Calc Guide 7.4
Kapitola 7
Použití vzorců a funkcí
Tento dokument je chráněn autorskými právy © 2023 týmem pro dokumentaci LibreOffice. Přispěvatelé jsou uvedeni níže. Dokument lze šířit nebo upravovat za podmínek licence GNU General Public License (https://www.gnu.org/licenses/gpl.html), verze 3 nebo novější, nebo the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0/), verze 4.0 nebo novější.
Všechny ochranné známky uvedené v této příručce patří jejich vlastníkům.
|
Skip Masonsmith |
Kees Kriek |
|
|
Barbara Duprey |
Jean Hollis Weber |
John A. Smith |
|
Olivier Hallot |
Kees Kriek |
Steve Fanning |
|
Leo Moons |
Gordon Bates |
Felipe Viggiano |
|
Rachel Kartch |
|
|
Jakékoli připomínky nebo návrhy k tomuto dokumentu prosím směřujte do fóra dokumentačního týmu na adrese https://community.documentfoundation.org/c/documentation/loguides/ (registrace je nutná) nebo pošlete e-mail na adresu: loguides@community.documentfoundation.org.
Poznámka
Vše, co napíšete do fóra, včetně vaší e-mailové adresy a dalších osobních údajů, které jsou ve zprávě napsány, je veřejně archivováno a nemůže být smazáno. E-maily zaslané do fóra jsou moderovány.
Vydáno březen 2023. Založeno na LibreOffice 7.4 Community.
Jiné verze LibreOffice se mohou lišit vzhledem a funkčností.
Některé klávesové zkratky a položky nabídek jsou v systému macOS jiné než v systémech Windows a Linux. V následující tabulce jsou uvedeny nejdůležitější rozdíly, které se týkají informací uvedených v tomto dokumentu. Podrobnější seznam nalezneme v nápovědě k programu a v příloze A (Klávesové zkratky) této příručky.
|
Windows nebo Linux |
Ekvivalent pro macOS |
Akce |
|
Výběr v nabídce Nástroje > Možnosti |
LibreOffice > Předvolby |
Otevřou se možnosti nastavení. |
|
Klepnutí pravým tlačítkem |
Control + klepnutí a/nebo klepnutí pravým tlačítkem myši v závislosti na nastavení počítače |
Otevře se místní nabídka |
|
Ctrl (Control) |
⌘ (Command) |
Používá se také s dalšími klávesami. |
|
F11 |
⌘ + T |
Otevře kartu Styly na postranní liště |
V předchozích kapitolách jsme do každé buňky zadávali jeden ze dvou základních typů dat: čísla a text. Nebudeme však vždy vědět, jaký by měl být obsah. Obsah jedné buňky často závisí na obsahu ostatních buněk. K řešení této situace používáme třetí typ dat: vzorec. Vzorce jsou výrazy, jejichž výsledek je vypočítán pomocí čísel a proměnných. V sešitu jsou proměnné umístění buněk, která obsahují data potřebná pro dokončení rovnice.
Funkce je předdefinovaný výpočet vložený do buňky, umožňující analyzovat či zpracovávat data. Jediné, co musíme udělat, je zadat argumenty funkce a výpočet se provede automaticky. Funkce pomáhají při vytváření vzorců, pomocí kterých získáme požadovaný výsledek.
Pokud v programu Calc nastavujeme více než jednoduchý systém jednoho listu, vyplatí se trochu dopředu plánovat. Nezapomeneme:
Vyvarujeme se zadávání pevných hodnot do vzorců.
Zahrneme dokumentaci (poznámky a komentáře) popisující, co systém dělá, včetně toho, jaký vstup je vyžadován a odkud pocházejí vzorce (pokud nebyly vytvořeny od nuly).
Zahrneme systém kontroly chyb vzorců a ověříme, zda vzorce dělají to, co je zamýšleno.
Mnoho uživatelů nastavuje dlouhé a složité vzorce s pevnými hodnotami zadanými přímo do vzorce.
Například převod z jedné měny na druhou vyžaduje znalost aktuálního konverzního kurzu. Pokud do buňky C1 zadáme vzorec =0,75*B (například pro výpočet hodnoty v eurech z částky USD dolaru v buňce B1), budeme muset vzorec upravit, když se směnný kurz změní z 0,75 na jinou hodnotu. Je mnohem snazší nastavit vstupní buňku se směnným kurzem a odkazem na buňku v jakémkoli vzorci, který potřebuje směnný kurz. Výpočty typu „co když" jsou také zjednodušeny: co když se směnný kurz mění od 0,75 do 0,70 nebo 0,80? Není nutná žádná úprava vzorců a je jasné, jaký kurz se používá ve výpočtech. Rozdělení komplexních vzorců na lépe zvládnutelné části, což je popsáno níže, také pomáhá minimalizovat chyby a pomáhá při řešení problémů.
Nedostatek dokumentace je velmi častým bodem selhání. Mnoho uživatelů vytvoří jednoduchý list, který se postupem času vyvine v něco mnohem složitějšího. Bez dokumentace je původní účel a metodika často nejasná a obtížně rozluštitelná. V tomto případě je obvykle snazší začít znovu od začátku a zahodit dříve provedenou práci. Při pozdějších úpravách tabulky ušetříme mnoho času a úsilí, pokud do buněk vložíme komentáře a používáme štítky a nadpisy.
Přidání sloupců dat nebo výběru buněk z listu vede často k chybám způsobeným vynecháním buněk, nesprávným určením rozsahu nebo dvojím počítáním buněk. Proto je užitečné zavést v sešitech kontroly. Máme například tabulku se sloupci čísel a funkci SUMA používáme pro výpočet součtů jednotlivých sloupců. Výsledek můžeme zkontrolovat vytvořením (v netisknutém sloupci) sady součtů řádků a jejich celkovým součtem. Obě hodnoty — součet v řádcích a celkový součet ve sloupci — musí souhlasit. Pokud tomu tak není, máme někde chybu.
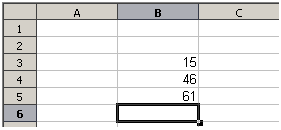
Můžeme dokonce nastavit vzorec pro výpočet rozdílu mezi dvěma součty a nahlásit chybu v případě, že je vrácen nenulový výsledek (viz obrázek 1).
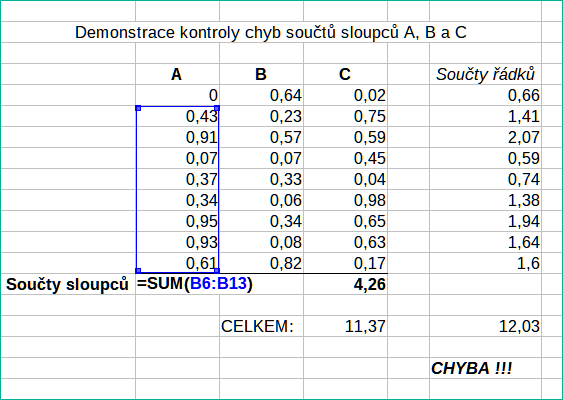
Obrázek 1: Kontrola chyb vzorců
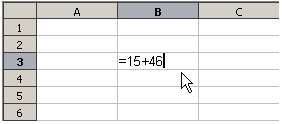
Vzorce můžeme zadávat dvěma způsoby: Jedna možnost je použít Průvodce funkcí nebo obdobnou funkci na kartě Funkce postranní lišty. Druhá možnost je napsat vzorec přímo do buňky nebo Vstupního řádku. Vzorce musí začínat symbolem =. Při přímém psaní musíme začít vzorec symbolem =. Pokud vzorec začíná znakem + nebo – (například -2*A1), Calc symbol = přidá automaticky. Znak = se nepřidá, pokud zadáme kladné či záporné číslo (například -2 nebo +3). Jakýkoliv jiný znak na začátku způsobí, že bude vzorec považován za text.
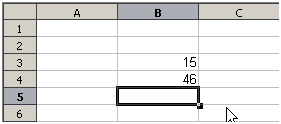
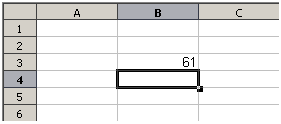
Každá buňka v listu může být použita jako nositel dat nebo místo pro výpočet dat. Chceme-li zadat data, jednoduše píšeme do buňky a přesuneme se na další buňku nebo stiskneme Enter. U vzorců znaménko rovná se znamená, že buňka bude použita pro výpočet. Příklad matematického výpočtu 15 + 46 je znázorněn na obrázku 1.
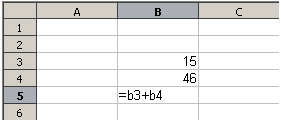
Zatímco výpočet vlevo používal pouze jednu buňku, ukázka možností je zobrazena vpravo, kde jsou data umístěna do buněk a výpočet je prováděn pomocí odkazů na buňky. V tomto případě byly buňky B3 a B4 nositeli dat, s buňkou B5, kde byl výpočet proveden. Všimneme si, že vzorec byl zobrazen jako =B3+B4. Znaménko plus znamená, že obsah buněk B3 a B4 se sečte a výsledek je v buňce, kde je zapsán vzorec. Všechny vzorce vycházejí z této koncepce. Další způsoby použití vzorců jsou uvedeny v tabulce 1.
Tyto odkazy na buňky umožňují vzorcům používat data odkudkoli na zpracovávaném listu nebo z jakéhokoli jiného listu v otevřeném dokumentu. Pokud by byla potřebná data v různých listech, odkazovala by se na název listu, například =$Sheet2.B12+$Sheet3.A11.
Poznámka
Chceme-li zadat symbol = za jiným účelem, než je vytvoření vzorce, jak je popsáno v této kapitole, zadáme před znak = apostrof nebo jednoduchou uvozovku. Například položka '= znamená různé věci pro různé lidi, Calc považuje za text vše po apostrofu včetně znaménka =.
|
Jednoduchý výpočet v jedné buňce |
Výpočet referencí |
|
|
|
|
|
|
|
|
|
Obrázek 1: Jednoduchý výpočet
Tabulka 1: Běžné způsoby použití vzorců
|
Vzorec |
Popis |
|
=A1+10 |
Zobrazuje obsah buňky A1 plus 10. |
|
=A1*16% |
Zobrazuje 16 % obsahu A1. |
|
=A1*A2 |
Zobrazuje výsledek vynásobení obsahu A1 a A2. |
|
=ROUND(A1;1) |
Zobrazuje obsah buňky A1 zaokrouhlený na jedno desetinné místo. |
|
=EFFECT(5%;12) |
Vypočítá efektivní úrok pro 5% roční nominální úrok s 12 platbami ročně. |
|
=B8-SUM(B10:B14) |
Vypočítá B8 mínus součet buněk B10 až B14. |
|
=SUM(B8;SUM(B10:B14)) |
Vypočítá součet buněk B10 až B14 a připočte hodnotu B8. |
|
=SUM(B1:B1048576) |
Sečte všechna čísla ve sloupci B. |
|
=AVERAGE(BloodSugar) |
Zobrazuje průměr pojmenované oblasti definované pod názvem BloodSugar. Je také možné stanovit oblasti pro zahrnutí jejich pojmenováním pomocí List > Pojmenované rozsahy a výrazy > Definovat, například BloodSugar představující rozsah B3:B10. |
|
=IF(C31>140, “HIGH”, “OK”) |
Logické funkce mohou být také prováděny tak, jak jsou reprezentovány příkazem IF, který má za následek podmíněnou odpověď na základě dat v identifikované buňce. Pokud je obsah C31 větší než 140, zobrazí se HIGH, jinak se zobrazí OK. |
V programu Calc můžeme použít následující typy operátorů: aritmetické, srovnávací, textové a referenční.
Operátory sčítání, odčítání, násobení a dělení vracejí číselné výsledky. Operátory negace a procenta identifikují charakteristiku čísla nalezeného v buňce, například -37. Příklad pro umocnění ilustruje, jak zadat číslo, které je samo o sobě násobeno, například 2^3 = 2*2*2.
Tabulka 2: Aritmetické operátory
|
Operátor |
Název |
Příklad |
|
+ (plus) |
Sčítání |
=1+1 |
|
– (mínus) |
Odčítání |
=2–1 |
|
– (mínus) |
Negace |
–5 |
|
* (hvězdička) |
Násobení |
=2*2 |
|
/ (lomítko) |
Dělení |
=10/5 |
|
% (procento) |
Procento |
15% |
|
^ (stříška) |
Umocnění |
=2^3 |
Srovnávací operátory se nacházejí ve vzorcích, které používají funkci IF a vracejí buď pravdivou nebo falešnou odpověď; například, =IF(B6>G12;127;0) což, volně přeloženo, znamená, pokud je obsah buňky B6 větší než obsah buňky G12, pak vraťte číslo 127, jinak vraťte číslo 0.
