
Calc Guide 7.4
Kapitola 9
Analýza dat
Používání scénářů, vyhledávání řešení, řešitele, statistik atd.
Tento dokument je chráněn autorskými právy © 2023 týmem pro dokumentaci LibreOffice. Přispěvatelé jsou uvedeni níže. Dokument lze šířit nebo upravovat za podmínek licence GNU General Public License (https://www.gnu.org/licenses/gpl.html), verze 3 nebo novější, nebo the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0/), verze 4.0 nebo novější.
Všechny ochranné známky uvedené v této příručce patří jejich vlastníkům.
|
Skip Masonsmith |
Kees Kriek |
|
|
Barbara Duprey |
Jean Hollis Weber |
John A. Smith |
|
Kees Kriek |
Zachary Parliman |
Olivier Hallot |
|
Steve Fanning |
Leo Moons |
Felipe Viggiano |
Jakékoli připomínky nebo návrhy k tomuto dokumentu prosím směřujte do fóra dokumentačního týmu na adrese https://community.documentfoundation.org/c/documentation/loguides/ (registrace je nutná) nebo pošlete e-mail na adresu: loguides@community.documentfoundation.org.
Poznámka
Vše, co napíšete do fóra, včetně vaší e-mailové adresy a dalších osobních údajů, které jsou ve zprávě napsány, je veřejně archivováno a nemůže být smazáno. E-maily zaslané do fóra jsou moderovány.
Vydáno březen 2023. Založeno na LibreOffice 7.4 Community.
Jiné verze LibreOffice se mohou lišit vzhledem a funkčností.
Některé klávesové zkratky a položky nabídek jsou v systému macOS jiné než v systémech Windows a Linux. V následující tabulce jsou uvedeny nejdůležitější rozdíly, které se týkají informací uvedených v tomto dokumentu. Podrobnější seznam nalezneme v nápovědě k programu a v příloze A (Klávesové zkratky) této příručky.
|
Windows nebo Linux |
Ekvivalent pro macOS |
Akce |
|
Výběr v nabídce Nástroje > Možnosti |
LibreOffice > Předvolby |
Otevřou se možnosti nastavení. |
|
Klepnutí pravým tlačítkem |
Control + klepnutí a/nebo klepnutí pravým tlačítkem myši v závislosti na nastavení počítače |
Otevře se místní nabídka. |
|
Ctrl (Control) |
⌘ (Command) |
Používá se také s dalšími klávesami. |
|
F11 |
⌘ + T |
Otevře se postranní lišta Styly. |
Jakmile se seznámíme s funkcemi a vzorci, dalším krokem je naučit se používat automatizované procesy programu Calc k rychlému provádění užitečné analýzy našich dat.
Kromě vzorců a funkcí obsahuje Calc několik nástrojů pro zpracování našich dat. Tyto nástroje zahrnují funkce pro kopírování a opětovné použití dat, vytváření mezisoučtů, provádění analýzy typu what-if a provádění statistické analýzy. Najdeme je v hlavní nabídce v nabídkách Nástroje a Data. Mohou pomoci ušetřit čas a úsilí při zpracování velkých datových souborů nebo uspořit práci při budoucí kontrole.
Poznámka
Související nástroj, kontingenční tabulka, zde není uveden, protože je dostatečně složitý na to, aby si zasloužil vlastní kapitolu. Další informace nalezneme v kapitole 8 – Používání kontingenčních tabulek.
Nástroj Konsolidace umožňuje kombinovat a agregovat data rozložená na jednom nebo více listech. Tento nástroj je užitečný, pokud potřebujeme rychle shrnout velkou a rozptýlenou sadu dat pro kontrolu. Můžeme jej například použít ke sloučení více rozpočtů oddělení z různých listů do jediného rozpočtu pro celou společnost obsaženého v hlavním listu.
Chceme-li konsolidovat data:
Otevřeme dokument obsahující oblasti buněk, které mají být konsolidovány.
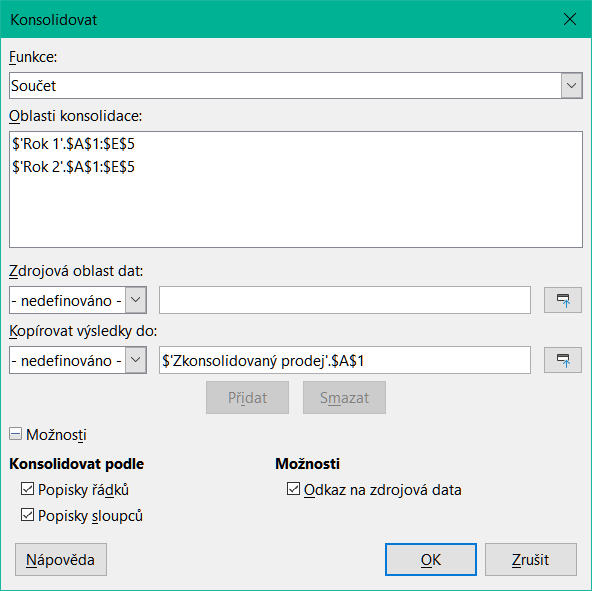
Z hlavní nabídky Data > Konsolidovat otevřeme dialogové okno Konsolidovat (obrázek 1).
Klikneme na pole Zdrojová oblast dat a vložíme odkaz na zdrojovou oblast dat, pojmenovaný rozsah nebo oblast vybereme myší. Při výběru buněk můžeme dočasně dialogové okno zmenšit pomocí tlačítka Zmenšit/Rozšířit. Nebo vybereme pojmenovanou oblast z rozevíracího seznamu vlevo od pole.
Klepneme na Přidat. Vybraná oblast se přidá do seznamu Oblasti konsolidace.
Pro přidání dalších zdrojových oblastí opakujeme kroky 3) a 4) .
Chceme-li odstranit položku v seznamu Oblasti konsolidace, vybereme ji a klepneme na Smazat. Výmaz se provede bez dalšího potvrzení.
Klepneme na pole Kopírovat výsledky do a zadáme odkaz na první buňku cílové oblasti nebo ji vybereme myší. V rozevíracím seznamu vlevo od pole můžeme také vybrat pojmenovaný rozsah.
V rozevíracím seznamu Funkce vybereme funkci pro agregaci dat. Výchozí je Součet. Mezi další dostupné funkce patří Počet, Průměr, Max, Min, Produkt, Počet (pouze čísla), SměrOdch (výběr), SměrOdchP (základní soubor), Rozptyl (výběr) a RozptylP (základní soubor).
Klepnutím na OK spustíme konsolidaci. Calc provede funkci z kroku 8) na zdrojových oblastech dat a vyplní cílový rozsah výsledky.
Tip
Pokud konsolidujeme opakovaně stejné oblasti buněk, lze je změnit na opakovaně použitelné pojmenované oblasti, aby byl proces snazší. Další informace o pojmenovaných oblastech nalezneme v kapitole 13, Calc jako databáze.
Obrázek 1: Dialogové okno nástroje Konsolidovat
V dialogovém okně Konsolidovat rozbalíme část Možnosti a získáme přístup k volbám zobrazeným na obrázku 2.
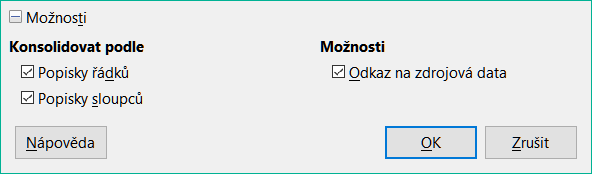
Obrázek 2: Dialogové okno Konsolidovat – část Možnosti
Konsolidovat podle
Popisky řádků – Konsoliduje řádky odpovídající popisku. Pokud tato volba není zaškrtnutá, nástroj místo toho sloučí řádky podle pozice.
Popisky sloupců – Funguje stejně jako Popisky řádků, ale místo toho se sloupci.
Možnosti
Poznámka
Pokud použijeme možnost Odkaz na zdrojová data, každý zdrojový odkaz je vložen do cílové oblasti, pak uspořádán a skryt před zobrazením. Ve výchozím nastavení jsou zobrazeny pouze konečné výsledky konsolidace.
Obrázky 3, 4 a 5 ukazují jednoduchý příklad konsolidace pomocí tabulky s listy Rok 1, Rok 2 a Zkonsolidovaný prodej. Obrázek 3 ukazuje obsah sešitu Rok 1 s údaji o prodeji podle regionů pro každou ze čtyř barev produktu.
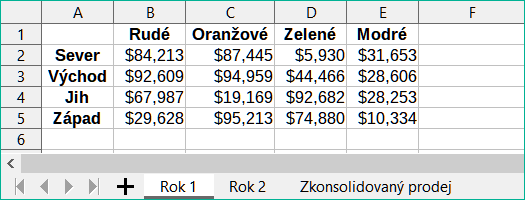
Obrázek 3: Prodeje Rok 1 podle regionu
Obrázek 4 ukazuje list Rok 2 s údaji o prodeji podle regionu pro každou ze čtyř barev produktu. Všimněme si odlišného pořadí štítků řádků a sloupců mezi dvěma obrázky.
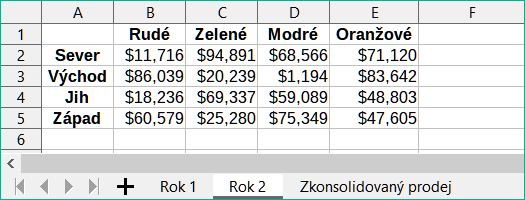
Obrázek 4: Prodeje Roku 2 dle regionu
Obrázek 5 zobrazuje konsolidovaná data o prodeji vytvořená pomocí nastavení dialogového okna Konsolidovat zobrazeného na obrázku 2. Všimněme si, že vzhledem k tomu, že byla vybrána možnost Odkaz na zdrojová data, klepnutím na znaménka plus (+) nalevo od dat se zobrazí odkazy vzorců zpět na zdrojové oblasti.
Zdrojové a cílové oblasti se ukládají jako součást dokumentu. Pokud později otevřeme dokument s konsolidovanými oblastmi, budou stále k dispozici v seznamu Oblasti konsolidace v dialogovém okně Konsolidovat.
