlastnost primárních klíčů každé tabulky. Soubor databázových dokumentů obsahuje poslední hodnotu použitou pro každý primární klíč. Při vytvoření záznamu v tabulce se přiřadí další hodnota klíče.
Aby se uvolnilo místo v úložišti, je třeba přepsat záznamy v databázi (tabulky, popisy tabulek atd.). To lze provést otevřením každé tabulky a odstraněním všech jejích záznamů. Při práci s propojenými tabulkami je třeba dbát zvýšené opatrnosti.
Pomocí Nástroje > Relace určíme, ze které tabulky mají být data odstraněna. Podívejme se na dvě tabulky. Tabulka, jejíž primární klíč je součástí vztahu, je tabulka, jejíž data je třeba odstranit. Zavřete dialogové okno Relace. V hlavním okně databáze vybereme ikonu Tabulky. Poté dvakrát klepneme na tabulku a zobrazíme její data. Vymažeme její data. Uložíme tabulku a poté databázi. Poté je třeba tyto změny zapsat do souboru dokumentu databáze. Chceme-li to provést, zavřeme LibreOffice. Tím se také zkomprimují databázové soubory.
Pokud budeme LibreOffice znovu používat, zavřeme jej a znovu otevřeme.
Při vytváření databáze a následném testování všech možných funkcí pomocí příkladů a prováděných opravách, dokud vše nebude fungovat, budeme mít pravděpodobně primární klíče s hodnotami výrazně vyššími, než byla původní hodnota před uvedením databáze do produkce. Často jsou primární klíče skutečně nastaveny na automatický přírůstek. Pokud jsou tabulky vyprázdněny v rámci přípravy na běžné používání nebo před předáním databáze jiné osobě, primární klíč se nadále inkrementuje z aktuální pozice, místo aby se vynuloval.
Následující příkaz SQL, zadaný pomocí Nástroje > SQL, umožňuje resetovat počáteční hodnotu:
ALTER TABLE "Table_name" ALTER COLUMN "ID" RESTART WITH New value
To předpokládá, že pole primárního klíče má název ID a bylo definováno jako pole s automatickou hodnotou. Nová hodnota by měla být ta, která se má automaticky vytvořit pro další nový záznam. Pokud se tedy například aktuální záznamy zvýší na 4, nová hodnota by měla být 5, aniž by se změnilo pole ID. První hodnotou ID bude New value ve výše uvedeném příkazu SQL.
Všechny informace o tabulkách databáze jsou uloženy ve formě tabulek v samostatné části HSQLDB. Do této samostatné oblasti se dostaneme pomocí názvu INFORMATION_SCHEMA.
Následující dotaz lze použít ke zjištění názvů polí, typů polí, velikostí sloupců a výchozích hodnot. Zde je příklad pro tabulku s názvem Searchtable.
SELECT "COLUMN_NAME", "TYPE_NAME", "COLUMN_SIZE", "COLUMN_DEF" AS "Default Value" FROM "INFORMATION_SCHEMA"."SYSTEM_COLUMNS" WHERE "TABLE_NAME" = 'Searchtable' ORDER BY "ORDINAL_POSITION"
Všechny speciální tabulky v HSQLDB jsou popsány v příloze A této knihy. Informace o obsahu těchto tabulek lze nejsnáze získat přímými dotazy:
SELECT * FROM "INFORMATION_SCHEMA"."SYSTEM_PRIMARYKEYS"
Hvězdička zajišťuje zobrazení všech dostupných sloupců tabulky. Výše hledaná tabulka poskytuje základní informace o primárních klíčích různých tabulek.
Tyto informace jsou užitečné především pro makra. Místo toho, aby bylo nutné poskytovat podrobné informace o každé čerstvě vytvořené tabulce nebo databázi, jsou napsány procedury, které tyto informace získávají přímo z databáze, a jsou proto univerzálně použitelné. V ukázkové databázi je to mimo jiné vidět v jednom z modulů údržby, kde se určují cizí klíče.
Existuje mnohem jednodušší metoda exportu dat než standardní metoda exportu dat otevřením souboru *.odb. Přímo v rozhraní Base můžeme pomocí Nástroje > SQL zadat jednoduchý příkaz, který je v databázích serverů vyhrazen správci systému.
SCRIPT 'my_exported_database_file'
Tím se vytvoří kompletní výpis databáze SQL se všemi definicemi tabulek, relacemi mezi tabulkami a záznamy. Dotazy a formuláře nejsou extrahovány, protože byly vytvořeny v uživatelském rozhraní a nejsou uloženy v interní databázi. Zahrnuty jsou však všechny pohledy.