Přímou odpověď PRAVDA nebo NEPRAVDA lze získat zadáním vzorce jako =B6>B12. Pokud jsou čísla nalezená v odkazovaných buňkách přesně reprezentována, je vrácena odpověď PRAVDA, jinak je vrácena NEPRAVDA.
Tabulka 3: Porovnávací operátory
|
Operátor |
Název |
Příklad |
Výsledek (A=4, B=5) |
|
= |
Rovno |
A1=B1 |
FALSE |
|
> |
Větší než |
A1>B1 |
FALSE |
|
< |
Méně než |
A1<B1 |
TRUE |
|
>= |
Větší nebo rovno |
A1>=B1 |
FALSE |
|
<= |
Menší nebo rovno |
A1<=B1 |
TRUE |
|
<> |
Nerovnost |
A1<>B1 |
TRUE |
Pokud buňka A1 obsahuje číselnou hodnotu 4 a buňka B1 obsahuje číselnou hodnotu 5, výše uvedené příklady by přinesly výsledky NEPRAVDA, NEPRAVDA, PRAVDA, NEPRAVDA, PRAVDA a PRAVDA.
Je běžné, že uživatelé vkládají text do tabulek. Aby byla zajištěna variabilita v tom, co a jak se tento typ dat zobrazuje, lze text spojit z kusů pocházejících z různých míst v tabulce. Obrázek 2 ukazuje příklad.
|
|
|
|
|
Obrázek 2: Zřetězení textu |
V tomto příkladu byly konkrétní části textu nalezeny ve třech různých buňkách. Pro spojení těchto segmentů vzorec také obsahuje požadované mezery a interpunkci uzavřenou v uvozovkách, což má za následek vzorec =B2 & " " & C2 & ", " & D2. Výsledkem je zřetězení na datum naformátované v konkrétní posloupnosti.
Program Calc má funkci CONCATENATE, která provádí stejnou operaci.
Jednotlivá buňka je identifikována identifikátorem sloupce (písmenem) umístěným podél horní části sloupců a identifikátorem řádku (číslem) na levé straně tabulky. V tabulkách čtených zleva doprava je odkaz na levou horní buňku A1.
Odkaz ve své nejjednodušší formě tedy odkazuje na jednu buňku, ale odkazy mohou také odkazovat na obdélníkovou nebo 3D oblast nebo odkaz v seznamu odkazů. K vytvoření takových odkazů potřebujete referenční operátory.
Operátor oblasti je zapsán jako dvojtečka. Výraz používající operátor rozsahu má následující syntaxi:
referenční horní levý: referenční dolní pravý
Operátor oblasti sestavuje odkaz na nejmenší oblast zahrnující jak buňky odkazované na levý odkaz, tak buňky odkazované na pravý odkaz.
V levém horním rohu obrázku 4 je zobrazen odkaz A1:D12, který odpovídá buňkám zahrnutým v operaci přetažení myší pro zvýraznění oblasti.
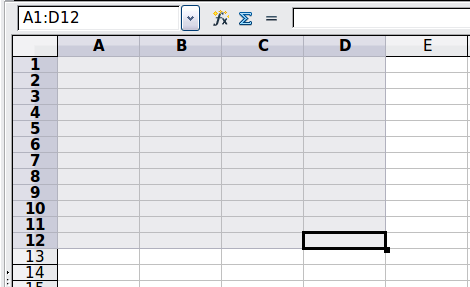
Obrázek 4: Referenční operátor pro oblast
Tabulka 4: Příklady operátoru referenčního rozsahu
|
Příklad |
Popis |
|
A2:B4 |
Odkaz na obdélníkovou oblast se 6 buňkami, širokou 2 sloupce × 3 řádky na výšku. Pokud klepneme ve vstupním řádku na referenci ve vzorci, ohraničení označuje obdélník. |
|
(A2:B4):C9 |
Odkaz na oblast tvaru obdélníku s buňkou A2 vlevo nahoře a buňkou C9 vpravo dole. Oblast tedy obsahuje 24 buněk, 3 sloupce širokou × 8 řádků vysokou. Tento způsob adresování rozšiřuje počáteční rozsah z A2:B4 na A2:C9. |
|
Sheet1.A3:Sheet3.D4 |
Odkaz na 3D rozsah s 24 buňkami, o šířce 4 sloupců × 2 řádky × hloubkou 3 listů. (Předpokládáme, že se listy Sheet1, Sheet2 a Sheet3 zobrazují v tomto pořadí v oblasti Karty listů.) |
|
B:B |
Odkaz na všechny buňky sloupce B. |
|
A:D |
Odkaz na všechny buňky sloupců A až D. |
|
20:20 |
Odkaz na všechny buňky v řádku 20. |
|
1:20 |
Odkaz na všechny buňky z řádků 1 až 20. |
Pokud přímo vložíme B4:A2, B2:A4 nebo A4:B2, Calc změní rozsah na A2:B4. Levá horní buňka oblasti je tedy vlevo od dvojtečky a pravá dolní buňka vpravo od dvojtečky. Pokud ale pojmenujeme buňku B4 například pomocí _start a A2 názvem _end, můžeme použít _start: _end bez jakékoli chyby. Další informace o pojmenování buněk najdeme v části „Pojmenované oblasti“ na straně 1.
Operátor zřetězení je psán jako vlnovka. Výraz používající operátor zřetězení má následující syntaxi:
levá reference ~ pravá reference
Výsledkem takového výrazu je seznam referencí, který je uspořádaným seznamem odkazů. Některé funkce mohou vzít referenční seznam jako argument, například SUM, MAX nebo INDEX.
Referenční zřetězení se někdy nazývá 'union'. Nejedná se však o spojení těchto dvou sad 'levá reference' a 'pravá reference', jak je obvykle chápáno v teorii množin. COUNT(A1:C3~B2:D2) vrátí 12 (= 9+3), ale má pouze 10 buněk, pokud je považováno za spojení dvou sad buněk.
Všimněme si, že SUM(A1:C3,B2:D2) se liší od SUM(A1:C3~B2:D2) ačkoli dávají stejný výsledek. První je volání funkce se 2 parametry, z nichž každý je odkazem na oblast. Druhý je volání funkce s 1 parametrem, což je seznam referencí.
Referenční zřetězení platí také pro celé řádky a celé sloupce. Například SUM(A:B~D:D) je součet všech buněk ve sloupcích A a B a sloupci D.
Operátor průniku je psán jako vykřičník. Výraz používající operátor průniku má následující syntaxi:
reference vlevo ! reference vpravo
Pokud reference odkazují na jednotlivé oblasti, výsledkem je odkaz na jedinou oblast obsahující všechny buňky, které jsou jak v levé referenci, tak v pravé referenci.
Pokud jsou referencí seznamy odkazů, je každá položka z levého seznamu protnuta s každou z pravého seznamu (průnik) a tyto výsledky jsou spojeny do seznamu referencí. Pořadí je první průnik první položky zleva se všemi položkami zprava, poté průnik druhé položky zleva se všemi položkami zprava a tak dále.
A2:B4 ! B3:D6
Výsledek je reference na oblast B3:B4, protože tyto buňky jsou uvnitř A2:B4 a uvnitř B3:D6. To je znázorněno na obrázku 5, na kterém mají buňky v oblasti A2:B4 oranžové pozadí a buňky v oblasti B3:D6 mají silné černé okraje. Buňky, které mají oranžové pozadí i tlustý černý okraj (B3:B4), tvoří průnik těchto dvou oblastí.

Obrázek 5: Jednoduchý příklad operátoru referenčního průniku
(A2:B4~B1:C2) ! (B2:C6~C1:D3)
Nejprve jsou počítány průniky A2:B4!B2:C6, A2:B4!C1:D3, B1:C2!B2:C6, a B1:C2!C1:D3. Výsledkem je B2:B4, prázdný, B2:C2, a C1:C2. Poté jsou tyto výsledky zřetězeny, zahodí se prázdné části. Konečným výsledkem je tedy referenční seznam B2:B4 ~ B2:C2 ~ C1:C2.
A:B ! 10:10
Vypočítá průnik sloupců A a B s řádkem 10, čímž vybere A10 a B10.
Operátor průniku můžeme použít k odkazu na buňku v křížení sloupce a řádku. Pokud máme sloupce označené 'Teplota' a 'Srážky' a řádky označené 'leden', 'únor', 'březen' atd., poté následující výraz
'únor' ! 'Teplota'
bude odkazovat na buňku obsahující teplotu v únoru.
Operátor průniku (!) má vyšší prioritu než operátor zřetězení (~), ale nespoléhejme se na to.
Tip
Vždy zadejme do závorek část, která se má vypočítat jako první.
Odkazy jsou způsob, jakým odkazujeme na umístění konkrétní buňky v Calc a mohou být buď relativní (k aktuální buňce) nebo absolutní (pevná oblast).
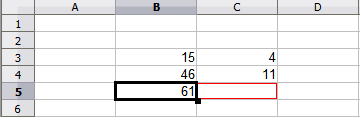
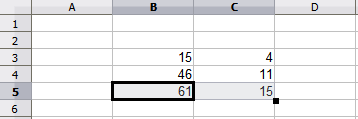
Příklad relativní reference bude znázorňovat rozdíl mezi relativním odkazem a absolutním odkazem pomocí tabulky z obrázku 6.
Zadáme čísla 4 a 11 do buněk C3 a C4 tabulky.
Zkopírujeme vzorec v buňce B5 (=B3+B4) do buňky C5. To lze provést pomocí jednoduché kopie a vložení nebo klepnutím a přetažením B5 na C5, jak je ukázáno níže. Vzorec v B5 vypočítá součet hodnot ve dvou buňkách B3 a B4.
Klepneme do buňky C5. Lišta vzorců ukazuje =C3+C4 místo =B3+B4 a hodnota v C5 je 15, součet 4 a 11, což jsou hodnoty v C3 a C4.
V buňce B5 jsou odkazy na buňky B3 a B4 relativní odkazy. To znamená, že program Calc interpretuje vzorec v B5, aplikuje jej na buňky ve sloupci B a výsledek umístí do buňky, ve kterém je vzorec. Když jsme zkopírovali vzorec do jiné buňky, byl stejný postup použit pro výpočet hodnoty, která se má do dané buňky vložit. Tentokrát se vzorec v buňce C5 odkazoval na buňky C3 a C4.
Relativní adresu můžeme považovat za dvojici odchylek k aktuální buňce. Buňka B1 je 1 sloupec nalevo od buňky C5 a 4 řádky výše. Adresa může být zapsána jako R[-4]C[-1]. Ve skutečnosti starší tabulkové procesory umožňovaly použití této metody zápisu ve vzorcích.
Kdykoli zkopírujeme tento vzorec z buňky B5 do jiné buňky, výsledkem bude vždy součet dvou čísel ze dvou buněk, které jsou jeden a dva řádky nad buňkou obsahující vzorec.
Relativní adresování je výchozí metoda odkazování na adresy v programu Calc.
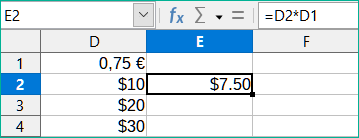
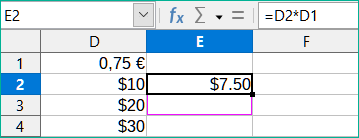
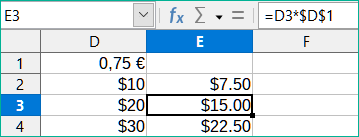
Možná budeme chtít znásobit sloupec čísel pevnou částkou. Sloupec čísel může zobrazovat částky v amerických dolarech. Pro převod těchto částek na eura je nutné vynásobit každou částku dolaru směnným kurzem. 10,00 USD by bylo vynásobeno 0,75 pro převod na eura, v tomto případě 7,50 EUR. Následující příklad ukazuje, jak zadat směnný kurz a použít tento kurz k převodu částek ve sloupci z USD na eura.
Zadáme směnný kurz EUR:USD (0,75) do buňky D1. Zadáme částky (v USD) do buněk D2, D3 a D4, například 10, 20 a 30.
Do buňky E2 zadáme vzorec =D2*D1. Výsledek je 7,5, zobrazen správně.
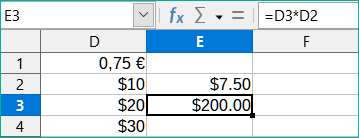
Zkopírujeme vzorec v buňce E2 do buňky E3. Výsledek je 200, zcela špatně! Program Calc zkopíroval vzorec pomocí relativního adresování: vzorec v E3 je =D3*D2 a ne to, co chceme, což je =D3*D1.