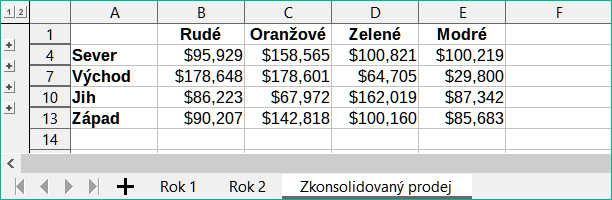
Obrázek 5: Konsolidovaný prodej podle regionů
Calc nabízí dvě metody vytváření mezisoučtů: funkci SUBTOTAL a nástroj Mezisoučty.
Funkce SUBTOTAL je uvedena v matematické kategorii průvodce funkcí a na kartě funkcí na postranní liště, které jsou popsány v kapitole 7 – Použití vzorců a funkcí. SUBTOTAL je relativně omezená metoda pro generování mezisoučtu a funguje nejlépe, pokud je použita pouze s několika kategoriemi.
Pro ilustraci, jak používat funkci SUBTOTAL, používáme pracovní list s údaji o prodeji zobrazený na obrázku 6. Na prodejní data je již použita funkce Automatický filtr, což můžeme poznat podle tlačítek se šipkami dolů v záhlaví každého sloupce. Automatické filtry jsou popsány v kapitole 2 – Zadávání, úpravy a formátování dat.
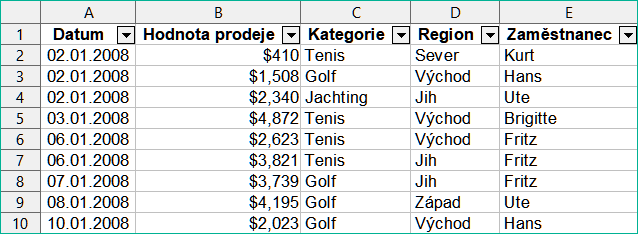
Obrázek 6: Údaje o prodeji s použitým automatickým filtrem (zobrazí se pouze několik prvních řádků)
Chceme-li vytvořit součet mezisoučtu pro pole Hodnota prodeje použijeme Průvodce funkcí:
Vybereme buňku, která obsahuje mezisoučet. Obvykle je tato buňka ve spodní části sloupce, který je mezisoučtem, což je například náš sloupec Hodnota prodeje.
Dialogové okno Průvodce funkcemi otevřeme pomocí jedné z následujících metod (obrázek 7):
V hlavní nabídce vybereme Vložit > Funkce
Klepneme na ikonu Průvodce funkcí na Liště vzorců
Stiskneme Ctrl + F2
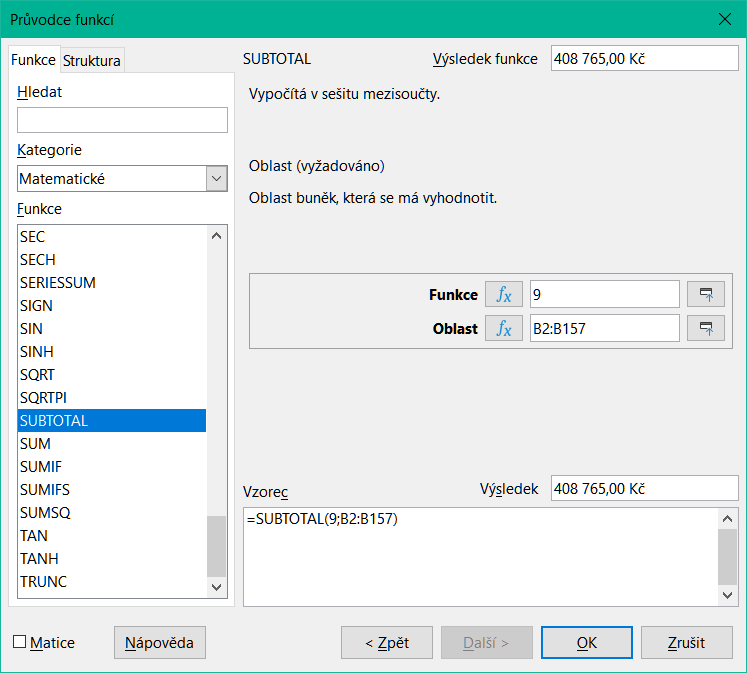
Obrázek 7: Dialogové okno Průvodce funkcí
V seznamu Funkce dialogového okna Průvodce Funkce vybereme položku SUBTOTAL a klikneme na tlačítko Next.
Enter the numeric code of a function into the Function field on the right side of the dialog. Tento kód musí být hodnota v rozsahu 1 až 11 nebo 101 až 111 s významem každé hodnoty uvedené v tabulce 1.
Poznámka
Hodnoty 1 až 11 zahrnují skryté hodnoty ve vypočítaném mezisoučtu, zatímco hodnoty 101 až 111 je nezahrnují. Skrytí a zobrazení dat je popsáno v kapitole 2 – Zadávání, úpravy a formátování dat. Filtrované buňky jsou funkcí SUBTOTAL vždy vyloučeny.
Tabulka 1: Čísla funkce SUBTOTAL
|
Číslo funkce |
Číslo funkce |
Funkce |
|
1 |
101 |
AVERAGE |
|
2 |
102 |
COUNT |
|
3 |
103 |
COUNTA |
|
4 |
104 |
MAX |
|
5 |
105 |
MIN |
|
6 |
106 |
PRODUCT |
|
7 |
107 |
STDEV |
|
8 |
108 |
STDEVP |
|
9 |
109 |
SUM |
|
10 |
110 |
VAR |
|
11 |
111 |
VARP |
Klepneme na pole Rozsah a zadáme odkaz na oblast Hodnota prodeje nebo vybereme buňky myší (obrázek 7). Při výběru buněk můžeme dočasně dialogové okno zmenšit pomocí tlačítka Zmenšit/Rozvinout.
Klepnutím na OK zavřeme dialogové okno Průvodce funkcí. Buňka vybraná v kroku 1) nyní obsahuje celkovou hodnotu prodeje.
Klepneme na tlačítko automatického filtru v horní části sloupce Zaměstnanec a odstraníme všechna zaškrtnutí z oblasti Standardní filtr kromě těch vedle Brigitte a (prázdný). Buňka vybraná v kroku 1) by nyní měla odrážet součet všech Brigitiných tržeb (obrázek 8).
Poznámka
Pokud oblast buněk použitá pro výpočet mezisoučtu obsahuje další mezisoučty, tyto mezisoučty nebudou v konečném součtu započítány. Podobně, pokud tuto funkci použijeme s automatickými filtry, zobrazí se pouze data splňující aktuální výběr filtrů. Všechna filtrovaná data jsou ignorována.
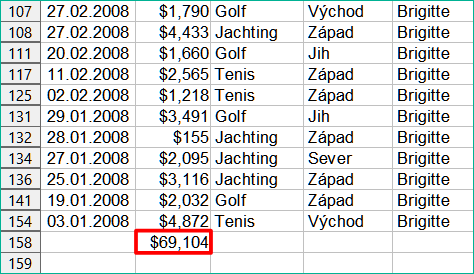
Obrázek 8: SUBTOTAL výsledek prodeje Brigitte
Calc nabízí nástroj Mezisoučty jako komplexnější alternativu k funkci SUBTOTAL. Na rozdíl od SUBTOTAL, který pracuje pouze na jednom poli, může nástroj Subtotals vytvářet mezisoučty až pro tři pole uspořádaná v označených sloupcích. Rovněž seskupuje mezisoučty podle kategorií a automaticky je třídí, čímž se eliminuje nutnost používat automatické filtry a filtrovat kategorie ručně.
Vložení hodnot mezisoučtu do sešitu:
Vybereme oblast buněk pro mezisoučty, které chceme vypočítat, a nezapomeneme zahrnout popisky záhlaví sloupců. Můžeme také kliknout na jednu buňku v rámci dat, aby mohl Calc automaticky identifikovat rozsah.
Výběrem Data > Mezisoučty z hlavní nabídky otevřeme dialogové okno Mezisoučty (obrázek 9).
V rozevíracím seznamu Seskupit podle na kartě 1. skupina vybereme název sloupce. Položky v rozsahu buněk z kroku 1) budou seskupeny a seřazeny podle odpovídajících hodnot v tomto sloupci.
V poli Spočítat mezisoučty pro na kartě 1. skupina vybereme sloupec obsahující hodnoty, ze kterých se má spočítat mezisoučet. Pokud později změníme hodnoty v tomto sloupci, Calc automaticky přepočítá mezisoučty.
V poli Použít funkci na kartě 1. skupina vybereme funkci pro výpočet mezisoučtů ve sloupci vybraném v kroku 4) .
Opakováním kroků 4) a 5) vytvoříme mezisoučty pro další sloupce na kartě 1. skupina.
Další dva mezisoučty můžeme vytvořit pomocí karet 2. skupina a 3. skupina, zopakujeme-li kroky 3) až 6) . Pokud nechceme přidávat další skupiny, ponecháme seznam Seskupit podle pro každou stránku nastavený na „– žádné –“.
Klepneme na OK. Calc přidá do oblasti buněk mezisoučet a celkový součet řádků.
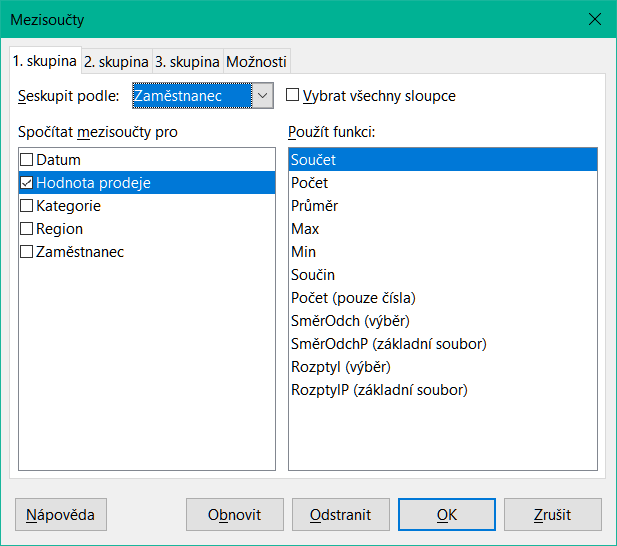
Obrázek 9: Dialogové okno Mezisoučty
Pro příklad našich prodejních údajů je částečný pohled na výsledky znázorněn na obrázku 10. Nastavení skupiny jsou uvedena v tabulce 2.