Poznámka
Tento postup lze použít k aktualizaci vložené databáze pro připojení k databázi pomocí HSQLDB 2.50. Opět je třeba nahradit dotazy a formuláře.
Ve výchozím nastavení je exportovaným souborem běžný textový soubor s názvem 'my_exported_database_file'. Soubor lze také poskytnout v binární nebo komprimované (zazipované) podobě, což je užitečné pro velké databáze. To však poněkud komplikuje jeho zpětný import do LibreOffice Base, viz níže.
Formát exportovaného souboru lze změnit pomocí jedné z hodnot nastavení SCRIPTFORMAT:
SET SCRIPTFORMAT {TEXT | BINARY | COMPRESSED};
Export souboru vyžaduje použití tohoto kódu SQL po jednotlivých řádcích:
SCRIPT ‘my_exported_database_file’;
SET SCRIPTFORMAT TEXT:
SHUTDOWN SCRIPT;
CHECKPOINT;
Tím se do domovské složky exportuje textový soubor my_exported_database_file s informacemi o databázi.
Poznámka
Ujistíme se, že 'my_exported_database_file' neexistuje ve složce, jinak se zobrazí chybová zpráva.
Soubor lze importovat pomocí Nástroje > SQL a vytvořit novou databázi se stejnými údaji. V případě interní databáze LibreOffice je třeba před importem odstranit ze souboru 'my_exported_database_file' následující řádky:
CREATE SCHEMA PUBLIC AUTHORIZATION DBA
CREATE USER SA PASSWORD ""
GRANT DBA TO SA
SET WRITE_DELAY 60
SET SCHEMA PUBLIC
Tyto položky se týkají uživatelského profilu a dalších výchozích nastavení, která jsou již pro interní databáze LibreOffice nastavena. Pokud se některý z těchto řádků vyskytne, zobrazí se chybové hlášení. Nacházejí se přímo před obsahem, který bude vložen do tabulek pomocí příkazu INSERT.
Pro import tohoto souboru je třeba obsah rozdělit do několika textových souborů vytvořených jednoduchým programem pro úpravu textu. První soubor by měl obsahovat všechny příkazy pro vytváření tabulek a pohledů. Zkopírujeme všechny řádky od začátku s CREATE TABLE a zastavíme jeden řádek nad řádkem obsahujícím INSERT INTO. Toto vložíme do prvního souboru. Zkopírujeme a vložíme zbývající řádky do druhého souboru.
Velikost druhého souboru je však omezena: musí být menší než 65 KB. Pokud je větší, měl by být také rozdělen do menších textových souborů vyjmutím a vložením. Jen se ujistíme, že horní řádek každého z těchto nových souborů začíná INSERT INTO. Jedním ze způsobů, jak toho dosáhnout, je vyjímat odspodu nahoru až k takovému řádku.
Databáze se skládá z jedné nebo více hlavních tabulek, které obsahují cizí klíče z jiných tabulek. V ukázkové databázi jsou to tabulky Media a Address. V tabulce Address se primární klíč PSČ vyskytuje jako cizí klíč. Pokud se osoba přestěhuje do nového domova, změní se i adresa. Výsledkem může být, že již neexistuje cizí klíč Postcode_ID odpovídající tomuto PSČ. V zásadě by tedy mohlo být vymazáno samotné poštovní směrovací číslo. Při běžném používání však není zřejmé, zda záznam již není potřeba. Existují různé způsoby, jak těmto problémům předcházet.
Při definování relací lze zajistit integritu dat. Jinými slovy, můžeme zabránit tomu, aby odstranění nebo změna klíčů vedla k chybám v databázi. Následující dialogové okno je přístupné prostřednictvím Nástroje > Relace a následným klepnutím pravým tlačítkem myši na spojnici mezi dvěma tabulkami.
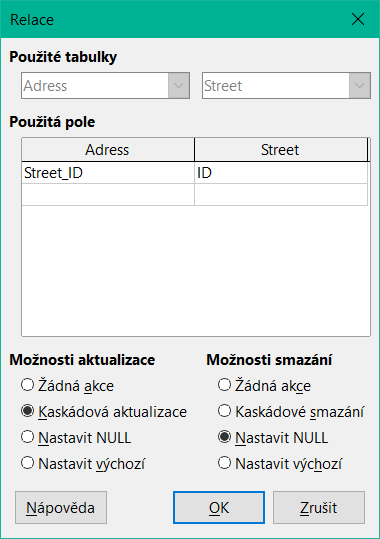 Obrázek 1: Nastavení možností aktualizace a odstranění v dialogovém okně Relace
Obrázek 1: Nastavení možností aktualizace a odstranění v dialogovém okně Relace
Zde jsou zohledněny tabulky Address a Street. Všechny zadané akce se vztahují na tabulku Address, která obsahuje cizí klíč Street_ID. Možnosti aktualizace se týkají aktualizace pole ID v tabulce Street. Pokud je číselný klíč v poli "Street". "ID" změněn, Žádná akce znamená, že databáze této změně odolá, pokud se v tabulce Address vyskytuje jako cizí klíč pole "Street". "ID" s tímto číslem klíče.