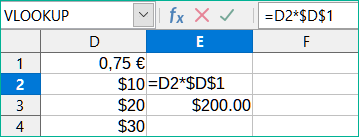
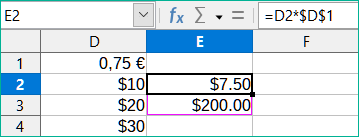
V buňce E2 upravíme vzorec na =D2*$D$1. Zkopírujeme jej do buněk E3 a E4. Výsledky jsou nyní správně 15 a 22,5.
Znaky $ před D a 1 převádějí odkaz na buňku D1 z relativního na absolutní nebo pevný. Pokud je vzorec zkopírován do jiné buňky, druhá část bude vždy zobrazovat $D$1. Interpretace tohoto vzorce je „vezměte hodnotu v buňce jeden sloupec doleva ve stejném řádku a vynásobte ji hodnotou v buňce D1“.
|
|
|
|
Zadáme vzorec pro převod do E2, kde se zobrazí správný výsledek a poté jej zkopírujeme do E3. |
|
|
|
|
|
Výsledek E3 je zjevně špatný; změníme vzorec v E2 na absolutní odkaz. |
|
|
|
|
|
Zkopírujeme správný vzorec z E2 do E3 a dostaneme správný výsledek. |
|
|
Obrázek 7: Absolutní odkazy |
|
Odkazy na buňky lze zobrazit čtyřmi způsoby, které jsou zobrazeny v tabulce 5.
Tabulka 5: Typy odkazu na buňku
|
Odkaz |
Vysvětlení |
|
D1 |
Relativní, od buňky E3 je to buňka o jeden sloupec vlevo a dva řádky nad ní |
|
$D$1 |
Absolutní, je to buňka D1 |
|
$D1 |
Částečně absolutní, z buňky E3 je to buňka ve sloupci D a o dva řádky výše |
|
D$1 |
Částečně absolutní, z buňky E3 je to buňka o jeden sloupec vlevo a v řádku 1 |
Tip
Chceme-li změnit odkazy ve vzorcích, zvýrazníme buňku a stiskneme F4 pro změnu mezi čtyřmi typy odkazů. Chceme-li měnit pouze část vzorce, vybereme buňky a v pruhu vzorců provádíme změnu pomocí F4. Výběr možnosti nabídky List > Měnit typ odkazu na buňku je ekvivalentní stisknutí klávesy F4.
Znalost použití relativních a absolutních odkazů je nezbytná, pokud chceme kopírovat a vkládat vzorce a propojovat tabulky.
Buňkám a oblastem buněk může být přiřazen název. Pojmenování buněk a rozsahů zlepšuje čitelnost vzorců a údržbu dokumentů. Jednoduchým příkladem by bylo pojmenování řady buněk B1:B10 jako „Hmotnost“ a součet všech hmotností. Vzorec je =SUM(B1:B10). Když je oblast B1:B10 pojmenována jako Hmotnost, můžeme vzorec převést na =SUM(Hmotnost). Výhoda je jasná z hlediska čitelnosti vzorců.
Další výhodou je, že všechny vzorce, které mají pojmenovanou oblast jako argument, se aktualizují, když pojmenovaná oblast změní umístění nebo velikost. Pokud je například oblast Hmotnost nyní v buňkách P10:P30, nemusíme kontrolovat všechny vzorce, které mají jako argument Hmotnost; stačí aktualizovat pojmenovanou oblast Hmotnost s novou velikostí a umístěním.
Chceme-li definovat pojmenovanou buňku nebo oblast, vybereme buňku nebo oblast a použijeme nabídku List > Pojmenované oblasti a výrazy > Definovat. Zobrazí se dialog na obrázku 8 s vybraným rozsahem a definujeme název a rozsah pojmenované oblasti.
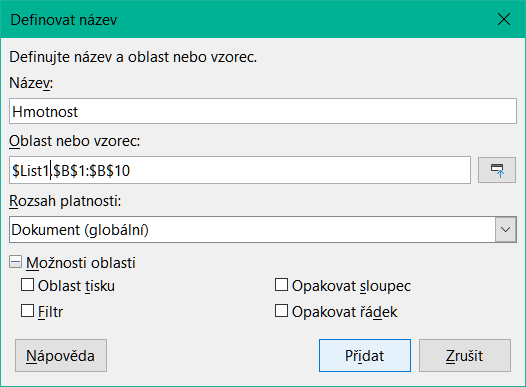
Obrázek 8: Dialogové okno Definovat název
Pojmenovanou oblast můžeme také definovat přímo v listu výběrem oblasti a zadáním jejího názvu do Pole názvu na levé straně lišty vzorců (obrázek 9).
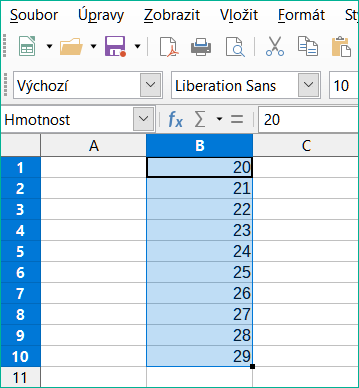
Obrázek 9: Vložení názvu do pole názvu pro definování pojmenované oblasti
Chceme-li rychle získat přístup k pojmenované oblasti, vybereme pojmenovanou oblast v rozevíracím seznamu Pole názvu. Pojmenovaná oblast se zobrazí na obrazovce a je vybrána.
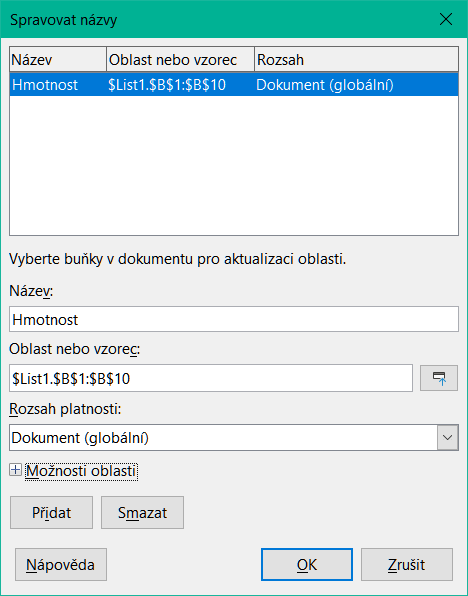
Obrázek 10: Dialogové okno Spravovat názvy
Pro úpravu pojmenované oblasti použijeme dialogové okno Spravovat názvy (obrázek 10). K tomuto dialogu se dostaneme výběrem List > Pojmenované oblasti a výrazy > Spravovat z hlavní nabídky nebo stisknutím Ctrl + F3.
Dlouhý nebo složitý vzorec můžeme také pojmenovat. Chceme-li pojmenovat vzorec, otevřeme dialogové okno Definovat název (obrázek 8) a zadáme výraz vzorce do pole Oblast nebo vzorec. Pojmenujeme výraz a klepneme na Přidat.
Předpokládejme například, že v buňkách C1 až C10 musíme spočítat obvod sady kruhů a jejich poloměr je uveden v B1 až B10. Definujeme pojmenovaný výraz OBVODKRUHU, s výrazem =2*PI()*B1 a klepneme na Přidat, čímž zavřeme dialog. Do buňky C1 zadáme =OBVODKRUHU a stiskneme Enter. Vzorec je aplikován na buňku C1. Zkopírujeme buňku C1 a vložíme ji do zbývajících buněk od C2 do C10 a máme obvody všech kruhů. Všechny buňky v rozsahu C1:C10 mají výraz =OBVODKRUHU.
Všimněme si, že pojmenovaný výraz používá stejná pravidla pro adresování buněk, tj. absolutní a relativní odkazy.
Pořadí výpočtu se vztahuje k posloupnosti provádění numerických operací a článek Wikipedie na adrese https://en.wikipedia.org/wiki/Order_of_operations poskytuje užitečné obecné informace. Dělení a násobení se provádí před sčítáním nebo odečítáním. Existuje obecná tendence očekávat, že výpočty budou prováděny zleva doprava, protože rovnice bude čtena v angličtině. Program Calc vyhodnotí celý vzorec, poté na základě programovací priority rozdělí vzorec a provede operace násobení a dělení před jinými operacemi. Proto bychom měli při vytváření vzorců vyzkoušet svůj vzorec, abychom se ujistili, že je dosaženo očekávaného a správného výsledku. Následuje příklad pořadí výpočtu.
Tabulka 6: Pořadí výpočtu
|
Výpočet zleva doprava |
Pořadí výpočtu |
|
1+3*2+3 = 11 1+3 = 4, poté 4×2 = 8, poté 8+3 = 11 |
=1+3*2+3 výsledek 10 3*2 = 6, poté 1+6+3 = 10 |
|
Dalším možným záměrem by mohlo být: 1+3*2+3 = 20 1+3 = 4, poté 2+3 = 5, poté 4×5=20 |
Program řeší násobení 3 × 2 před zpracováním dalších čísel. |
Pokud chceme, aby výsledek byl jedním z dvou možných řešení vlevo, zadáme vzorec takto:
|
((1+3) * 2)+3 = 11 |
(1+3) * (2+3) = 20 |
Poznámka
pro seskupení operací v pořadí, které zamýšlíme použijeme závorky. Například =B4+G12*C4/M12 se může stát =((B4+G12)*C4)/M12.
Další silnou funkcí programu Calc je schopnost propojit data přes několik listů. Pojmenování listů může být užitečné při určování, kde lze nalézt konkrétní data. Název jako VýplatníListina nebo Prodeje je smysluplnější než Sheet1. Funkce s názvem SHEET() vrací číslo listu (pozici) v seznamu listů. V každém dokumentu může být několik listů a mohou být očíslovány zleva: List1, List2 atd. Pokud přetáhneme listy na jiné umístění mezi kartami funkce vrací číslo odkazující na aktuální polohu tohoto listu. V nové instanci programu Calc je výchozí nastavení jeden list v sešitě.
Pokud je například vzorec =SHEET() vložen do A1 na List1, vrátí hodnotu 1. Pokud přetáhneme List1 na umístění mezi listy 2 a 3, hodnota se změní na 2. Nyní je to druhý list v pořadí.
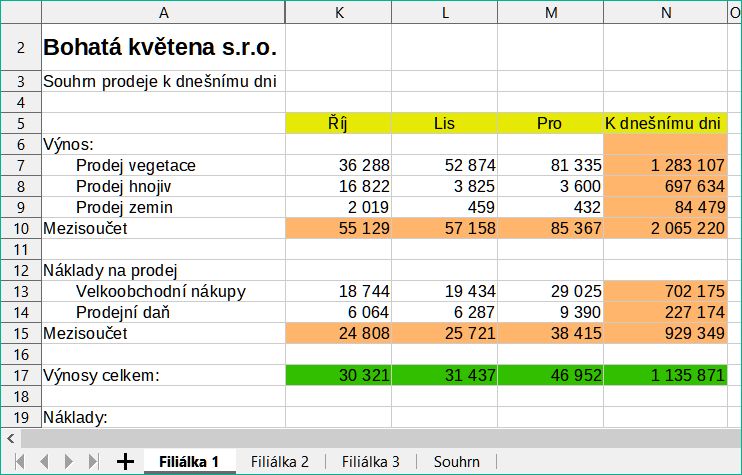
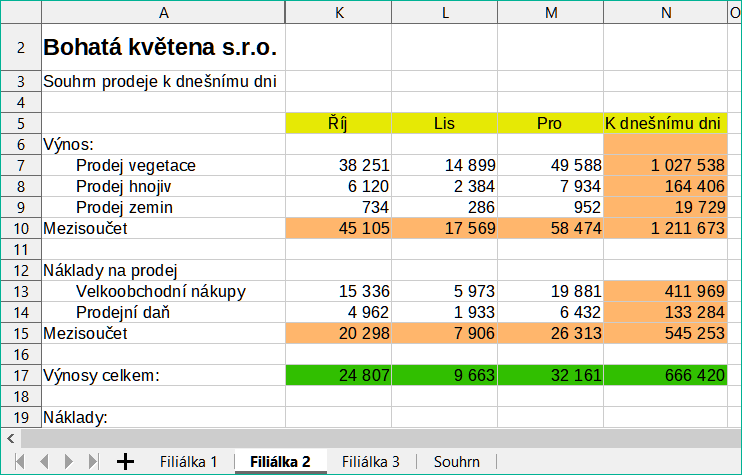
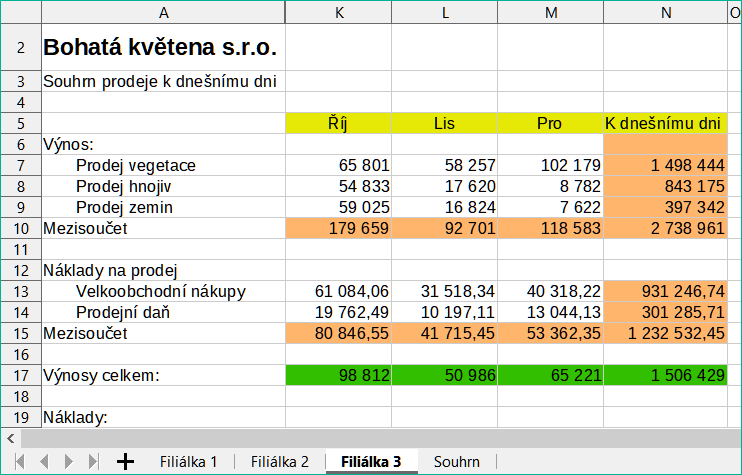
Příklad výpočtů získávajících data z jiné oblasti lze vidět v podnikovém prostředí, kde podnik kombinuje výnosy a náklady každé ze svých poboček do jediného kombinovaného listu. Viz čtyři části obrázku 11 pod.
|
|
|
|
|
List obsahující údaje pro Pobočku 2. |
|
|
List obsahující údaje pro Pobočku 3. |
|
|
List obsahující kombinovaná data pro všechny pobočky. |
|
Obrázek 11: Kombinace dat z několika listů do jednoho listu |
|
Listy byly vytvořeny se stejnými strukturami. Nejjednodušší způsob, jak toho dosáhnout, je otevřít novou tabulku, nastavit první list pobočky, zadat data, naformátovat buňky a připravit vzorce pro různé součty řádků a sloupců. Poté vytvoříme kopie prvního listu následujícím způsobem:
Klepneme pravým tlačítkem na název listu a vybereme Přejmenovat list. Zadáme Filiálka 1. Klepneme pravým tlačítkem myši znovu na list a vybereme Přesunout nebo kopírovat list.