Tabulka 2: Nastavení skupiny použité v dialogovém okně Mezisoučty, například údaje o prodeji
|
Tabulátor |
Seskupit podle |
Spočítat mezisoučty pro |
Použít funkci |
|
1. skupina |
Zaměstnanec |
Hodnota prodeje |
Součet |
|
2. skupina |
Kategorie |
Hodnota prodeje |
Součet |
|
3. skupina |
- žádné - |
- |
- |
Při použití nástroje Mezisoučty vloží Calc souhrn nalevo od sloupce číslo řádku. Tento souhrn představuje hierarchickou strukturu mezisoučtů a může být použit ke skrytí nebo zobrazení dat na různých úrovních v hierarchii pomocí indikátorů číslovaných sloupců v horní části souhrnu nebo skupinových indikátorů označených značkami plus (+) a mínus (-).
Tato funkce je užitečná, pokud máme mnoho mezisoučtů, protože můžeme jednoduše skrýt detaily, jako jsou jednotlivé položky, a vytvořit tak souhrn údajů. Další informace o použití souhrnů nalezneme v kapitole 2 – Zadávání, úpravy a formátování dat.
Chceme-li souhrny vypnout, vybereme Data > Seskupení a souhrn > Odstranit souhrny z hlavní nabídky. Chceme-li je obnovit, vybereme Data > Seskupení a souhrn > Automatické souhrny.
Obrázek 10 ukazuje přehled našeho příkladu prodejních údajů.
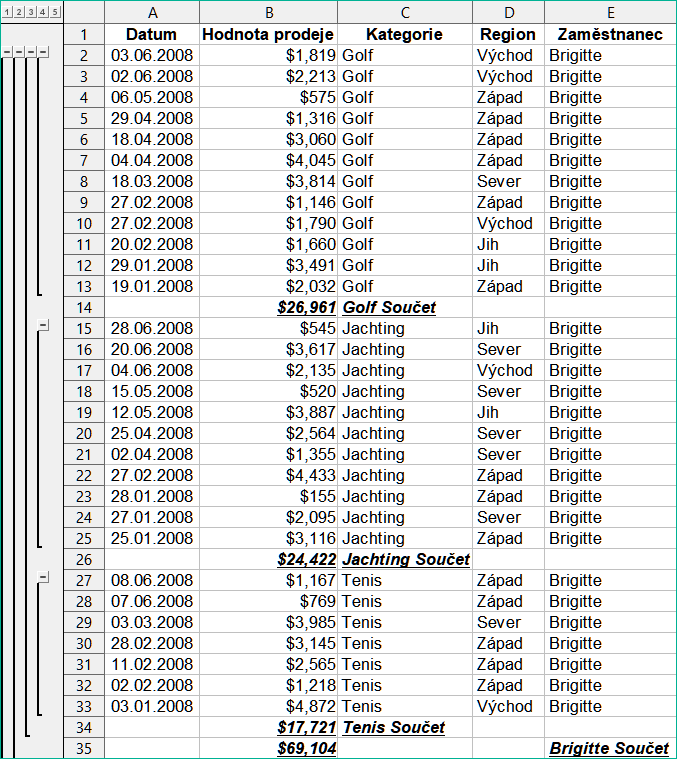
Obrázek 10: Částečný pohled se souhrnem na údaje o prodeji s mezisoučty
Sloupec 1 představuje nejvyšší úroveň seskupení, celkový součet všech zaměstnanců. Sloupce 2 až 5 zobrazují sestupné úrovně skupin takto:
Sloupec 2 představuje celkový součet ve všech kategoriích.
Sloupec 3 představuje součet pro každého zaměstnance.
Sloupec 4 představuje součet pro každou kategorii jednotlivého zaměstnance.
Sloupec 5 zobrazuje jednotlivé položky.
Pro přístup k následujícím nastavením klepneme v dialogovém okně Mezisoučty na kartu Možnosti:
Seskupení
Zalomení stránky mezi skupinami – vloží konce stránek mezi každou skupinu mezisoučtů, aby se každá skupina při tisku dat zobrazila na samostatné stránce.
Rozlišovat velikost písmen – brání nástroji v seskupování položek podle nadpisů, které se liší velikostí písmen. V našem příkladu údajů o prodeji se položky se sloupci „Brigitte“ a „brigitte“ ve sloupci Zaměstnanec neshodují, pokud je vybrána tato možnost.
Předřadit oblast podle skupin – před výpočtem mezisoučtů třídí položky podle skupiny. Deaktivace této možnosti zabrání nástroji seskupovat shodné položky dohromady. V důsledku toho budou vytvořeny odlišné mezisoučty pro odpovídající položky, pokud se neobjeví v po sobě jdoucích řádcích. Například dva záznamy v kategorii „Golf“ se nezapočítávají do stejného mezisoučtu skupiny, pokud mezi nimi existuje položka „Tenis“.
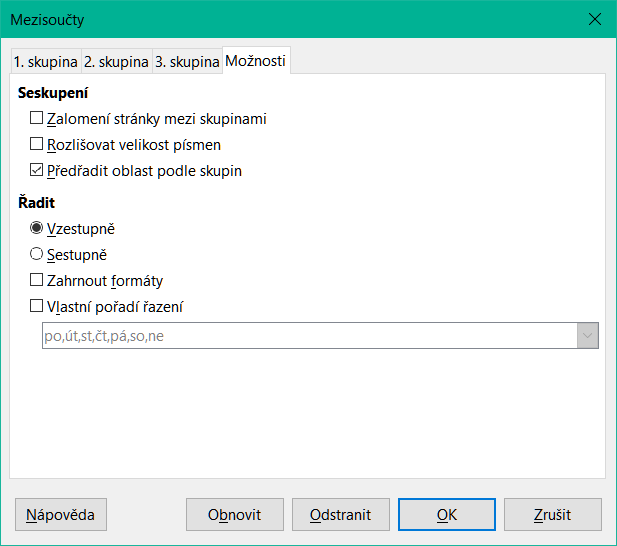
Obrázek 11: Stránka Možnosti v dialogovém okně Mezisoučty
Řadit
Vzestupně nebo Sestupně – řadí položky podle hodnoty od nejnižší po nejvyšší nebo od nejvyšší po nejnižší. Tato pravidla třídění můžeme upravit pomocí Data > Seřadit v hlavní nabídce. Další podrobnosti nalezneme v kapitole 2 – Zadávání, úpravy a formátování dat.
Zahrnout formáty – převádí formátování, například formát měny, z dat do odpovídajících mezisoučtů.
Vlastní řazení – třídí naše data podle jednoho z předdefinovaných vlastních druhů Nástroje > Možnosti > LibreOffice Calc > Seřadit seznamy v hlavní nabídce. Další informace o vlastních řazených seznamech najdeme v kapitole 2 – Zadávání, úpravy a formátování dat.
V dialogovém okně Mezisoučty použijeme tlačítko Vrátit pro zrušení všech změn provedených na aktuální záložce. Pro odstranění všech mezisoučtů, které již byly vytvořeny pomocí nástroje Mezisoučty použijeme tlačítko Odstranit. Tyto funkce používejme opatrně, protože se nezobrazí žádné potvrzovací dialogy.
Scénáře jsou uložené pojmenované oblasti buněk, které můžeme použít k zodpovězení otázek „what-if“ o našich datech. Pro stejnou sadu výpočtů můžeme vytvořit více scénářů a rychle mezi nimi přepínat a zobrazit výsledky každého z nich. Tato funkce je užitečná, pokud potřebujeme vyzkoušet účinky různých podmínek na výpočty, ale nechceme se zabývat opakovaným ručním zadáváním dat. Pokud například chceme vyzkoušet různé úrokové sazby pro investici, můžeme pro každou sazbu vytvořit scénáře a poté mezi nimi přepínat, abychom zjistili, které sazby pro nás nejlépe fungují.
Postup vytvoření nového scénáře:
Vybereme buňky, které obsahují hodnoty, které se mezi scénáři změní. Chceme-li vybrat více oblastí, podržíme při klepání klávesu Ctrl. Musíme vybrat alespoň dvě buňky.
V hlavní nabídce zvolíme Nástroje > Scénáře a otevřeme dialogové okno Vytvořit scénář (obrázek 12).
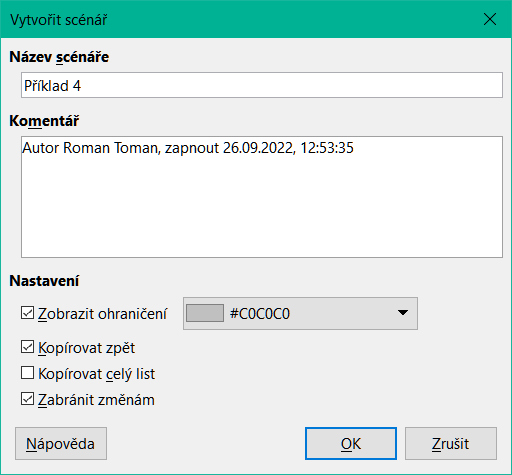
Obrázek 12: Dialogové okno Vytvořit scénář
Zadáme název nového scénáře do pole Název scénáře.
Tip
Pro každý scénář, který vytvoříme použijeme jedinečný název, který jej jasně identifikuje a rozliší. Tato praxe nám ušetří čas a problémy, pokud musíme pracovat s velkým počtem scénářů. Nedoporučujeme použití výchozí jména navrženého aplikací Calc.
Volitelně přidáme informace do pole Komentář. Příklad na obrázku 12 zobrazuje výchozí komentář.
Klepnutím na OK okno zavřeme. Nový scénář se po vytvoření automaticky aktivuje.
Dalších scénáře vytvoříme opakováním kroků 1) až 5) . Vybereme stejný rozsah buněk, který jsme použili pro první scénář, a vytvoříme více scénářů pro stejné výpočty.