Kaskádová aktualizace znamená, že se číslo klíče jednoduše přenese. Pokud má ulice "Burgring" v tabulce Street ID "3" a je také uvedena v položce "Address". "Street_ID", lze ID bezpečně změnit. Pokud je například změněna na "67", odpovídající hodnoty "Address". "Street_ID" se automaticky změní na "67".
Pokud je vybrána možnost Nastavit null, změnou ID se z pole "Address". "Street_ID" stane prázdné pole.
S možnostmi Odstranit se pracuje podobně.
U obou možností grafické uživatelské rozhraní v současné době neumožňuje možnost Nastavit výchozí, protože výchozí nastavení grafického uživatelského rozhraní se liší od nastavení databáze. Viz kapitola 3, Tabulky.
Definování relací pomáhá udržovat samotné relace čisté, ale neodstraňuje zbytečné záznamy, které poskytují svůj primární klíč jako cizí klíč v relaci. Může existovat libovolný počet ulic bez odpovídajících adres.
V zásadě lze ve formulářích zobrazit celou vzájemnou relaci mezi tabulkami. To je samozřejmě nejjednodušší, pokud je tabulka spojena pouze s jednou další tabulkou. V následujícím příkladu se tedy primární klíč autora stane cizím klíčem v tabulce rel_Media_Author. rel_Media_Author obsahuje také cizí klíč z Media, takže následující uspořádání ukazuje relaci n:m se třemi formuláři. Každá z nich je uvedena v tabulce.
Obrázek 2 ukazuje, že titlu I hear you knocking patří autorovi Dave Edmunds. Proto nesmí být Dave Edmunds smazán – jinak budou chybět informace potřebné pro médium I hear you knocking. Pole se seznamem však umožňuje vybrat jiný záznam místo Dave Edmunds..
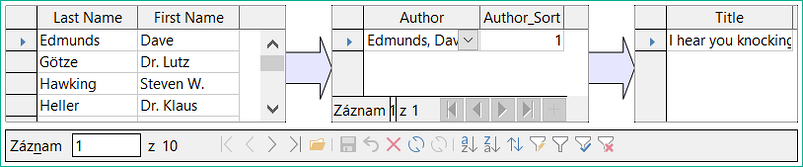
Obrázek 2: Záznam pro Dave Edmunds by neměl být z tabulky Author odstraněn.
Ve formuláři je vestavěný filtr, jehož aktivací můžeme zjistit, které kategorie nejsou v tabulce Media potřeba. V právě popsaném případě se používají téměř všechny vzorky autorů. Pouze záznam Erich Kästner může být vymazán bez jakýchkoli následků pro ostatní záznamy v tabulce Media.
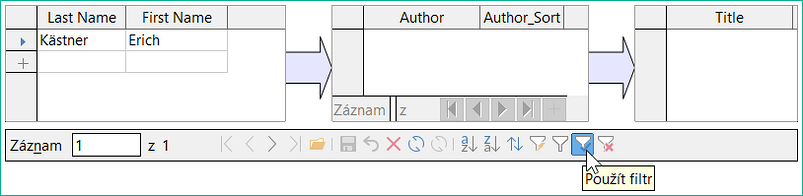
Obrázek 3: Záznam pro Ericha Kästnera mohl být odstraněn z tabulky Author.
Filtr je v tomto případě pevně zakódován. Nachází se ve vlastnostech formuláře. Takový filtr se aktivuje automaticky při spuštění formuláře. Lze jej vypnout a zapnout. Pokud je smazán, lze k němu znovu přistoupit úplným znovunačtením formuláře. To znamená víc než jen aktualizaci dat; celý dokument formuláře musí být uzavřen a poté znovu otevřen.