V dialogovém okně Přesunout/kopírovat list (obrázek 12) vybereme volbu Kopírovat (je automaticky vybrána, pokud je v tabulce pouze jeden list) a zvolíme -přesunout na konec- v sekci Vložit před. Změníme název v poli Nový název na Filiálka 2. Klikneme na tlačítko Kopírovat. Stejným způsobem vytvoříme listy Filiálka 3 a Souhrn.
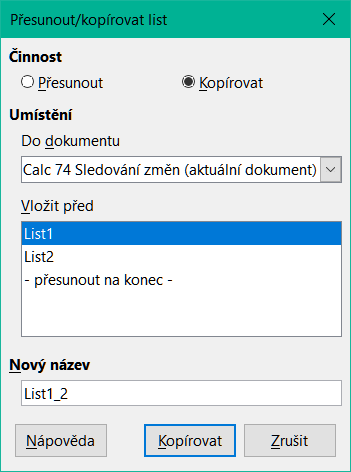
Obrázek 12: Kopírování listu
Do příslušných listů zadáme údaje pro filiálku 2 a filiálku 3. Každý samostatný list uvádí výsledky pro jednotlivé pobočky.
V listu Souhrn klepneme na buňku K7. Zadáme =, klepneme na list Filiálka 1, klepneme na buňku K7, zmáčkneme +, opakujeme to pro listy Filiálka 2 a Filiálka 3 a poté stiskneme Enter. Nyní máme vzorec v buňce K7, který obsahuje příjmy z prodeje zeleně pro tři filiálky.
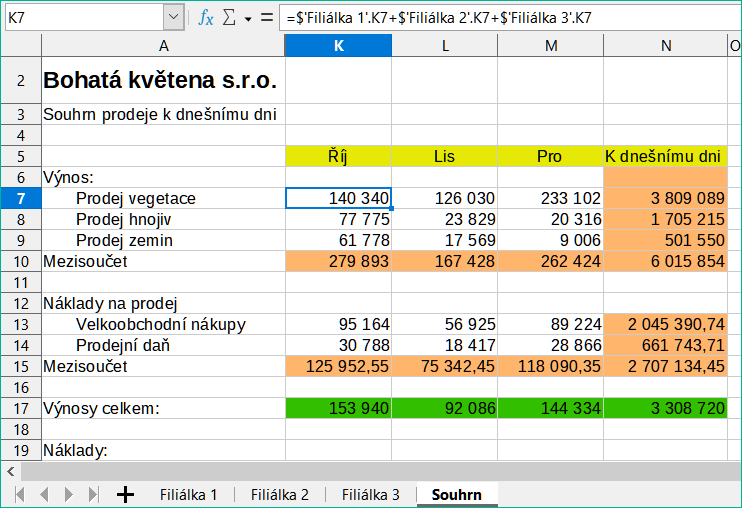
Obrázek 13: List Souhrn zobrazující odkazy mezi listy jednotlivých filiálek
Zkopírujeme vzorec, vybereme oblast K7:N17, v hlavní nabídce zvolíme Úpravy > Vložit jinak > Vložit jinak nebo klepneme pravým tlačítkem a z místní nabídky vybereme Vložit jinak > Vložit jinak nebo zmáčkneme Ctrl + Shift + V. V dialogu zrušíme výběr voleb Vložit vše a Formáty v části Vložit, zaškrtneme v ní všechny ostatní volby a klepneme na OK. Zobrazí se následující zpráva:
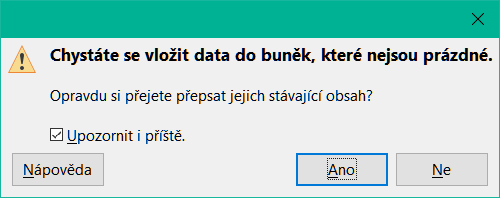
Obrázek 14: Propojení listů: vložení vzorce do oblasti buněk
Klepneme na Ano. Nyní jsme zkopírovali vzorce do každé buňky při zachování formátu nastaveného v původním listu. V tomto příkladu bychom samozřejmě měli upravit list odstraněním nul v řádcích bez formátování.
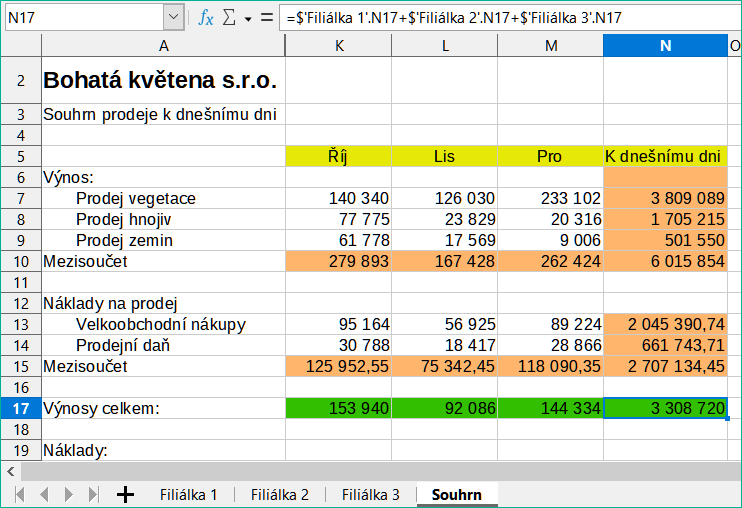
Obrázek 15: Propojení listů: Kopírovat/Vložit jinak z K7:N17
K provedení propojení lze také použít Průvodce funkcí. Použití tohoto průvodce je podrobně popsáno v části „Používání Průvodce funkcí“ na stránce 1.
Program Calc obsahuje více než 500 funkcí, které nám pomohou analyzovat a odkazovat na data. Mnoho z těchto funkcí se používá s čísly, ale jiné se používají s datumy a časy nebo dokonce s textem. Funkce může být stejně jednoduchá jako sčítání dvou čísel nebo nalezení průměru seznamu čísel, nebo může být stejně složitá jako výpočet standardní odchylky vzorku nebo hyperbolického tangens čísla.
Název funkce je obvykle zkrácený popis toho, co funkce dělá. Například funkce FV dává budoucí hodnotu investice (angl. future value), zatímco BIN2HEX převádí binární číslo na hexadecimální číslo. V programu Calc lze názvy funkcí zadávat velkými či malými písmeny nebo je kombinovat.
Několik základních funkcí je poněkud podobných operátorům. Příklady:
|
+ |
Tento operátor sčítá dvě čísla dohromady. SUM() na druhé straně sčítá skupiny sousedících oblastí čísel. |
|
* |
Tento operátor vynásobí dvě čísla dohromady. PRODUCT() dělá totéž pro násobení, jako SUM() pro sčítání. |
Každá funkce má řadu argumentů použitých ve výpočtech. Tyto argumenty mohou nebo nemusí mít svůj vlastní název. Vaším úkolem je zadat argumenty potřebné ke spuštění funkce. V některých případech mají argumenty předdefinované volby a možná je budeme muset najít v popiscích Průvodce funkcí, na kartě funkcí nebo v nápovědě. Častěji je však argumentem hodnota, kterou zadáváme ručně nebo je již zadaná do buňky nebo oblasti buněk v tabulce. V programu Calc můžeme zadat hodnoty z jiných buněk zadáním jejich názvu nebo oblasti, nebo – na rozdíl od některých tabulkových procesorů – výběrem buněk myší. Pokud se hodnoty v buňkách změní, bude výsledek funkce automaticky aktualizován.
Tip
Další podrobnosti o jednotlivých dostupných funkcích najdeme v oblasti Calc Functions na The Document Foundation Wiki na adrese https://wiki.documentfoundation.org/Documentation/Calc_Functions. Tyto stránky wiki nedávno rozšířily dostupnou dokumentaci a jsou neustále vylepšovány.
Pro mnoho funkcí Calc následuje standard OpenFormula definovaný v části 2 (Recalculated Formula (OpenFormula) Format) formátu Open Document Format for Office Applications (OpenDocument) verze 1.2. Tento standard je přístupný na webu OASIS (https://www.oasis-open.org/) nebo webové stránce ISO (https://www.iso.org/standard/66375.html). Obecná podpora OpenFormula v programu Calc poskytuje kompatibilitu s funkční sadou jakéhokoli jiného tabulkového procesoru, který dodržuje stejný standard. (V programu Calc jsou některé funkce, které nejsou v souladu s OpenFormula, ale mnoho z nich je zahrnuto především pro zlepšení výměny souborů mezi Calc a Microsoft Excel.)
Pro zlepšení interoperability je Calc schopen otevírat sešity vytvořené mnoha různými aplikacemi a ukládat je v mnoha různých formátech. V případě sady Microsoft Office je velmi snadné vyměňovat sešity mezi těmito dvěma aplikacemi. Když aplikace Calc otevře tabulku aplikace Microsoft Excel, automaticky podnikne kroky, aby se vyhnula nekompatibilitám, které by se jinak mohly vyskytnout u určitých funkcí.
Například když program Calc otevře soubor Excel, který obsahuje volání funkce Excel CEILING, jsou tyto funkce automaticky převedeny na referenční funkci programu Calc CEILING.XCL. Podobně, když program Calc uloží tabulku do formátu Microsoft Excel, automaticky podnikne kroky, aby se předešlo potenciálním nekompatibilitám. Příkladem toho je situace, kdy program Calc uloží sešit obsahující volání funkce FLOOR, které jsou automaticky převedeny na referenční funkci FLOOR.MATH aplikace Excel.
Na wiki nadace Document Foundation najdeme srovnání funkcí LibreOffice a Microsoft Office, viz https://wiki.documentfoundation.org/Feature_Comparison:_LibreOffice_-_Microsoft_Office. Toto srovnání ukazuje, že program Calc v současné době poskytuje 508 diskrétních funkcí, přičemž pouze 30 z nich je jedinečných pro Calc a zbytek má protějšky v aplikaci Microsoft Excel. Je zřejmé, že mezi funkcemi sady Calc a Excel existuje vysoká úroveň shodnosti a mnoho funkcí lze použít v obou aplikacích beze změn, čímž se zvyšuje interoperabilita.
Existují případy, kdy funkce programu Calc vytváří výsledek v souladu s mezinárodními standardy, ale výsledek se liší od výsledku vytvořeného ekvivalentní funkcí Excel. V takových případech má program Calc často podobně pojmenovanou funkci, ale k jejímu názvu byl přidán vhodný modifikátor (například „_ADD“ nebo „_EXCEL2003“), který poskytuje stejný výsledek jako funkce Excel.
Všechny funkce mají podobnou strukturu. Pokud použijeme správný nástroj pro zadání funkce, nemusíme se tyto struktury učit, ale v případě problému je vhodné je znát.
Typickým příkladem je struktura funkce k nalezení buněk, které odpovídají zadaným kritériím vyhledávání:
=DCOUNT(Databáze, Pole databáze, Kritéria hledání)
Funkce nemůže existovat sama o sobě; musí být vždy součástí vzorce. V důsledku toho, i když funkce představuje celý vzorec, musí být na začátku vzorce znaménko =. Bez ohledu na to, kde ve vzorci je funkce, bude funkce začínat svým názvem, například DCOUNT ve výše uvedeném příkladu. Za názvem funkce přichází její argumenty. Všechny argumenty jsou povinné, pokud nejsou výslovně uvedeny jako volitelné.