Tip
Chceme-li sledovat, jaké výpočty jsou závislé na našich scénářích, použijeme v hlavní nabídce volbu Nástroje > Detektiv > Sledovat následníky po zvýraznění buněk scénáře. Šipky budou ukazovat z buněk scénáře na závislé buňky vzorce. Další informace o nástroji Detektiv nalezneme v kapitole 7 – Použití vzorců a funkcí.
Část Nastavení dialogového okna Vytvořit scénář obsahuje následující možnosti:
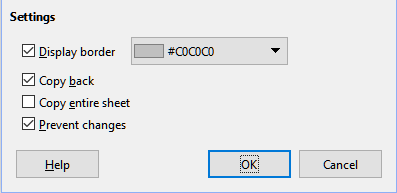
Obrázek 13: Dialogové okno Vytvořit scénář – část Nastavení
Zobrazit ohraničení
Obrázek 14: Rozsah buněk scénáře s ohraničením
Kopírovat zpět
Upozornění
Měli bychom být opatrní, abychom nepřepsali starý scénář při vytváření nového scénáře z buněk scénáře s povolenou volbou Kopírovat zpět. Chceme-li se této situaci vyhnout, vytvoříme nejprve nový scénář s povolenou volbou Kopírovat zpět a poté, po jeho aktivaci, změníme hodnoty.
Kopírovat celý list
Zabránit změnám
Scénáře mají dva aspekty, které lze nezávisle změnit:
Vlastnosti scénáře (tj. jeho nastavení)
Hodnoty buněk scénáře
Rozsah, v jakém mohou být tyto aspekty změněny, závisí na vlastnostech aktivního scénáře a ochraně aktuálního listu a buněk. Více podrobností o ochraně listů a buněk nalezneme v kapitole 2 – Zadávání, úpravy a formátování dat.
Tabulka 3 shrnuje, jak ochrana listů a možnost Zabránit změnám ovlivní schopnost změnit vlastnosti scénáře.
Tabulka 3: Změna vlastností scénáře
|
Ochrana listu |
Zabránit změnám |
Změny vlastností |
|
Povoleno |
Povoleno |
Žádné vlastnosti scénáře nelze změnit. |
|
Povoleno |
Zakázáno |
Zobrazit ohraničení a Kopírovat zpět lze změnit. Zabránit změnám a Kopírovat celý list nelze změnit. |
|
Zakázáno |
Jakékoli nastavení |
Všechny parametry scénáře kromě Kopírovat celý list lze změnit. V tomto případě volba Zabránit změnám nemá žádný účinek. |
Tabulka 4 shrnuje interakci různých nastavení při provádění změn hodnot buněk scénáře.
Tabulka 4: Změna hodnot buněk scénáře
|
Ochrana listu |
Ochrana buněk scénáře |
Zabránit změnám |
Kopírovat zpět |
Změna povolena |
|
Povoleno |
Zakázáno |
Povoleno |
Povoleno |
Hodnoty buněk scénáře nelze změnit. |
|
Povoleno |
Zakázáno |
Zakázáno |
Povoleno |
Hodnoty buněk scénáře lze změnit a scénář je aktualizován. |
|
Povoleno |
Zakázáno |
Jakékoli nastavení |
Zakázáno |
Hodnoty buněk scénáře lze změnit, ale scénář není aktualizován kvůli nastavení Kopírovat zpět. |
|
Povoleno |
Povoleno |
Jakékoli nastavení |
Jakékoli nastavení |
Hodnoty buněk scénáře nelze změnit. |
|
Zakázáno |
Jakékoli nastavení |
Jakékoli nastavení |
Jakékoli nastavení |
Hodnoty buněk scénáře lze změnit a scénář je aktualizován nebo ne, v závislosti na nastavení Kopírovat zpět. |
Po přidání scénářů do tabulky můžeme zobrazit konkrétní scénář pomocí Navigátoru. Otevřeme jej výběrem Zobrazit > Navigátor v hlavní nabídce a poté klepneme na ikonu Scénáře v Navigátoru a ze seznamu scénář vybereme (obrázek 15). Všechny definované scénáře jsou uvedeny spolu s komentáři, které byly zadány při vytváření každého scénáře. Můžeme také použít odpovídající možnosti na kartě Navigátor na postranní liště. Další informace o Navigátoru nalezneme v kapitole 1 – Úvod.
Obrázek 15: Scénáře v Navigátoru
Chceme-li použít scénář na aktuální list, poklepeme na název scénáře v Navigátoru.
Chceme-li scénář odstranit, klikneme na jeho název v Navigátoru pravým tlačítkem myši a zvolíme Odstranit nebo po jeho výběru stiskneme Odstranit. Zobrazí se potvrzovací dialog.
Chceme-li upravit scénář, klepneme pravým tlačítkem na název v Navigátoru a vybereme Vlastnosti. Calc zobrazí dialogové okno Upravit scénář, které je podobné dialogovému oknu Vytvořit scénář (obrázek 12).
Stejně jako scénáře i nástroj pro více operací provádí what-if“ analýzu našich výpočtů. Na rozdíl od scénářů, které představují jednotlivé sady hodnot pro více proměnných vzorce, tento nástroj používá celou škálu hodnot pouze pro jednu nebo dvě proměnné. Poté použije jeden nebo více vzorců k vytvoření odpovídající řady řešení. Protože každé řešení odpovídá jedné nebo dvěma hodnotám proměnných, lze rozsahy proměnných i řešení snadno uspořádat do tabulkového formátu. Nástroj Vícenásobné operace je proto vhodný pro generování dat, která lze snadno číst a sdílet nebo vizualizovat pomocí grafů.
Tip
Příprava a dobrá organizace může použití tohoto nástroje relativně ulehčit. Doporučujeme například uchovávat vaše data pohromadě na jednom listu a pomocí nadpisů identifikovat vzorce, proměnné a oblasti tabulek.
Nejjednodušší způsob, jak se naučit používat nástroj Vícenásobné operace, je s jedním vzorcem a jednou proměnnou. Informace o používání nástroje s více vzorci nebo se dvěma proměnnými nalezneme v části „Výpočet s několika vzorci současně“ (strana 1) a „Vícenásobné operace se dvěma proměnnými“ (strana 1).
Chceme-li použít nástroj Vícenásobné operace s jedním vzorcem a jednou proměnnou:
V buňkách listu zadáme vzorec a alespoň jednu proměnnou, kterou používá.
Ve stejném listu zadáme hodnoty do oblasti buněk, která zabírá jeden sloupec nebo řádek. Tyto hodnoty budou použity pro jednu z proměnných vzorce, který jsme definovali v kroku 1) .
Myší vybereme oblast obsahující jak rozsah proměnných, který jste definovali v kroku 2) , tak sousední prázdné buňky, které následují za ním. V závislosti na tom, jak je naše oblast proměnných uspořádána, budou tyto prázdné buňky buď ve sloupci napravo (pokud je oblast ve sloupci), nebo v řádku bezprostředně pod (pokud je v řadě).
Výběrem Data > Vícenásobné operace z hlavní nabídky otevřeme dialogové okno Vícenásobné operace (obrázek 16).
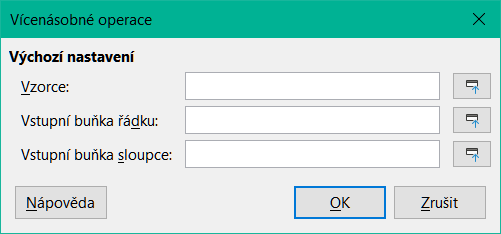
Obrázek 16: Dialogové okno Vícenásobné operace
Klikneme na pole Vzorce a zadáme odkaz na buňku se vzorcem definovaným v kroku 1) nebo vybereme buňku myší. Při výběru buňky můžeme dočasně dialogové okno zmenšit pomocí tlačítka Zmenšit/Rozvinout.
Pokud je rozsah z kroku 2) uspořádán ve sloupci, klikneme na pole Vstupní buňka sloupce a zadáme odkaz na buňku proměnné, kterou chceme použít, nebo buňku vybereme myší. Pokud je oblast v řádku, použijeme místo toho Vstupní buňka řádku.
Kliknutím na OK nástroj spustíme. Nástroj Vícenásobné operace zapíše své výsledky do prázdných buněk, které jsme vybrali v kroku 3) . Každá výsledná hodnota odpovídá proměnné, která s ní sousedí, a společně tvoří položky tabulky výsledků.
Použití nástroje Vícenásobné operace je nejlépe vysvětleno na příkladu. Předpokládejme, že vyrábíme hračky, které prodáváme za 10 $ (buňka B1 listu). Každá hračka stojí 2$ na výrobu (B2) a máme pevné roční náklady 10 000 $ (B3). Jaký je minimální počet hraček, který musíme prodat, abychom pokryli náklady? Předpokládejme, že náš počáteční odhad prodaného množství je 2 000 kusů (B4).
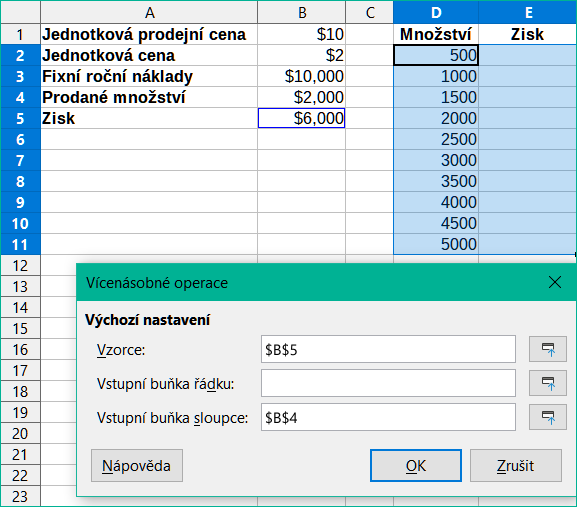
Obrázek 17: Vstupy do nástroje Vícenásobné operace pro jeden vzorec, jednu proměnnou
Odpověď na tuto otázku:
Do B5 zadáme následující vzorec: =B4*(B1-B2)-B3. Tento vzorec představuje rovnici Zisk = množství * (prodejní cena – přímé náklady) – fixní náklady. S touto rovnicí přináší naše počáteční množství zisk 6 000 $, což je vyšší než bod, kdy jsme ve ztrátě.