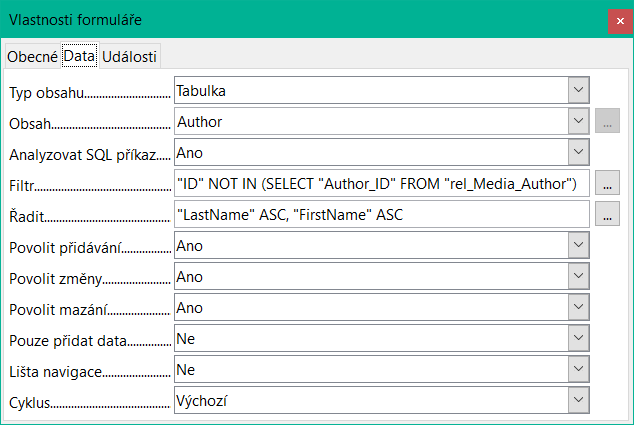
Obrázek 4: Pole filtru na kartě Data v dialogovém okně Vlastnosti formuláře
Filtr zobrazený na obrázku 4 je součástí dotazu, který lze použít k vyhledání osiřelých záznamů.
SELECT "Surname", "Firstname" FROM "Author" WHERE "ID" NOT IN (SELECT "Author_ID" FROM "rel_Media_Author")
Pokud tabulka obsahuje cizí klíče z několika jiných tabulek, je třeba dotaz odpovídajícím způsobem rozšířit. To se týká například tabulky Town, která má cizí klíče v tabulce Media i v tabulce Postcode. Proto by se na záznamy v tabulce Town, které mají být odstraněny, nemělo odkazovat v žádné z těchto tabulek. To se zjistí následujícím dotazem:
SELECT "Town" FROM "Town" WHERE "ID" NOT IN (SELECT "Town_ID" FROM "Media") AND "ID" NOT IN (SELECT "Town_ID" FROM "Postcode")
Osiřelé záznamy pak lze odstranit výběrem všech záznamů, které prošly nastaveným filtrem, a použitím možnosti Odstranit v místní nabídce ukazatele záznamu, vyvolané klepnutím pravým tlačítkem myši.
Právě tyto dotazy, použité v předchozí části k filtrování dat, se ukazují jako nevyhovující s ohledem na maximální rychlost prohledávání databáze. Problém spočívá v tom, že v rozsáhlých databázích získává poddotaz odpovídající velké množství dat, s nimiž je třeba porovnat každý jednotlivý zobrazitelný záznam. Pouze porovnání se vztahem IN umožňuje porovnat jednu hodnotu se souborem hodnot. Dotaz
… WHERE "ID" NOT IN (SELECT "Author_ID" FROM "rel_Media_Author")
může obsahovat velké množství možných cizích klíčů z tabulky rel_Media_Author, které je třeba nejprve porovnat s primárními klíči v tabulce Authors pro každý záznam v této tabulce. Takový dotaz proto není vhodný pro každodenní použití, ale může být potřebný pro údržbu databáze. Pro každodenní použití je třeba vyhledávací funkce konstruovat jinak, aby vyhledávání dat nebylo příliš dlouhé a nenarušovalo každodenní práci s databází.
Čím více seznamů je do formuláře zabudováno a čím více dat obsahují, tím déle trvá načítání formuláře, protože tyto seznamy je třeba načíst a vytvořit.
Čím lépe program Base nastaví grafické rozhraní a zpočátku načte obsah pole se seznamem jen částečně, tím rychleji poběží.
Pole se seznamy se vytvářejí pomocí dotazů a tyto dotazy se musí spustit při načítání formuláře pro každé pole se seznamem.
Pokud se stejná struktura dotazu používá pro několik polí se seznamem, je lepší použít společné Pohledy, než opakovaně vytvářet pole se stejnou syntaxí pomocí uložených příkazů SQL v polích se seznamem. Pohledy jsou výhodné především pro externí databázové systémy, protože zde server běží výrazně rychleji než dotaz, který musí být sestaven grafickým uživatelským rozhraním a čerstvě odeslán na server. Server považuje Pohledy za dokončené místní dotazy.
Interní databáze HSQLDB je nastavena tak, aby byla zajištěna dobrá spolupráce databází Base a Java. Při použití vestavěného systému správy databází Base, jako je například databázový stroj HSQLDB, je velikost a odezva databáze omezená ve srovnání s použitím externího databázového stroje. Zejména pokud je tento databázový server spuštěn na samostatném počítači. Pokud se funkce naší databáze začnou zpomalovat, postupujeme nejprve podle pokynů v této příručce pro vyčištění prázdného místa, odstraněných nebo dočasných dat a zkontrolujeme, zda používáme indexy tam, kde to má smysl. Pokud se odezva nevyplatí, zvážíme přesunutí dat z dat Base ODB na externí databázový server.
Externí databáze běží výrazně rychleji. Přímé připojení k MySQL nebo PostgreSQL a připojení pomocí ODBC probíhají prakticky stejně rychle. JDBC také závisí na spolupráci s Javou, ale stále funguje rychleji než interní připojení pomocí HSQLDB.