Argumenty jsou přidány do závorek a jsou odděleny středníky. Funkce Calc může obsahovat až 255 argumentů. Argumentem může být nejen číslo nebo jedna buňka, ale také pole nebo oblast buněk, které obsahují několik nebo dokonce stovky buněk.
V závislosti na povaze funkce lze argumenty zadávat jako v tabulce 7.
Tabulka 7: Zadávání argumentů funkce
|
Argument |
Popis |
|
"textová data" |
Uvozovky označují, že se zadává text nebo řetězcová data. |
|
9 |
Číslo devět zadáno jako číslo. |
|
"9" |
Číslo devět zadáno jako text. |
|
A1 |
Adresa čehokoliv, co je zadáno v buňce A1. |
|
B2:D9 |
Zadána oblast buněk. |
Funkce lze také použít jako argumenty v rámci jiných funkcí. Tyto funkce se nazývají vnořené funkce.
=SUM(2;PRODUCT(5;7))
Chceme-li získat představu o tom, co mohou vnořené funkce dělat, představme si, že navrhujeme samořízený výukový modul. Během modulu studenti dělají tři kvízy a výsledky zadávají do buněk A1, A2 a A3. V A4 můžeme vytvořit vnořený vzorec, který začíná průměrováním výsledků kvízů s vzorcem =AVERAGE(A1:A3). Vzorec poté pomocí funkce IF dává studentovi zpětnou vazbu, která závisí na průměrném ohodnocení kvízů. Celý vzorec by zněl:
=IF(AVERAGE(A1:A3)>85, „Gratulujeme! Jste připraveni postoupit k dalšímu modulu ";" Neúspěšně. Zkontrolujte prosím materiál znovu. V případě potřeby kontaktujte svého instruktora.“)
V závislosti na průměru obdrží student zprávu s blahopřáním nebo vyjádřením neúspěchu.
Všimněme si, že vnořený vzorec pro průměr nevyžaduje své vlastní znaménko rovnosti. Jeden na začátku rovnice je dostačující pro oba vzorce.
Pokud jsme v tabulkových procesorech nováčkem, nejlepší způsob, jak přemýšlet o funkcích, je skriptovací jazyk. Pro snadné vysvětlení konceptu jsme použili jednoduché příklady, ale pomocí vnoření funkcí se může vzorec v Calcu rychle stát složitým.
Poznámka
Calc zobrazuje syntaxi vzorce v bublinové nápovědě vedle buňky jako užitečnou paměťovou pomůcku při psaní.
Spolehlivější metodou je použití karty Funkce na postranní liště (obrázek 16), přístupné výběrem Zobrazit > Seznam funkcí nebo, pokud je postranní lišta zobrazena, klepnutím na ikonu Funkce v seznamu záložek na pravé straně lišty.
Obrázek 16: Karta Funkce v postranní liště
Karta Funkce obsahuje stručný popis každé funkce a jejích argumentů. Pro zobrazení popisu vybereme funkci a podíváme se do dolní části panelu. V případě potřeby najedeme ukazatelem myši na rozdělení mezi seznamem a popisem; jakmile se z ukazatele stane dvouhlavá šipka, táhneme ji nahoru, abychom zvětšili prostor pro popis. Poklepáním na název funkce ji přidáme do aktuální buňky spolu se zástupnými symboly pro každý z argumentů funkce.
Použití karty Funkce je téměř stejně rychlé jako ruční zadání a její výhodou je, že si nemusíme pamatovat vzorec, který chceme použít. Teoreticky by to mělo být také méně náchylné k chybám. V praxi však může být pro některé uživatele obtížné nahrazovat zástupné symboly hodnotami. Další funkcí je schopnost zobrazit poslední použité vzorce.
Nejběžněji používanou metodou vstupu je Průvodce funkcemi (obrázek 17). Chceme-li jej otevřít, zvolíme Vložit > Funkce nebo klepneme na ikonu Průvodce funkcemi na liště funkcí, nebo stiskneme Ctrl + F2. Průvodce funkcemi poskytuje stejné funkce nápovědy jako karta Funkce, ale přidává pole, ve kterých můžeme vidět výsledek dokončené funkce, jakož i výsledek jakéhokoli většího vzorce, jehož je součástí.
Obrázek 17: Karta Funkce Průvodce funkcí
Pro zkrácení seznamu vybereme kategorii funkcí, potom projdeme dolů názvy funkcí a vybereme požadovanou funkci dvojitým klepnutím. Dostupné kategorie v Průvodci funkcí a počet funkcí dostupných v každé kategorii jsou uvedeny v tabulce 8. Když vybereme funkci, její popis se objeví na pravé straně dialogu. Volitelně můžeme zadat název funkce do pole Hledat a vyhledávání se zúží na každý vložený znak (obrázek 17).
Tabulka 8: Kategorie funkcí v Průvodci funkcí
|
Kategorie |
Počet funkcí podle kategorií |
|
Doplňky |
48 |
|
Matice |
15 |
|
Databáze |
12 |
|
Datum a čas |
36 |
|
Finanční |
63 |
|
Informace |
21 |
|
Logické |
11 |
|
Matematické |
82 |
|
Sešit |
22 |
|
Statistické |
151 |
|
Text |
47 |
Průvodce nyní zobrazí oblast vpravo, kde můžeme ručně zadat data do textových polí nebo kliknout na tlačítko Zmenšit, čímž se zmenší průvodce a můžeme vybrat buňky z listu.

Obrázek 18: Průvodce funkcí po zmenšení
Chceme-li vybrat buňky, klepneme buď přímo na buňku, nebo podržíme levé tlačítko myši a tažením vybereme požadovanou oblast.
Po výběru oblasti klepneme na ikonu Rozvinout a znovu se vrátíme do průvodce.
Pokud potřebujeme více argumentů, klepneme do dalšího textového pole a zopakujeme proces výběru pro další buňku nebo oblast buněk. Tento postup opakujeme podle potřeby. Průvodce umožní až 255 oblastí nebo argumentů ve funkci SUM.
Klepnutím na tlačítko OK potvrdíme funkci, vložíme ji do buňky a dostaneme výsledek.
Poznámka
Pokud vybereme funkci dvojitým klepnutím v seznamu a poté změníme názor a vybereme jinou dvojitým kliknutím znovu, přidá se vzorec druhé volby do vzorce první volby v textovém poli Vzorec. Musíte vymazat textové pole Vzorec a potom poklepáním na funkci přidat do pole.
Toto doplňování vzorců umožňuje vytvářet složité vzorce jejich sestavováním v textovém poli Vzorec.
Můžeme také vybrat kartu Struktura, kde uvidíme stromové zobrazení částí vzorce. Hlavní výhoda oproti kartě Funkce je, že každý argument se vkládá do svého vlastního pole, což usnadňuje správu. Cena této spolehlivosti je pomalejší zadávání, ale při vytváření sešitu je přesnost obecně důležitější než rychlost.
Zobrazení struktury vzorce v průvodci je důležité pro ladění a opravu velmi dlouhých, vnořených a složitých vzorců. V tomto pohledu je vzorec analyzován a každá složka vzorce je vypočítána jednodušším vyvoláním funkce nebo aritmetickou operací a poté je zkombinována podle pravidel výpočtu. Je možné vizualizovat každý analyzovaný prvek vzorce a zkontrolovat, zda jsou mezilehlé výsledky správné, dokud není nalezena chyba.
Funkce lze zadat do vstupního řádku. Po zadání funkce na vstupní řádce stiskneme klávesu Enter nebo klepneme na tlačítko Přijmout na liště vzorců. Tím se funkce přidá do buňky a získáme její výsledek.

|
1 |
Pole Název zobrazující seznam běžných funkcí |
||
|
2 |
Průvodce funkcí |
4 |
Přijmout |
|
3 |
Zrušit |
5 |
Vstupní řádek |
Obrázek 19: Lišta vzorců
Pokud vidíme v buňce místo výsledku vzorec, pak je vybrána volba Vzorce v sekci Zobrazení dialogového okna Nástroje > Možnosti > LibreOffice Calc > Zobrazit. Zrušíme výběr Vzorce a zobrazí se výsledek. Stále však můžeme vidět vzorec ve vstupním řádku.
Tip
Možnost nabídky Zobrazit > Zobrazit vzorec a klávesová zkratka v Linuxu/Windows Ctrl + ` (obrácená čárka) také zapíná a vypíná zobrazení vzorce.
Vzorec, ve kterém se vyhodnocují jednotlivé hodnoty v oblasti buněk, se označuje jako maticový vzorec. Rozdíl mezi maticovým vzorcem a jinými vzorci je v tom, že maticový vzorec pracuje s několika hodnotami najednou namísto pouze jedné.
Nejenže maticový vzorec zpracovává několik hodnot najednou, ale také může vícero hodnot najednou vrátit Výsledek maticového vzorce je také matice.
Když program Calc aktualizuje vzorce, každá ovlivněná buňka se načte a její vzorec se přepočítá. Pokud máme ve sloupci se stejným vzorcem tisíc buněk (výraz vzorce pouze změní data, která se mají vypočítat), znamená to interpretaci a provedení tisíce stejných vzorců.
Maticové vzorce vyhodnotí vzorec jednou a provedou výpočty tolikrát, kolikrát je velikost pole, čímž se ušetří čas potřebný k interpretaci každého vzorce v buňce. A protože program Calc ukládá pouze jeden vzorec pro celé pole datových buněk, šetří také místo v souboru sešitu.
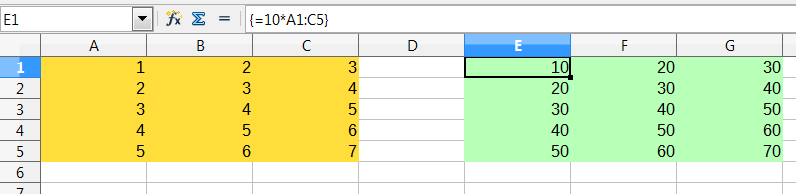
Obrázek 20: Zdrojové pole žluté a výsledné pole zelené. Maticový vzorec je zobrazen na liště vzorců.
Chceme-li vynásobit hodnoty v jednotlivých buňkách deseti ve výše uvedeném poli (obrázek 20), nemusíme použít vzorec pro každou jednotlivou buňku nebo hodnotu. Místo toho stačí použít jeden maticový vzorec. Vybereme rozsah 3 x 5 buněk v jiné části tabulky, zadáme vzorec =10*A1:C5 a tento zápis potvrdíme kombinací kláves Ctrl + Shift + Enter. Výsledkem je pole 3 × 5, ve kterém jsou jednotlivé hodnoty v rozsahu buněk (A1:C5) vynásobeny číslem 10.
Kromě násobení můžeme v referenční oblasti (pole) použít také další operátory. Můžeme sčítat (+), odečítat (-), násobit (*), dělit (/), použít exponenty (^), zřetězení (&) a porovnání (=, <>, <, >, <=, >=). Pokud byl zadán maticový vzorec lze použít operátory pro každou jednotlivou hodnotu v oblasti buněk a vrátit výsledek jako pole.
Operátory porovnání v maticovém vzorci zpracovávají prázdné buňky stejným způsobem jako v normálním vzorci, tj. buď jako nula, nebo jako prázdný řetězec. Pokud jsou například buňky A1 a A2 prázdné, maticové vzorce {=A1:A2=""} a {=A1:A2=0} vrátí oba pole o velikosti 1 sloupec a 2 řádky s hodnotami PRAVDA.
Pokud musíme opakovat výpočty pomocí různých hodnot, použijeme maticové vzorce. Pokud se rozhodneme později změnit metodu výpočtu, musíme aktualizovat pouze maticový vzorec. Chceme-li přidat maticový vzorec, vybereme celou oblast pole a potom provedeme požadovanou změnu maticového vzorce.
Pole jsou nezbytným nástrojem pro provádění složitých výpočtů, protože do výpočtů můžeme zahrnout několik oblastí buněk. Program Calc má různé matematické funkce pro pole, jako je funkce MMULT pro vynásobení dvou polí.
Pokud vytvoříme maticový vzorec pomocí Průvodce funkcí, musíme pokaždé označit zaškrtávací políčko Matice, aby výsledky byly vráceny v matici (obrázek 17). Jinak bude vrácena pouze hodnota v levé horní buňce vypočítaného pole.
Maticový vzorec lze také zadat přímo do buňky. Výsledkem bude automaticky vytvořené pole buněk.
Poznámka
Maticové vzorce se v programu Calc zobrazují v závorkách (složených závorkách). Maticové vzorce nelze vytvořit ručně zadáním složených závorek.