Do buněk D2:D11 zadáme množství od 500 do 5000 v krocích po 500.
Výběrem oblasti D2:E11 definujeme tabulku výsledků. Tato oblast zahrnuje hodnoty alternativního množství (sloupec D) a prázdné buňky výsledků (sloupec E).
Výběrem Data > Vícenásobné operace z hlavní nabídky otevřeme dialogové okno Vícenásobné operace.
Do pole Vzorce vybereme buňku B5.
Do pole Vstupní buňka sloupce vybereme buňku B4 a nastavíme množství jako proměnnou pro naše výpočty. Obrázek 17 zobrazuje list a dialogové okno Vícenásobné operace v tomto okamžiku.
Klepneme na OK. Zisky pro různá množství jsou nyní uvedena ve sloupci E (obrázek 18). Vidíme, že bod ztráty je mezi 1000 a 1500 prodaných hraček, a to 1250. Obrázek 18 zobrazuje XY (bodový) graf znázorňující zisk jako funkci množství.
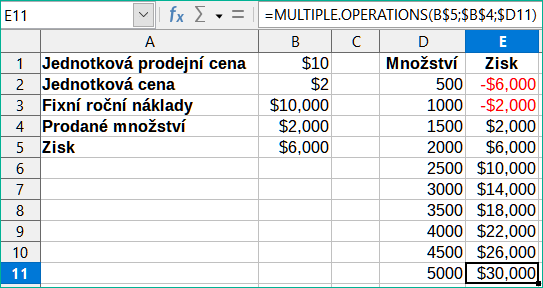
Obrázek 18: Výsledky nástroje Vícenásobné operace pro jeden vzorec a jednu proměnnou
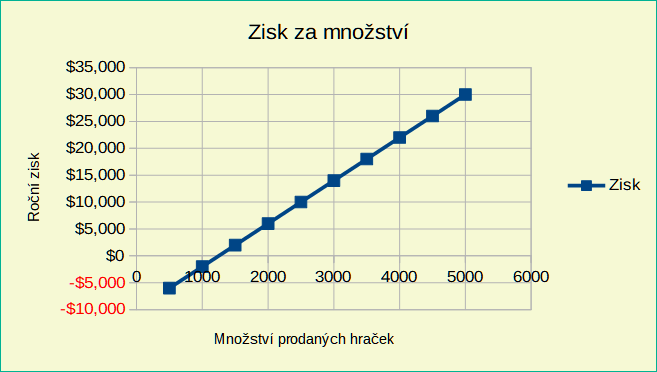
Obrázek 19: XY (bodový) graf rozptylu zisku na množství prodaných hraček (příklad vizualizace)
Použití nástroje Vícenásobné operace s více vzorci následuje téměř stejný proces jako u jednoho vzorce, ale se dvěma důležitými rozdíly:
Pro každý přidaný vzorec musíme také přidat do tabulky výsledků odpovídající sloupec nebo řádek, který bude obsahovat výstup tohoto vzorce.
Způsob, jakým zpočátku uspořádáme vzorce, určuje, jak budou jejich výsledky zobrazeny v tabulce výsledků. Například pokud uspořádáte vzorce A, B a C v jednom řádku v tomto pořadí, pak Calc vygeneruje výsledky A v prvním sloupci tabulky výsledků, výsledky B ve druhém sloupci a výsledky C ve třetí.
Poznámka
Nástroj Vícenásobné operace přijímá pouze vzorce uspořádané do jednoho řádku nebo sloupce v závislosti na tom, jak je orientována naše tabulka výsledků. Pokud je tabulka orientována na sloupce – tak, jak je v našem příkladu údajů o prodeji – pak musí být naše vzorce uspořádány do řádku. Pokud je tabulka orientována na řádky, musí být vzorce ve sloupci.
Upozornění
Dejme pozor, abychom mezi vzorce nepřidali prázdné buňky, protože vytvoří mezery v tabulce výsledků a mohou způsobit, že se některé výsledky nezobrazí, pokud pro tabulku nevybereme dostatečné množství řádků nebo sloupců.
Na příkladu našich údajů o prodeji předpokládejme, že kromě celkového ročního zisku chceme vypočítat roční zisk na prodanou položku. Pro výpočet výsledků:
V listu z předchozího příkladu vymažeme výsledky ve sloupci E.
Do C5 zadáme následující vzorec: =B5/B4. Nyní počítáme roční zisk za prodanou položku.
Pro tabulku výsledků vybereme rozsah D2:F11. Sloupec F bude obsahovat výsledky ročního zisku na položku dle vzorce v C5.
Výběrem Data > Vícenásobné operace z hlavní nabídky otevřeme dialogové okno Vícenásobné operace.
Do pole Vzorce vybereme oblast B5:C5.
Do pole Vstupní buňka sloupce vybereme buňku B4. Obrázek 20 zobrazuje list a dialogové okno v tomto okamžiku.
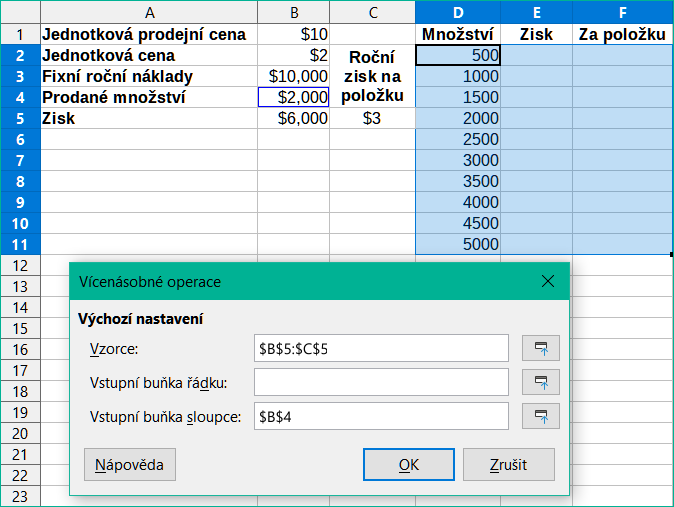
Obrázek 20: Vstupy pro nástroj Vícenásobné operace pro jednu proměnnou a dva vzorce
Klepneme na OK. Nyní jsou zisky uvedeny ve sloupci E a roční zisk na položku ve sloupci F.
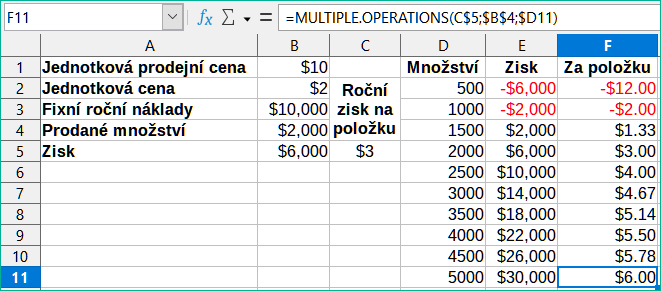
Obrázek 21: Výsledky nástroje Vícenásobné operace pro jednu proměnnou a dva vzorce
Použijeme-li nástroj více operací se dvěma proměnnými, vytvoří se dvourozměrná tabulka výsledků. Každá proměnná definuje jednu z dimenzí tabulky tak, že alternativní hodnoty pro obě proměnné slouží jako řádky tabulky a záhlaví sloupců. Každá buňka v tabulce odpovídá odlišné dvojici hodnot nadpisu řádku a sloupce. Z těchto hodnot se pro obě proměnné zase vytvoří výsledky v každé buňce.
Protože používáme dvě proměnné, musíme použít pro jejich definování obě pole dialogového okna Vstupní buňka sloupce a Řádková vstupní buňka. Pořadí je důležité; pole Vstupní buňka sloupce odpovídá hodnotám nadpisu řádku, zatímco pole Řádková vstupní buňka odpovídá hodnotám záhlaví sloupce.
Tip
Dobré vodítko pro zapamatování je, že záhlaví sloupců jsou v řadě v horní části tabulky a odpovídají tak poli Vstupní buňka řádku. Podobně jsou názvy řádků ve sloupci, takže odpovídají poli Vstupní buňka sloupce.
Poznámka
Pokud použijeme dvě proměnné, nebude nástroj Vícenásobné operace fungovat s více vzorci. To nám umožní zadat další vzorce, ale nevygeneruje očekávané výsledky pro žádný vzorec mimo prvního.
V našem příkladu prodeje předpokládejme, že kromě měnícího se množství prodaných hraček také chceme měnit jednotkovou prodejní cenu. Pro výpočet výsledků:
Rozbalte tabulku prodejních dat zadáním 8$, 10$, 15$ a 20$ v oblasti E1:H1.
V tabulce výsledků vybereme oblast D1:H11.
Výběrem Data > Vícenásobné operace z hlavní nabídky otevřeme dialogové okno Vícenásobné operace.
Do pole Vzorce vybereme buňku B5.
Do pole Vstupní buňka řádku vybereme buňku B1. Nadpisy sloupců – 8$, 10$, 15$ a 20$ – jsou nyní propojeny s proměnnou jednotkové prodejní ceny definované v buňce B1.
Do pole Vstupní buňka sloupce vybereme buňku B4. Nadpisy řádků – 500, 1000, …, 5000 – jsou nyní spojeny s proměnnou prodaného množství definovanou v buňce B4. Obrázek 22 zobrazuje list a dialogové okno v tomto okamžiku.
Klepneme na OK. Zisky z různých prodejních cen a množství jsou nyní uvedeny v oblasti E2:H11 (obrázek 1).