Poznámka
Buňky v poli výsledků jsou automaticky chráněny proti změnám. Maticový vzorec však můžeme upravit nebo zkopírovat výběrem celé oblasti maticového vzorce.
Vzorce, které provádějí více než jednoduchý výpočet, součet řádků nebo sloupců hodnot, obvykle obsahují řadu argumentů. Zvažme například následující rovnici:
|
{ x = x _ i + v _ i t + { 1 over 2 } at ^ 2 } |
Tato rovnice modeluje polohu objektu, který se pohybuje lineárně s konstantním zrychlením. Poloha (x) závisí na čase (t) a rovnice také obsahuje konstantní hodnoty pro počáteční polohu (xi), počáteční rychlost (vi) a zrychlení (a).
Pro snadnou prezentaci je vhodné sestavit tabulku podobným způsobem, jaký je uveden na obrázku 21. V tomto příkladu jsou jednotlivé proměnné vkládány do buněk na listu a není nutná žádná úprava vzorce.
Při vytváření vzorce můžeme použít několik přístupů. Při rozhodování, jaký přístup zvolit, vezmeme v úvahu, kolik dalších lidí bude muset listy používat, životnost listů a variace, s nimiž by se mohli při použití vzorce setkat.
Pokud budou sešit používat jiní lidé než my, ujistíme se, že je snadné zjistit, jaký vstup je vyžadován a kde. Na prvním listu je často umístěno vysvětlení účelu sešitu, základu pro výpočet, požadovaného vstupu a generovaného výstupu.
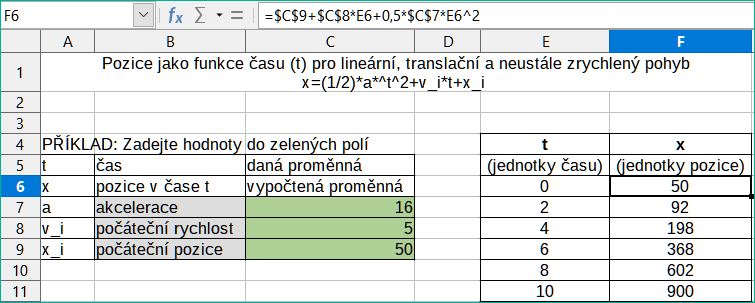
Obrázek 21: Nastavení vzorce s argumenty
U sešitu s mnoha komplikovanými vzorci, který vytvoříme dnes, nemusí být zcela za 6 nebo 12 měsíců zřejmé, jak měl fungovat. Pro zdokumentování je vhodné používat komentáře a poznámky.
Možná si uvědomujeme, že pro konkrétní argument nemůžeme použít záporné nebo nulové hodnoty, ale pokud někdo jiný vloží takovou hodnotu, bude náš vzorec robustní nebo jednoduše vrátí standardní (a často ne příliš užitečnou) chybovou zprávu? Je vhodné zachytit chyby pomocí nějaké formy logických příkazů nebo podmíněným formátováním.
Základní strategií je považovat všechny potřebné vzorce za jednoduché a s omezenou životností. Strategií je pak umístit jedinečný vzorec do každé vhodné buňky. To lze doporučit pouze pro velmi jednoduché nebo jednorázové sešity.
Druhá strategie je podobná té první, ale místo toho rozdělujeme delší vzorce na menší části a poté je zkombinujeme do celku. Mnoho příkladů tohoto typu existuje ve složitých vědeckých a technických výpočtech, kde se prozatímní výsledky používají na řadě míst v listu. Výsledek výpočtu rychlosti proudění vody v potrubí může být použit pro odhad ztrát v důsledku tření, kdy potrubí protéká zcela nebo částečně prázdné, a při optimalizaci průměru pro daný režim průtoku.
Ve všech případech bychom měli přijmout základní principy tvorby vzorců popsané výše.
Tabulky se často používají ke zpracování surových dat a k vytváření smysluplných shrnutí, konsolidace a zobrazování informací pro osobu s rozhodovací pravomocí nebo k použití jako zdroj pro reporty. Surová data mohou být získána fyzickými měřeními, obchodními transakcemi nebo různými jinými způsoby. Ve finančních odděleních nebo laboratořích se často nacházejí listy s tisíci nebo dokonce stovkami tisíc řádků a několika sloupci. Výpočty prováděné na těchto zdrojových souborech dat mohou být časově náročné a trvat minuty, hodiny a možná i dny.
Častou chybou je vložení vzorců do každé buňky a provedení tisíce interpretací a výpočtů vzorců. Zde je několik doporučení pro urychlení výpočtů.
Maticové vzorce mají jeden vzorec aplikovaný na množství dat. Pro velké datové sady může být významná úspora výpočtů.
Konsolidační funkce provádějí výpočty na souborech dat. SUM, SUMIF, SUMIFS, SUMPRODUCT jsou příklady konsolidačních funkcí. Například, pokud máme velmi dlouhý seznam materiálu, kde množství musí být vynásobeno jednotkovou cenou a pak sečteno, aby se vytvořila hodnota nákladů, pak místo použití vzorce na každý záznam kusovníku a pak sečtení, můžeme použít vzorec SUMPRODUCT(množství; jednotková cena), kde množství a jednotková cena jsou pojmenované oblasti představující kusovník. SUMPRODUCT násobí každou buňku množství její odpovídající buňkou jednotkové ceny a sečte všechny produkty.
Podobné situace nastávají, když musíme sčítat podmnožinu původní sady dat, kde musíme použít test na každý záznam, aby bylo možné jej použít do součtu. Například když je hodnota pouze kladná. Použijeme SUMIF(data_pro_test;”>0”;data_pro_součet), kde data_pro_test je sada dat, ve které testujeme kladné hodnoty, data_pro_součet je sloupec, kde mají být hodnoty součtu v závislosti na testu, a „>0“ je samotný test.
Dalšími konsolidačními funkcemi jsou AVERAGEIF, COUNTIF, MINIFS, MAXIFS a další.
Další strategií je vytvoření vlastních funkcí a maker. Tento přístup by se použil tam, kde by výsledek výrazně zjednodušil použití sešitu koncovým uživatelem a udržel vzorce jednoduché s větší šancí vyhnout se chybám. Tento přístup také může usnadnit údržbu tím, že opravy a aktualizace budou uloženy na jednom centrálním místě. Použití maker je popsáno v kapitole 12, Makra a je samo o sobě specializovaným tématem. Nebezpečí nadužívání maker a uživatelských funkcí spočívá v tom, že principy, na nichž je sešit založen, se stávají mnohem obtížnějšími pro zobrazení jiným uživatelem než původním autorem (a někdy dokonce i autorem)!
Mnoho moderních počítačů má vícejádrové procesory a poskytuje více vláken. Jádro je fyzická součást hardwaru v CPU. Vlákna jsou virtuální komponenty, které pomáhají efektivně řídit pracovní vytížení a úkoly CPU. CPU může interagovat s více než jedním vláknem najednou a díky více vláknům jsou CPU efektivnější a poskytují lepší celkový výkon.
Program Calc podporuje vícevláknové procesy, které pomáhají sešitům využívat veškerého paralelního zpracování, které je v počítači k dispozici. Tato funkce je řízena volbou Povolit vícevláknové výpočty v sekci Nastavení vláken CPU v dialogovém okně Nástroje > Možnosti > LibreOffice Calc > Výpočty. Výchozí nastavení této možnosti je povoleno a nedoporučuje se ji deaktivovat. Toto je jediný ovládací prvek v uživatelském rozhraní programu Calc, který se týká vícevláknového zpracování; jakmile je zapnuto, zpracování pracuje automaticky.
Pokud je povoleno vícevláknové zpracování, program Calc automaticky identifikuje, kde by náš sešit mohl těžit z vícevláknového zpracování a podle toho je zpracovává. Vlákna se obecně používají pro skupiny vzorců, kde dostatek sousedních buněk ve sloupci používá stejný vzorec, ale z různými výsledky kvůli relativnímu adresování buněk. Jedním z důsledků tohoto přístupu je to, že optimalizace je založena na sloupcích, takže rozložení na řádcích může být méně efektivní.
Existují i jiné způsoby, jak řídit vícevláknovou funkci Calc, jako je úprava proměnné prostředí LibreOffice MAX_CONCURRENCY. Tyto metody však přesahují rámec tohoto dokumentu.
Je běžné narazit na situace, kdy se zobrazují chyby. I se všemi nástroji, které jsou k dispozici v programu Calc a pomáhají nám zadávat vzorce je snadné dělat chyby. Mnoho lidí považuje zadání čísel za obtížné a mnoho z nich může udělat chybu, pokud jde o druh vstupu, který potřebuje argument funkce. Kromě oprav chyb můžeme chtít najít buňky použité ve vzorci, abychom změnili jejich hodnoty nebo zkontrolovali odpovědi.
Program Calc poskytuje tři nástroje pro zkoumání vzorců a buněk, na které odkazují: chybové zprávy, barevné kódování pro vstup a nástroj Detektiv.
Nejzákladnějším nástrojem jsou chybové zprávy. Chybové zprávy se zobrazují v buňce vzorce, na stavovém řádku nebo v Průvodci funkcí místo výsledku.
Chybová zpráva pro vzorec je obvykle trojciferné číslo od 501 do 540 nebo někdy obecný kus textu, jako je #NAME?, #REF! nebo #VALUE!. V buňce se zobrazí chybová zpráva a na pravé straně stavového řádku se zobrazí krátké vysvětlení chyby.
Většina chybových zpráv hlásí problém v zadání vzorce, několik pak oznamuje, že jsme narazili na omezení programu Calc nebo jeho aktuálního nastavení.
Chybové zprávy nejsou uživatelsky přívětivé a mohou nové uživatele překvapit. Jsou však cenným vodítkem k opravě chyb. Jejich podrobné vysvětlení najdeme v dodatku B – Kódy chyb, v nápovědě a hledáním „chybových kódů" v Calc. Některé z nejčastějších jsou uvedeny v tabulce 9.
Tabulka 9: Běžné chybové zprávy
|
Kód |
Význam |
|
#NAME? |
Místo zobrazení Err:525. Pro argument neexistuje platný odkaz. |
|
#REF! |
Místo zobrazení Err:524. Chybí sloupec, řádek nebo list pro odkazovanou buňku. |
|
#VALUE! |
Místo zobrazení Err:519. Hodnota jednoho z argumentů není typu, který argument vyžaduje. Hodnota může být zadána nesprávně; například kolem hodnoty mohou chybět uvozovky. Jindy může mít použitá buňka nebo oblast nesprávný formát, například text namísto čísel. |
|
#DIV/0! |
Místo zobrazení Err:532. Dělení nulou. |
|
#NUM! |
Místo zobrazení Err:503. Výsledkem výpočtu je přetečení definovaného rozsahu hodnot. |
|
509 |
Ve vzorci chybí operátor, například znaménko rovnosti. |
|
510 |
Ve vzorci chybí proměnná. |
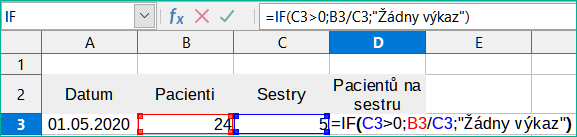
Tato chyba je výsledkem dělení čísla nulou (0) nebo prázdnou buňkou. Existuje jednoduchý způsob, jak se tomuto problému vyhnout. Pokud máme zobrazenu nulovou nebo prázdnou buňku, použijeme podmíněnou funkci. Obrázek 22 znázorňuje dělení sloupce B sloupcem C, což vede k 2 chybám vyplývajícím z nuly a prázdné buňky znázorněné ve sloupci C.
Je velmi časté najít chybu, jako je ta, která vznikla v situaci, kdy data nebyla reportována nebo reportována nesprávně. Pokud je takový výskyt možný, lze pro správné zobrazení dat použít funkci IF. Lze zadat vzorec =IF(C3>0; B3/C3; "Žádný výkaz"). Vzorec je potom zkopírován do zbytku sloupce D. Význam tohoto vzorce by byl zhruba: “Pokud je C3 větší než 0, pak vypočítej B3 děleno C3, jinak vypiš “Žádný výkaz.“ Příklad je znázorněn na obrázku 23.
Je také možné, aby poslední parametr používal dvojité uvozovky pro prázdné (žádné hodnoty), nebo aby se spodní číslo nahradilo jiným vzorcem se standardizovaným číslem.