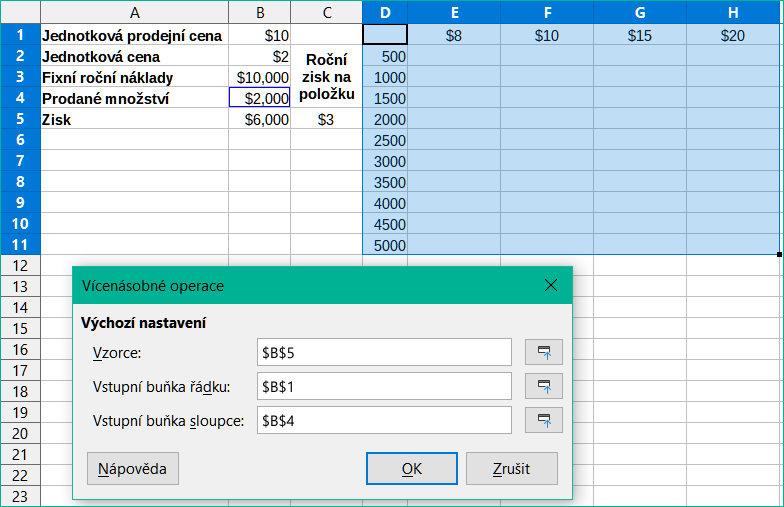
Obrázek 22: Vstupy pro nástroj Vícenásobné operace pro dvě proměnné
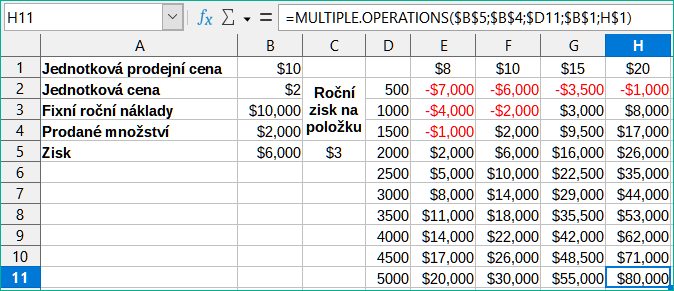
Obrázek 23: Výsledky nástroje Vícenásobné operace pro dvě proměnné
Kromě scénářů a nástroje Vícenásobné operace má Calc také třetí analytický nástroj: Hledat řešení. Obvykle použijeme vzorec pro výpočet výsledku z existujících hodnot. Naproti tomu s nástrojem Hledat řešení pracujeme zpětně od výsledku, abychom zjistili, jaké hodnoty funkci vytvářejí. Tato funkce je užitečná, pokud již známe požadovaný výsledek, ale potřebujeme odpovědět na otázky, jak toho dosáhnout, nebo jak by se to mohlo změnit, pokud bychom změnili podmínky.
Poznámka
V jednom hledání řešení lze najednou změnit pouze jeden argument. Pokud potřebujeme vyzkoušet více argumentů, musíme u každého z nich spustit samostatné hledání řešení.
Abychom ilustrovali, jak používat nástroj Hledat řešení, předpokládejme, že chceme vypočítat roční úrokový výnos pro účet. Pro výpočet ročního úroku (I), musíme vytvořit tabulku s hodnotami pro kapitál (C), délku úrokového období v letech (n) a úrokovou sazbu (i). Vzorec je I = C*n*i.
Předpokládejme, že úroková sazba i = 7,5 % (buňka B3 listu) a délka periody n = 1 (B2) zůstávají konstantní. Chceme vědět, kolik investičního kapitálu C je zapotřebí k dosažení návratnosti I = 15 000 $. Předpokládejme, že náš počáteční odhad kapitálu je C = 100 000 $ (B1).
Pro výpočet návratnosti:
Zadáme vzorec pro návratnost (=B1*B2*B3) do B4 a vybereme buňku myší.
Vybereme z hlavní nabídky Nástroje > Hledat řešení, čímž otevřeme dialogové okno Hledat řešení (obrázek 24).
Obrázek 24: Dialogové okno Hledat řešení
Buňka B4 by již měl být zadána v poli Buňka se vzorcem. Pokud však chceme vybrat jinou buňku, použijeme přidružené tlačítko Zmenšit/Rozvinout pro minimalizaci dialogu při výběru požadované buňky.
Klepneme na pole Proměnná buňka, poté zadáme odkaz na buňku B1 nebo ji vybereme myší, aby byl kapitál proměnnou v aktuálním Hledání řešení.
Zadáme požadovaný výsledek vzorce do pole Cílová hodnota. V tomto příkladu je hodnota 15000. Obrázek 25 zobrazuje buňky a pole dialogového okna v tomto okamžiku.
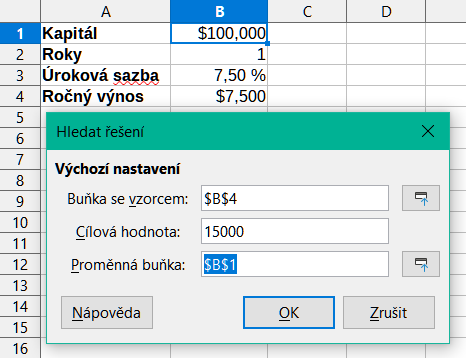
Obrázek 25: Příklad nastavení pro hledání řešení
Klepneme na OK. Objeví se dialogové okno s informacemi o tom, že hledání řešení bylo úspěšné (obrázek 26).
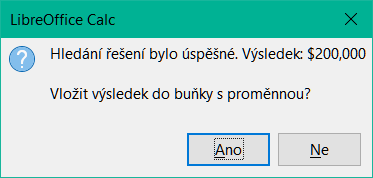
Obrázek 26: Dialog výsledku hledání řešení
Klepnutím na Ano vložíme řešení do buňky s proměnnou. Výsledek je znázorněn na obrázku 27, což naznačuje, že k dosažení návratnosti 15 000 $ je zapotřebí kapitálový požadavek 200 000 $.
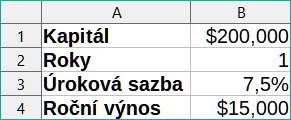
Obrázek 27: Výsledek hledání řešení cíle v listu
Poznámka
Ne každý problém s hledáním řešení dokáže vrátit dobrý výsledek. Závisí to na použitém vzorci, cílové hodnotě a počáteční hodnotě. Algoritmus hledání cíle interně několikrát konverguje k cíli.
Jestliže není hledání cíle úspěšné, zobrazí aplikace Calc informační dialogové okno informující o selhání. Toto dialogové okno nabízí možnost vložení nejbližší hodnotu do proměnné buňky. Podle potřeby stiskneme Ano nebo Ne.
Řešitel představuje propracovanější formu hledání cílů, která nám umožní řešit problémy matematického programování nebo optimalizace. Problém matematického programování se týká minimalizace nebo maximalizace funkce podléhající množině omezení. Takové problémy vyvstávají v mnoha vědeckých, inženýrských, obchodních a jiných oborech. Úplná diskuse o matematickém programování je nad rámec této příručky a čtenář, který má zájem, je odkázán na příslušnou stránku Wikipedie na https://en.wikipedia.org/wiki/Mathematical_optimization, která poskytuje informace na vysoké úrovni a odkazy na podrobnější materiály.
V současné době Calc nabízí následující výběr řešitelských algoritmů:
DEPS (Differential Evolution & Particle Swarm Optimization) Evolutionary Algorithm.
SCO (Social Cognitive Optimization) Evolutionary Algorithm.
Lineární řešitel LibreOffice CoinMP.
Lineární řešitel LibreOffice.
Nelineární iterativní swarm řešitel LibreOffice (experimentální).
Upozornění
Vzhledem k tomu, že Nelineární iterativní swarm řešitel LibreOffice je experimentální nástroj, nemusí být v budoucích verzích Calc podporován, doporučujeme jej nepoužívat, pokud nejsme obeznámeni s nelineárními programovacími koncepty.
Evoluční algoritmy DEPS a SCO jsou určeny k řešení nelineárních problémů – jsou dostupné pouze tehdy, pokud máme nainstalované běhové prostředí Java (Java Runtime Environment) a pokud máme v konfiguraci zapnuto Nástroje > Možnosti > LibreOffice > Upřesnit > Použít běhové prostředí JAVA DEPS Evolutionary Algorithm je výchozí, pokud je k dispozici, jinak je výchozí Lineární řešitel LibreOffice CoinMP.
Dostupné možnosti poskytují flexibilitu při výběru nejvhodnějšího algoritmu pro daný problém, který může být lineární nebo nelineární, a daného požadavku na výkon. Nápověda obsahuje více informací o dostupných algoritmech a jejich možnostech konfigurace.
Abychom mohli vyřešit problém matematického programování pomocí Řešitele, musíme problém formulovat následovně:
Rozhodovací proměnné – sada n nezáporných proměnných x1, … , xn. Rozhodovací proměnné mohou být reálná čísla, ale obvykle to bývají v mnoha problémech skutečného světa celá čísla.
Omezení – soubor lineárních rovnic nebo nerovností, které zahrnují rozhodovací proměnné.
Objektivní funkce – lineární výraz zahrnující rozhodovací proměnné.
Cílem je obvykle najít hodnoty rozhodovacích proměnných, které splňují omezení, a maximalizovat nebo minimalizovat výsledek objektivní funkce.
Po nastavení dat k problému v sešitu Calc vybereme z hlavní nabídky Nástroje > Řešitel, čímž otevřeme dialogové okno Řešitel (obrázek 28).
Poznámka
V závislosti na konfiguraci našeho počítače se může při prvním výběru Nástroje > Řešitel po spuštění Calc zobrazit zpráva. Povaha této zprávy se změní v závislosti na existenci běhového prostředí Java (JRE) v našem systému. Pokud není detekována žádná JRE, bude zpráva jednoduše varováním v tomto smyslu. V případě, že je detekována JRE, ale možnost Nástroje > Možnosti > LibreOffice > Upřesnit > Použít běhové prostředí Java je zakázána, pak zpráva bude obsahovat tlačítko, které tuto možnost povolí.
Cílová buňka
Optimalizovat výsledek na
Změnou buněk
Omezující podmínky
Odkaz na buňku – zadáme odkaz na buňku na rozhodovací proměnnou.
Operátor – definuje parametr pro omezení. Dostupné možnosti zahrnují <= (menší nebo rovno), = (rovná se), => (větší nebo rovno), Celé číslo (hodnoty bez desetinných míst) a Binární (pouze 0 nebo 1).