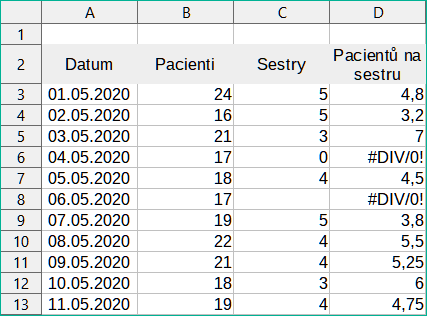
Obrázek 22: Příklady #DIV/0!, chyba dělení nulou
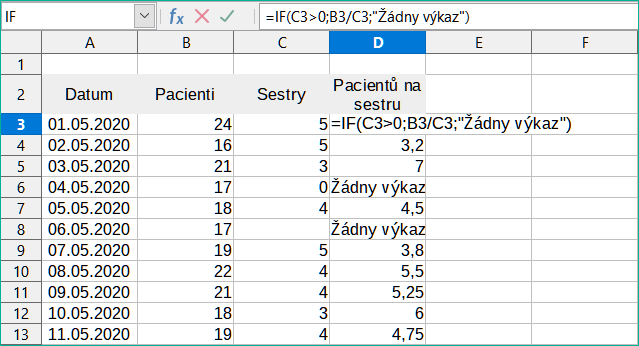
Obrázek 23: Řešení dělení nulou
Chyba #VALUE! je také velmi častá.
Obvyklý výskyt této chyby nastane, když buňka obsahuje nesprávný typ hodnoty. V příkladu na obrázku 24 byl do C8 vložen text „None“, kde náš vzorec ve sloupci D očekává číslo.
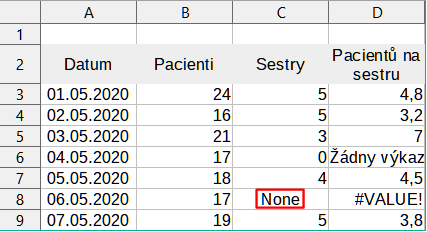
Obrázek 24: Nesprávná položka způsobující #VALUE! chyba
Chyba #REF! je způsobena chybějícím odkazem. V příkladu zobrazeném na obrázku 25 odkazuje vzorec na list, který byl odstraněn.

Obrázek 25: Smazaný list, způsobující #REF! chyba
Dalším užitečným nástrojem při kontrole vzorce je barevné kódování vstupu. Když vybereme vzorec, který již byl zadán, jsou buňky nebo oblasti použité pro každý argument ve vzorci se barevně zvýrazní.
Obrázek 26: Barevné kódování pro vstup
Program Calc používá osm barev pro zvýraznění referenčních buněk, počínaje modrou pro první buňku, a pokračující červenou, purpurovou, zelenou, tmavě modrou, hnědou, fialovou a žlutou, což se cyklicky opakuje v sekvenci.
Existují situace, kdy je zobrazení obsahu buněk stejné, i když je datový typ odlišný. Například text a číslo mohou vypadat stejně, ale může dojít k chybě, pokud se v některých výpočtech zamění. Pro ilustraci lze řetězec „10,35“ zarovnaný doprava v buňce zaměnit s hodnotou 10,35. Když je buňka použita ve vzorci, řetězec může mít hodnotu nula a může dojít k chybě.
Pokud povolíme zvýraznění hodnot (Zobrazit > Zvýrazňování hodnot nebo Ctrl + F8), program Calc rozlišuje textové a číselné datové typy barvou. Ve výchozím nastavení je text černými znaky a čísla modře. Další informace o zvýrazňování hodnot nalezneme v kapitole 2 – Zadávání, úpravy a formátování dat.
V dlouhé nebo komplikované tabulce je barevné zvýraznění méně užitečné. V těchto případech můžeme použit podnabídky pod položkou Nástroje > Detektiv. Detektiv je nástroj pro kontrolu, které buňky jsou použity jako argumenty vzorce (předchůdci) a které další vzorce jsou vnořeny (následníci), a chyb závislostí. Lze jej také použít pro trasování chyb, označování neplatných dat (to je informace v buňkách, která není ve správném formátu pro argument funkce), nebo dokonce pro odstranění předchůdců a následníků.
Chceme-li použít nástroj Detektiv, vybereme buňku se vzorcem a poté vybereme požadovanou možnost v nabídce Nástroje > Detektiv. V tabulce uvidíme čáry končící tečkami, které označují předchůdce, a čáry končící šipkami pro následníky. Řádky ukazují tok informací.
Nástroj Detektiv použijeme při sledování předchůdců uvedených ve vzorci v buňce. Sledováním těchto předchůdců můžeme často najít zdroj chyb. Kurzor umístíme do příslušné buňky a poté na panelu nabídek zvolíme Nástroje > Detektiv > Sledovat předchůdce nebo stiskneme Shift + F9. Obrázek 27 ukazuje jednoduchý příklad trasování předchůdců pro buňku B4.
To nám umožňuje zkontrolovat, zda zdrojové buňky (což může být i oblast) nevykazují chyby. Pokud je zdrojem oblast, je tento rozsah zvýrazněn modře.
Obrázek 27: Sledování předchůdců pomocí nástroje Detektiv
V jiných případech bude možná nutné vyhledat závislosti chyby. K tomu používáme funkci Vyhledat závislosti chyby v Nástroje > Detektiv > Vyhledat závislosti chyby a vyhledáme buňky, které chybu způsobily.
Další informace vyhledáme v rejstříku systému nápovědy pod heslem „Detektiv“.
Pro nováčky jsou funkce jednou z nejvíce obtížných oblastí v LibreOffice Calc. Noví uživatelé rychle zjistí, že funkce jsou důležitou vlastností tabulek, ale existují jich stovky a mnoho z nich vyžaduje vstup, který předpokládá specializované znalosti. Naštěstí Calc obsahuje mnoho funkcí, které může použít kdokoli.
Nejzákladnější funkce vytvářejí vzorce pro základní aritmetiku nebo pro vyhodnocení čísel v oblasti buněk.
Mezi jednoduché aritmetické funkce patří sčítání, odčítání, násobení a dělení. S výjimkou odčítání má každá z těchto operací svou vlastní funkci:
SUM pro sčítání
PRODUKT pro násobení
QUOTIENT pro dělení
SUM, PRODUCT a QUOTIENT jsou užitečné pro zadávání oblastí buněk stejným způsobem jako u jakékoli jiné funkce, s argumenty v závorce za názvem funkce.
U základních rovnic však mnoho uživatelů dává přednost počítačovým symbolům pomocí znaménka plus (+) pro sčítání, pomlčky (-) pro odčítání, hvězdičky (*) pro násobení a lomítka (/) pro dělení. Tyto symboly se rychle zadávají a jsou jednoduše dostupné na klávesnici.
Podobná volba je také k dispozici pro umocnění čísla jiným číslem. Místo zadání =POWER(A1;2) můžeme zadat =A1^2.
Kromě toho mají tu výhodu, že s nimi zadáváme vzorce v pořadí, které se blíží lidsky čitelnému formátu více než formát čitelný tabulkovým procesorem používaný ekvivalentní funkcí. Například místo zadávání =SUM(A1:A2) nebo případně =SUM(A1;A2) zadáme =A1+A2. Tento téměř lidsky čitelný formát je zvláště užitečný pro složené operace, kde zápis =A1*(A2+A3) je kratší a snáze čitelný než =PRODUCT(A1;SUM(A2:A3)).
Hlavní nevýhoda použití aritmetických operátorů spočívá v tom, že nemůžeme přímo použít oblast buněk. Jinými slovy, pro zadání ekvivalentu =SUM(A1:A3) je třeba zadat =A1+A2+A3.
Zda používáme funkci nebo operátor, je z velké části na nás – samozřejmě s výjimkou odčítání. Pokud však tabulky používáme pravidelně ve skupině, například ve třídě nebo kanceláři, možná budeme chtít standardizovat vstupní formát, aby si každý, kdo tabulku zpracovává, zvykl na standardní vstup.
Dalším běžným využitím funkcí tabulkového procesoru je vytažení užitečných informací ze seznamu, například série testů ve třídě nebo souhrn výdělků za čtvrtletí pro společnost.
Samozřejmě můžeme prohledat seznam čísel, pokud chceme základní informace, jako je nejvyšší nebo nejnižší položka nebo průměr. Jediným problémem je, že čím delší je seznam, tím více času ztrácíme a tím je pravděpodobnější, že vynecháme to, co hledáme. Místo toho je obvykle rychlejší a efektivnější zadat funkci. Takové důvody vysvětlují existenci funkce, jako je COUNT, která vrací pouze celkový počet záznamů v určené oblasti buněk.
Podobně pro nalezení nejvyšší nebo nejnižší položky můžeme použít MIN nebo MAX. Pro každý z těchto vzorců jsou všechny argumenty buď oblast buněk, nebo řada buněk zadaných jednotlivě.
Každá má také související funkci MINA nebo MAXA, která vykonává stejnou funkci, ale také zachází s buňku formátovanou jako text jako s hodnotu 0. Stejné zacházení s textem se vyskytuje v jakékoli variantě jiné funkce, která na konec přidá „A“. Každá funkce poskytuje stejný výsledek a může být užitečná, pokud jsme například pomocí textového zápisu uvedli, že v době, kdy byl psán test, byli studenti nepřítomní a chtěli jsme zkontrolovat, zda naplánovat náhradní zkoušku.
Pro větší flexibilitu při podobných operacích bychom mohli použít LARGE nebo SMALL, které přidávají specializovaný argument pořadí. Pokud je s LARGE použito pořadí 1, dostaneme stejný výsledek jako s MAX. Pokud je však pořadí 2, je výsledkem druhý největší výsledek. Podobně, pořadí 2 použité se SMALL nám dává druhé nejmenší číslo. LARGE i SMALL jsou vhodné jako trvalá kontrola, protože změnou argumentu pořadí můžeme rychle prohledat více výsledků.
Museli bychom být odborníkem, abychom našli Poissonovu distribuci vzorku, nebo našli zkosenou nebo negativní binomii distribuce (a pokud jsme, v programu Calc pro takové věci najdeme funkce). Pro nás ostatní však existují jednodušší statistické funkce, které se můžeme rychle naučit používat.
Zejména pokud potřebujeme průměr, musíme si vybrat z několika funkcí. Aritmetický průměr, tj. výsledek, který získáme sečtením všech položek v seznamu a následným vydělením počtem položek, můžeme zjistit zadáním rozsahu čísel při použití příkazu AVERAGE nebo AVERAGEA, pokud chceme zahrnout textové položky a přiřadit jim nulovou hodnotu.
Kromě toho můžeme získat další informace o sadě dat:
MEDIAN: Logicky řadí čísla (od nejnižší k nejvyšší) pro vyhodnocení střední hodnoty. V sadě, která obsahuje nerovnoměrný počet hodnot, bude mediánem číslo uprostřed seznamu. V sadě, která obsahuje sudý počet hodnot, bude střední hodnota průměrem ze dvou hodnot uprostřed seřazeného seznamu.
MODE: Nejběžnější položka v seznamu čísel.
QUARTILE: Záznam na nastavené pozici v poli čísel. Kromě rozsahu buněk zadáte typ kvartilu: 0 pro nejnižší položku, 1 pro hodnotu 25 %, 2 pro hodnotu 50 %, 3 pro 75 % a 4 pro nejvyšší položku. Výsledek u typů 1 až 3 nemusí představovat skutečně zadanou položku.
RANK: Pozice dané položky v celém seznamu, měřená shora dolů nebo zdola nahoru. Je třeba zadat adresu buňky pro položku, rozsah položek a typ pořadí (0 pro pořadí od nejvyššího nebo jakoukoli jinou hodnotu pro pořadí od nejnižšího).
Některé z těchto funkcí se překrývají; například MIN a MAX jsou obě pokryty QUARTILE. V jiných případech může vlastní řazení nebo filtr poskytnout téměř stejný výsledek. To, co používáme, závisí na našich zvyklostech a potřebách. Někteří možná dávají přednost použití MIN a MAX, protože jsou snadno zapamatovatelné, zatímco jiní dávají přednost QUARTILE, protože je univerzálnější.
V některých případech je u některých z těchto funkcí možné získat podobné výsledky nastavením filtru nebo vlastního třídění. Obecně jsou však funkce snadněji nastavitelné než filtry nebo třídění a poskytují širokou škálu možností.
Někdy můžeme chtít jen zadat dočasně jeden nebo více vzorců do vhodné prázdné buňky a po dokončení je odstranit. Pokud však narazíme na to, že neustále používáme stejné funkce, měli bychom zvážit vytvoření šablony a vyhradit místo pro všechny funkce, které používáme, přičemž buňka vlevo slouží jako popisek. Po vytvoření šablony můžeme snadno aktualizovat každý vzorec podle změn položek, a to buď automaticky a za běhu, nebo stisknutím klávesy F9 pro k aktualizaci všech vybraných buněk.
Bez ohledu na to, jak tyto funkce používáme, pravděpodobně zjistíme, že jsou snadno použitelné a přizpůsobitelné mnoha účelům. Poté co zvládneme tyto jednodušší funkce budeme připraveni vyzkoušet složitější funkce.