Hodnota – zadáme hodnotu nebo odkaz na buňku na vzorec omezení.
Tlačítko Odstranit – odstraní aktuálně definované omezení.
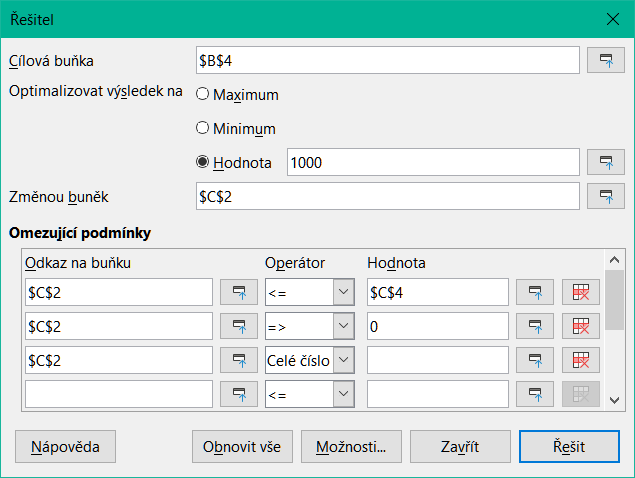
Obrázek 28: Dialogové okno Řešitel
Tip
Nezapomeňme, že u kterékoliv z těchto možností, pokud potřebujeme vybrat buňky pomocí myši, můžeme minimalizovat dialogové okno Řešitele pomocí přidruženého tlačítka Zmenšit/Rozvinout.
Po nastavení řešitele klepneme na tlačítko Řešit pro zahájení procesu úpravy hodnot a výpočtu výsledků. V závislosti na složitosti úkolu to může nějakou dobu trvat. Pokud chceme začít znovu, klikneme na tlačítko Obnovit vše a data vložená do dialogu Řešitel (obrázek 28) se vymažou.
Používáme-li evoluční algoritmus DEPS nebo evoluční algoritmus SCO, může Calc pravidelně přerušovat provádění řešícího stroje a zobrazovat dialogové okno Stav řešitele (obrázek 29). Toto dialogové okno poskytuje diagnostické informace o aktuálním stavu výpočtů řešitele, které mohou zajímat uživatele odborníka. Kliknutím na tlačítko OK tento dialog zrušíme a dokončíme výpočty, nebo kliknutím na tlačítko Pokračovat umožníme řešiteli pokračovat ve zpracování, přičemž diagnostické údaje se v dialogu obnoví v dalším bodě přerušení. Zobrazení dialogového okna Stav řešitele je ve výchozím nastavení povoleno, ale lze jej vypnout zrušením výběru nastavení Zobrazit podrobnosti o stavu řešitele v dialogovém okně Možnosti řešitele.
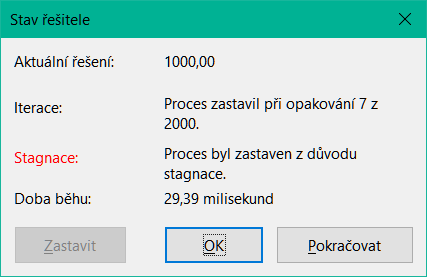 Obrázek 29: Dialogové okno Stav řešitele
Obrázek 29: Dialogové okno Stav řešitele
Po úspěšném dokončení Calc zobrazí dialogové okno Výsledek řešení (obrázek 30). Tento dialog obsahuje tlačítka pro uložení (Použít výsledek) nebo vyřazení (Obnovit předchozí) výsledků.
Obrázek 30: Dialogové okno Výsledek řešení
Dialogové okno Řešitel má také tlačítko Možnosti, které otevře dialogové okno Možnosti zobrazené na obrázku 31.
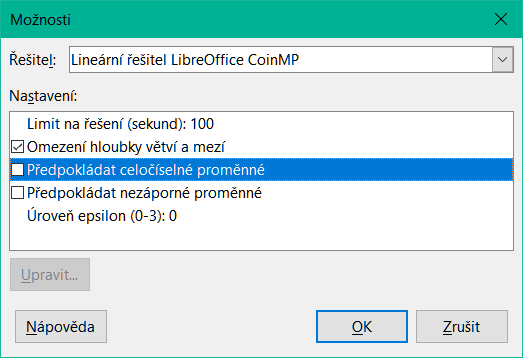
Obrázek 31: Dialogové okno Možnosti řešitele
Algoritmy Řešitele
DEPS Evolutionary Algorithm
SCO Evolutionary Algorithm
Lineární řešitel LibreOffice CoinMP
Lineární řešitel LibreOffice
LibreOffice Swarm nelineární řešitel (experimentální)
Nastavení
Předpokládejme, že máme 10 000 $, které chceme investovat do dvou podílových fondů na jeden rok. Fond X je nízkorizikový fond s úrokovou sazbou 8 % a Fond Y je fond s vyšším rizikem a úrokovou sazbou 12 %. Kolik peněz by mělo být investováno do každého fondu, abychom získali celkový úrok 1 000$?
Chceme-li najít odpověď pomocí Řešitele:
Do listu zadáme následující popisy a data:
Popisy řádků: Fond X, Fond Y, a Celkem v buňkách A2, A3 a A4.
Popisy sloupců: Získaný úrok, Investovaná částka, Úroková sazba a Časový úsek v buňkách B1 až E1.
Úrokové sazby: 8 % a 12 % v buňkách D2 a D3.
Časový úsek: 1 v buňkách E2 a E3.
Celková investovaná částka: 10000$ v buňce C4.
Zadáme libovolnou hodnotu (0$ nebo ponecháme prázdné) v buňce C2 jako částku investovanou do Fondu X.
Zadáme následující vzorce:
Do buňky C3 zadáme vzorec =C4–C2 (celková částka - částka investovaná do fondu X), což je částka investovaná do fondu Y.
Do buněk B2 a B3 zadáme vzorce =C2*D2*E2 (B2) a =C3*D3*E3 (B3).
Do buňky B4 zadáme vzorec =B2+B3 jako celkový získaný úrok. Obrázek 32 zobrazuje pracovní list v tomto bodě.

Obrázek 32: Příklad nastavení řešitele
Výběrem Nástroje > Řešitel z hlavní nabídky otevřeme dialogové okno Řešitel (obrázek 28).
Do pole Cílová buňka vybereme buňku, která obsahuje cílovou hodnotu. V tomto příkladu je to B4, která obsahuje celkovou úrokovou hodnotu.
Zvolíme Hodnota a zadáme 1000 do pole vedle ní. V tomto příkladu je hodnota cílové buňky 1000, protože náš cíl je celkový vydělaný úrok 1 000 $.
Do pole Změnou buněk vybereme buňku C2 v listu. V tomto příkladu potřebujeme najít částku investovanou do Fondu X (buňka C2).
Pomocí následujících polí Odkaz na buňku, Operátor a Hodnota zadáme následující omezující podmínky pro proměnné:
C2 <= C4 – částka investovaná do Fondu X nesmí přesáhnout celkovou dostupnou částku.
C2 => 0 – částka investovaná do Fondu X nemůže být záporná.
C2 je celé číslo – specifikováno pro zjednodušení.
Klepneme na Řešit. Výsledek je znázorněn na obrázku 33.

Obrázek 33: Výsledek příkladu řešitele
V části Data > Statistika na panelu nabídek nabízí Calc několik nástrojů pro rychlou a snadnou statistickou analýzu dat. Mezi tyto nástroje patří:
Vzorkování
Popisná statistika
Analýza rozptylu (ANOVA)
Korelace
Kovariance
Exponenciální vyrovnávání
Klouzavý průměr
Regrese
Párový t-test
F-test
Z-test
Chí kvadrát test
Fourierova analýza
Nástroj Vzorkování vytvoří cílovou tabulku s daty vzorkovanými ze zdrojové tabulky. Nástroj Vzorkování může vybrat vzorky náhodně nebo periodicky. Vzorkování se provádí po řádcích, přičemž celé řady zdrojové tabulky se zkopírují do řádků cílové tabulky. Chceme-li tento nástroj použít, vybereme v hlavní nabídce Data > Statistika > Vzorkování a otevře se dialogové okno Vzorkování (obrázek 34).
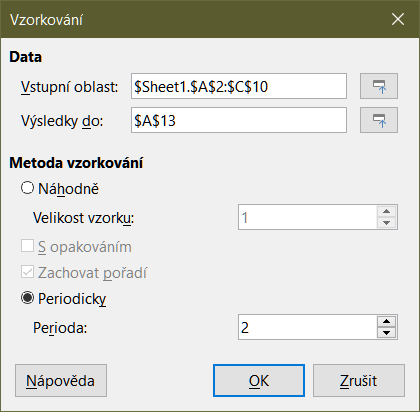
Obrázek 34: Dialogové okno vzorkování
Vstupní oblast
Výsledky do
Náhodně
Velikost vzorku
S opakováním
Zachovat pořadí
Periodicky
Perioda
Tip
Při výběru buňky myší můžeme dialogové okno dočasně zmenšit pomocí tlačítek Zmenšit/Rozvinout vedle polí Vstupní oblast a Výsledky do.
Obrázek 35 ukazuje zdrojovou tabulku (pod nadpisem Zdrojová data) a odpovídající cílovou tabulku (pod nadpisem Cílová data), vzorkované pomocí nastavení znázorněných na obrázku 34.
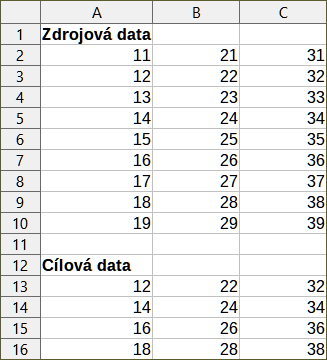
Obrázek 35: Příklad dat pro nástroj Vzorkování
Na poskytnuté sadě dat vytváří nástroj Popisná statistika tabulkovou zprávu o primárních statistických vlastnostech datové sady, jako jsou informace o její centrální tendenci a variabilitě. Výběrem možnosti Data > Statistika > Popisná statistika v hlavní nabídce se otevře dialogové okno Popisná statistika (obrázek 36).