Pro statistické a matematické účely obsahuje program Calc různé způsoby zaokrouhlení čísel. Některé z těchto metod jsou známé programátorům. Nemusíme však být specialistou, abychom používali některé z těchto užitečných metod. Možná budeme chtít zaokrouhlovat za účelem fakturace, nebo proto, že desetinná místa se do fyzického světa dobře nepřevádějí – například pokud součástky, které potřebujeme jsou v balení po 100, pak skutečnost, že potřebujeme pouze 66, je pro nás irelevantní; pro objednání je třeba zaokrouhlit nahoru. Naučíme-li se možnosti zaokrouhlení nahoru nebo dolů, můžeme naše tabulky učinit užitečnějšími.
Při použití funkce zaokrouhlování máme dvě možnosti, jak nastavit vzorce. Pokud se rozhodneme, můžeme vnořit výpočet do jedné z funkcí zaokrouhlování. Například vzorec =ROUND((SUM(A1;A2)) přidá čísla do buněk A1 a A2 a zaokrouhlí je na nejbližší celé číslo. I když nemusíme pracovat s přesnými údaji každý den, můžeme se na ně občas odkazovat. Pokud je tomu tak, pak je pravděpodobně lepší oddělit obě funkce, umístit =SUM(A1;A2) do buňky A3 a =ROUND(A3) do A4 a jasně označit každou funkci.
Podrobnosti o metodách zaokrouhlování nalezneme v nápovědě.
Otevřený formát dokumentů pro kancelářské aplikace (OpenDocument) verze 1.2 obsahuje následující definici: „Funkce, které se vždy přepočítávají, kdykoli dojde k přepočtu, se označují jako volatilní funkce.“
Abychom pochopili některá chování volatilní funkce v programu Calc, zvažme jednoduchý příklad, ve kterém jsme vytvořili prázdnou tabulku a zadali vzorec =RAND() do buňky A1 (RAND je jedna z volatilních funkcí programu Calc). Program Calc zobrazí v buňce A1 náhodné číslo mezi 0 a 1. Pokud pak zadáme libovolnou hodnotu do jiné buňky (pro účely této diskuse řekněme do buňky B2) a stiskneme klávesu Enter, zjistíme, že hodnota zobrazená v buňce A1 se aktualizovala a je v ní jiné náhodné číslo. Calc přepočítá náhodné číslo v A1, navzdory tomu, že uživatel nezměnil vzorec v A1 a navzdory tomu, že aktualizované B2 nemá žádný odkaz na A1. Stručně řečeno funkce RAND generuje novou hodnotu při aktualizaci libovolné buňky výběrem Data > Vypočítat > Přepočítat nebo stisknutím F9, případně při jakékoli vstupní události.
Pochopení volatilních funkcí je důležité, zejména pokud vytváříme velkou tabulku, kde časté přepočty mohou nepříznivě ovlivnit výkon. Ujistíme se, že jsme sešit navrhli tak, aby správně používal volatilní funkce.
Následující funkce programu Calc jsou volatilní:
FORMULA
INDIRECT
INFO
NOW
OFFSET
RAND
RANDBETWEEN
TODAY
Pro funkce RAND a RANDBETWEEN nabízí program Calc nevolatilní náhrady – RAND.NV a RANDBETWEEN.NV. Mohou být užitečné, když nepotřebujeme tak často aktualizovat hodnoty funkcí. Nevolatilní funkce se při nových vstupních událostech nepřepočítá a znovu se nepočítá při výběru Data > Spočítat > přepočítat nebo zmáčknutí F9, s výjimkou pokud není buňka obsahující funkci vybrána. Při otevření souboru jsou nevolatilní funkce přepočítány.
Calc podporuje použití zástupných znaků nebo regulárních výrazů v argumentech mnoha svých funkcí.
Regulární výrazy nabízejí výkonné metody hledání textových řetězců. Další informace o regulárních výrazech včetně příkladů nalezneme v části „Regulární výrazy“ v kapitole 1, Úvod.
Pokud je pro naši tabulku důležitá interoperabilita s Microsoft Excel, možná nebudeme moci plně využívat možnosti regulárních výrazů programu Calc, protože Excel neposkytuje ekvivalentní funkce. Když tedy exportujeme tabulku Calc do formátu Excel, informace týkající se regulárních výrazů nebudou v aplikaci Excel použitelné. V tomto případě můžeme použít méně výkonnou funkci zástupných znaků poskytovanou programem Calc, protože tabulky, které používají zástupné znaky, lze exportovat do formátu Excel bez ztráty dat. Zástupný znak je speciální znak, který zastupuje jeden nebo více blíže neurčených znaků. Vyhledávání s využitím zástupných znaků je výkonné, často je však méně konkrétní. dostupné zástupné znaky jsou ? (otazník), * (hvězdička) a ~ (vlnovka). Použití těchto zástupných znaků je stejné jako u dialogového okna Najít a nahradit, popsaného v části 2, Zadávání, úpravy a formátování dat.
Následující funkce programu Calc povolují používání zástupných znaků nebo regulární výrazů ve vyhledávacích kritériích.
Databázové funkce (DAVERAGE, DCOUNT, DCOUNTA, DGET, DMAX, DMIN, DPRODUCT, DSTDEV, DSTDEVP, DSUM, DVAR, DVARP)
AVERAGEIF, AVERAGEIFS, COUNTIF, COUNTIFS, MAXIFS, MINIFS, SUMIF, SUMIFS
HLOOKUP, LOOKUP, VLOOKUP
MATCH
REGEX (neplatí pro zástupné znaky)
SEARCH
Možnosti konfigurace jsou dostupné v sekci Zástupné znaky ve vzorcích dialogového okna Nástroje > Možnosti > LibreOffice Calc > Výpočty (obrázek 28). Zde lze nastavit používání zástupných znaků a regulárních výrazů ve funkcích programu Calc. Jsou tři vzájemně se vylučující možnosti, které nepotřebují vysvětlení:
Povolit zástupné znaky ve vzorcích. Jde o výchozí nastavení po instalaci program Calc.
Povolit regulární výrazy ve vzorcích.
Vzorce bez zástupných znaků a regulárních výrazů.
Další související volba v oblasti Obecné výpočty stejného dialogového okna Vyhledávací kritéria = a <> musí platit pro celé buňky, určuje, zda se kritéria vyhledávání musí přesně shodovat s celou buňkou.
Ve výchozím nastavení se při hledání regulárních výrazů v rámci funkcí Calc nerozlišují velká a malá písmena, a to bez ohledu na nastavení zaškrtávacího políčka Rozlišovat velikost písmen. U některých funkcí však regulární výrazy mohou obsahovat volbu příznaku „?-i)“ pro přepnutí na shodu malých a velkých písmen. Funkce, které to podporují jsou: AVERAGEIF, AVERAGEIFS, COUNTIF, COUNTIFS, HLOOKUP, LOOKUP, MATCH, SEARCH, SUMIF, SUMIFS, and VLOOKUP.
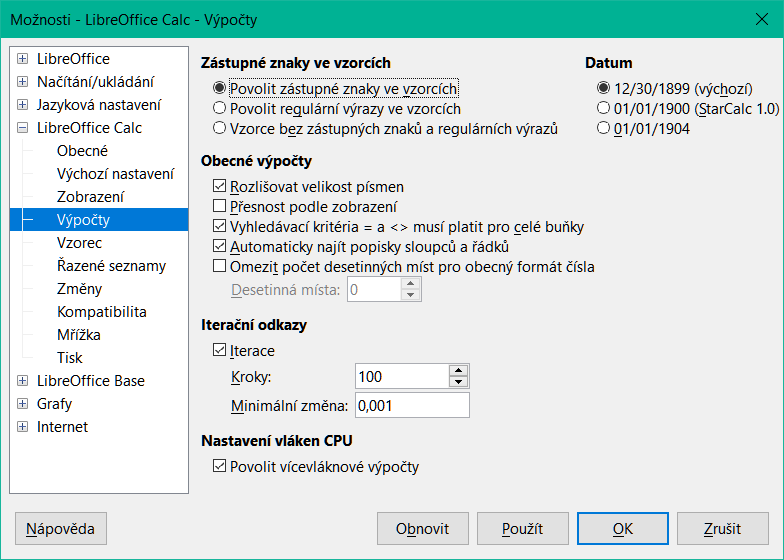
Obrázek 28: Nástroje > Možnosti > LibreOffice Calc > Dialogové okno Výpočet
Tip
Pokud jsou vybrány obě volby Vyhledávací kritéria = a <> musí platit pro celé buňky a Povolit zástupné znaky ve vzorcích, program Calc se při vyhledávání buněk v databázových funkcích chová přesně jako Microsoft Excel.
Pro ilustraci některých vlastností regulárních výrazů uvažujme jednoduchou tabulku na obrázku 29 a předpokládejme, že je vybráno Povolit regulární výrazy ve vzorcích.

Obrázek 29: Použití funkce COUNTIF
Se vzorcem =COUNTIF(A1:A6,”r.d”) zadaným do buňky A7 a odškrtnutou volbou Vyhledávací kritéria = a <> musí platit pro celé buňky, je v buňce A7 zobrazena hodnota 5, což je zobrazeno na obrázku 29. Vzorec sčítá buňky v oblasti A1:A6, které obsahují “Fred”, “red”, “ROD”, “bride” a “Ridge”.
Se vzorcem =COUNTIF(A1:A6,”(?-i)r.d”) zadaným do buňky A7 a odškrtnutou volbou Vyhledávací kritéria = a <> musí platit pro celé buňky, je v buňce A7 zobrazena hodnota 3. Vzorec sčítá buňky v oblasti A1:A6, které obsahují “Fred”, “red” a “bride”. Tento regulární výraz využívá možnost příznaku „(?-i)“ k provedení vyhledávání malých a velkých písmen.
Se vzorcem =COUNTIF(A1:A6,”r.d”) zadaným do buňky A7 a vybranou volbou Vyhledávací kritéria = a <> musí platit pro celé buňky, je v buňce A7 zobrazena hodnota 2. Vzorec sčítá buňky v oblasti A1:A6, které obsahují “red” a “ROD”.
Se vzorcem =COUNTIF(A1:A6,”(?-i)r.d”) zadaným do buňky A7 a vybranou volbou Vyhledávací kritéria = a <> musí platit pro celé buňky, je v buňce A7 zobrazena hodnota 1. Vzorec sčítá buňky v oblasti A1:A6, které obsahují “red”. Tento regulární výraz využívá možnost příznaku „(?-i)“ k provedení vyhledávání malých a velkých písmen.
Po zadání vzorce =COUNTIF(A1:A6,".*r.d.*") do buňky A7 a výběru Skritéria hledání = a <> musí platit pro celé buňky se v buňce A7 opět zobrazí hodnota 5. Srovnejte to s příkladem 3) ) nad – regulární výraz v tomto příkladu umožňuje 0 nebo více znaků před „r“ i za „d“.
Regulární výrazy nebudou fungovat v jednoduchém srovnání. Například: A1="r.d" vždy vrátí FALSE, pokud A1 obsahuje red, i když jsou povoleny regulární výrazy. Vrátí TRUE, pouze pokud A1 obsahuje r.d (r pak tečku, pak d). Pokud chceme testovat pomocí regulárních výrazů, zkusíme funkci COUNTIF: COUNTIF(A1;"r.d") vrátí 1 nebo 0, interpretované jako PRAVDA nebo NEPRAVDA ve vzorcích jako =IF(COUNTIF(A1;"r.d"), "hooray ";"boo").
Aktivace volby Povolit regulární výrazy ve vzorcích znamená, že všechny výše uvedené funkce budou vyžadovat, aby všechny speciální znaky regulárních výrazů (jako jsou závorky) použité v řetězcích uvnitř vzorců byly uvozeny zpětným lomítkem, přestože nejsou součástí regulárního výrazu. Tato zpětná lomítka bude nutné odstranit, pokud bude nastavení později deaktivováno.
Stejně jako u jiných tabulkových procesorů lze program Calc vylepšit uživatelsky definovanými funkcemi nebo doplňky. Nastavení uživatelsky definovaných funkcí lze provést buď pomocí maker, nebo napsáním samostatných doplňků nebo rozšíření.
Základy psaní a spouštění maker jsou popsány v kapitole 12 – Makra. Makra lze snadno propojit s nabídkami nebo panely nástrojů nebo je uložit do modulů šablon, aby byly funkce dostupné v jiných dokumentech. Makra programu Calc lze psát v jazycích Basic, BeanShell, JavaScript nebo Python.
Doplňky programu Calc jsou specializovaná rozšíření, která mohou rozšířit funkčnost LibreOffice o nové vestavěné funkce programu Calc. Bylo napsáno několik rozšíření pro program Calc; najdeme je na webu rozšíření na adrese https://extensions.libreoffice.org/. Další podrobnosti nalezneme v kapitole 14, Nastavení a přizpůsobení.