Obrázek 36: Dialogové okno Popisné statistiky
Vstupní oblast
Výsledky do
Sloupce/řádky
Tip
Při výběru buňky myší můžeme dialogové okno dočasně zmenšit pomocí tlačítek Zmenšit/Rozvinout vedle polí Vstupní oblast a Výsledky do.
Obrázek 37 zobrazuje malý soubor dat obsahující výsledky zkoušek žáků ze tří předmětů.
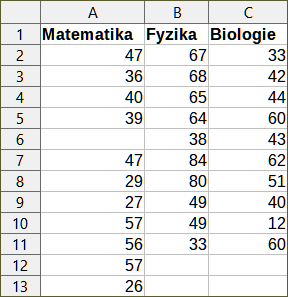
Obrázek 37: Vstupní data pro provedení popisné statistiky
Obrázek 38 zobrazuje statistickou zprávu vygenerovanou pro tato vstupní data s použitím nastavení uvedených na obrázku 36.
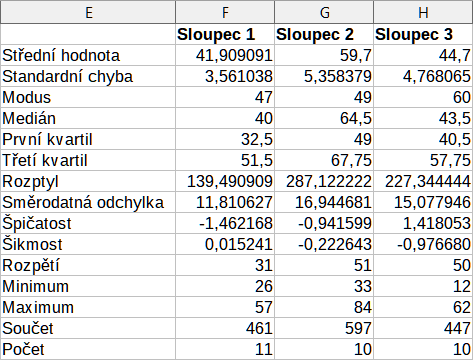
Obrázek 38: Výsledky nástroje popisné statistiky
Tip
Další informace o popisných statistikách nalezneme v příslušném článku na Wikipedii na adrese https://en.wikipedia.org/wiki/Descriptive_statistics.
Nástroj Analýza rozptylu (ANOVA) porovnává střední hodnoty dvou nebo více skupin ve vzorku. Výběrem možnosti Data > Statistika > Analýza rozptylu (ANOVA) z hlavní nabídky otevřeme dialogové okno Analýza rozptylu (ANOVA) (obrázek 39).
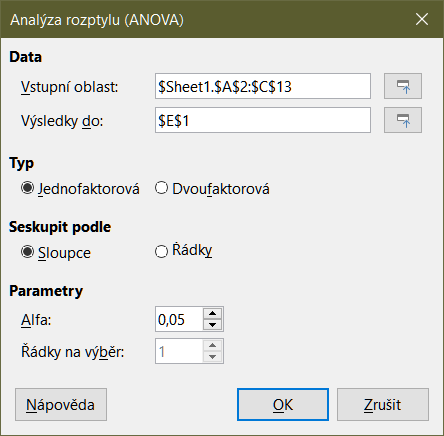
Obrázek 39: Dialog analýzy rozptylu (ANOVA)
Vstupní oblast
Výsledky do
Jednofaktorová / Dvoufaktorová
Sloupce/řádky
Alfa
Řádky na výběr
Tip
Pokud potřebujeme zmenšit dialog při výběru buněk pomocí myši, použijeme tlačítka Zmenšit/Rozbalit vedle polí Rozsah zadávání a Výsledky do.
Pro ilustraci použití tohoto nástroje použijeme sadu vstupních dat z obrázku 37. Obrázek 40 zobrazuje výsledky analýzy rozptylu vytvořené pro tato data s použitím nastavení uvedených na obrázku 39.
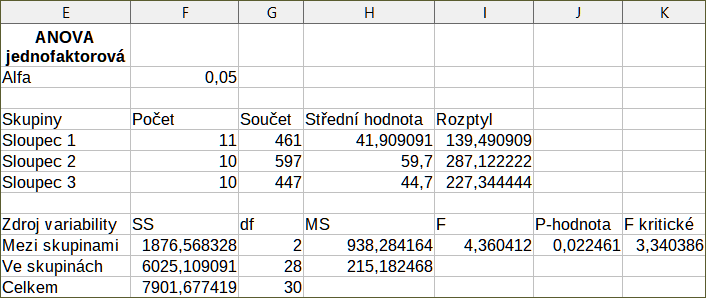
Obrázek 40: Výsledky nástroje analýzy rozptylu (ANOVA)
Tip
Další informace o analýze rozptylu najdeme v příslušném článku na Wikipedii na adrese https://en.wikipedia.org/wiki/Analysis_of_variance.
Nástroj korelace vypočítá korelaci dvou sad číselných dat a vygeneruje výsledný korelační koeficient. Tento koeficient je hodnota mezi -1 a +1, která ukazuje, jak silně jsou dvě proměnné ve vzájemném vztahu. Korelační koeficient +1 označuje dokonalou pozitivní korelaci (shodují se sady dat) a koeficient -1 označuje dokonalou negativní korelaci (sady dat jsou vzájemně inverzní). Výběrem možnosti Data > Statistika > Korelace z hlavní nabídky otevřeme dialogové okno Korelace (obrázek 41).
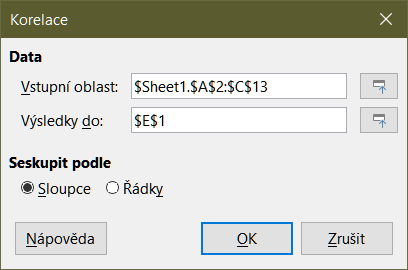
Obrázek 41: Dialogové okno Korelace
Vstupní oblast
Výsledky do
Sloupce/řádky
Tip
Pokud potřebujeme zmenšit dialog při výběru buněk pomocí myši, použijeme tlačítka Zmenšit/Rozbalit vedle polí Rozsah zadávání a Výsledky do.
Pro ilustraci použití tohoto nástroje použijeme opět soubor dat z obrázku 37. Obrázek 42 zobrazuje korelační koeficienty vygenerované pro tato vstupní data s použitím nastavení uvedených na obrázku 41.
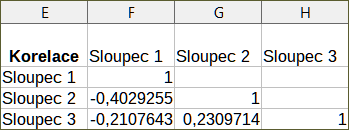
Obrázek 42: Výsledky korelace
Tip
Další informace o statistické korelaci nalezneme v příslušném článku na Wikipedii na adrese https://en.wikipedia.org/wiki/Correlation_and_dependence.
Nástroj Kovariance měří, do jaké míry se dvě sady číselných dat liší. Výběrem možnosti Data > Statistika > Kovariance z hlavní nabídky otevřeme dialogové okno Kovariance (obrázek 43).
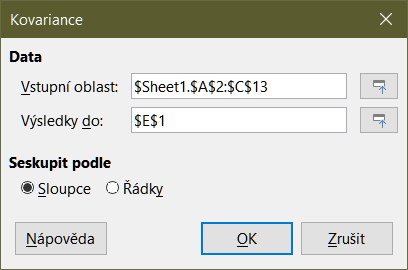
Obrázek 43: Dialog o kovarianci
Vstupní oblast
Výsledky do
Sloupce/řádky
Tip
Pokud potřebujeme zmenšit dialog při výběru buněk pomocí myši, použijeme tlačítka Zmenšit/Rozbalit vedle polí Rozsah zadávání a Výsledky do.
Pro ilustraci použití tohoto nástroje použijeme opět soubor dat z obrázku 37. Obrázek 44 zobrazuje šest hodnot kovariance vygenerovaných pro tato vstupní data s použitím nastavení uvedených na obrázku 43.
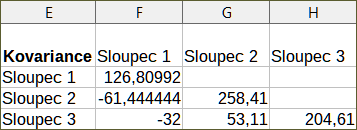
Obrázek 44: Výsledky kovariance
Tip
Další informace o statistické kovarianci nalezneme v příslušném článku na Wikipedii na adrese https://en.wikipedia.org/wiki/Covariance.
Nástroj Exponenciální vyhlazování filtruje sadu dat, aby bylo dosaženo vyhlazených výsledků. Používá se v oblastech, jako je analýza akciového trhu a ve vzorkových měřeních. Výběrem možnosti Data > Statistika > Exponenciální vyrovnávání z hlavní nabídky otevřeme dialogové okno Exponenciální vyrovnávání (obrázek 45).
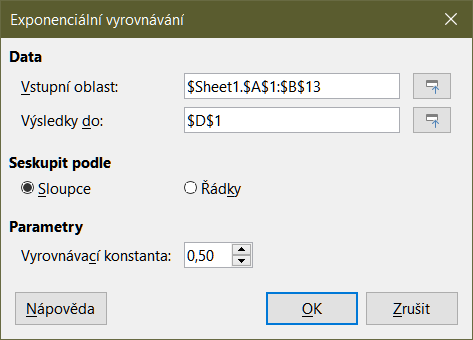
Obrázek 45: Dialogové okno Exponenciální vyhlazení
Vstupní oblast
Výsledky do
Sloupce/řádky
Vyrovnávací konstanta
Tip
Pokud potřebujeme zmenšit dialog při výběru buněk pomocí myši, použijeme tlačítka Zmenšit/Rozbalit vedle polí Rozsah zadávání a Výsledky do.
Pro ilustraci použití tohoto nástroje použijeme soubor dat zobrazený na obrázku 46. Tabulka má dvě časové řady představující impulzní funkce v časech t=0 a t=2.
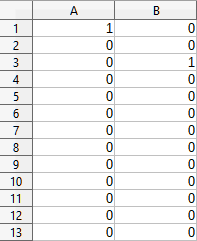
Obrázek 46: Vstupní soubor dat pro příklad exponenciálního vyhlazování
Obrázek 47 zobrazuje vyhlazené výsledky pro tato vstupní data při použití nastavení uvedených na obrázku 45. V tabulce výsledků je možné změnit výsledek změnou parametru Alpha.
Tip
Další informace o exponenciálním vyrovnávání nalezneme v příslušném článku na Wikipedii na adrese https://en.wikipedia.org/wiki/Exponential_smoothing.
Obrázek 47: Výsledky nástroje Exponenciální vyhlazení
Nástroj Klouzavý průměr vypočítá klouzavý průměr datové sady časové řady. Výběrem možnosti Data > Statistika > Klouzavý průměr v hlavní nabídce otevřeme dialogové okno Klouzavý průměr (obrázek 48).
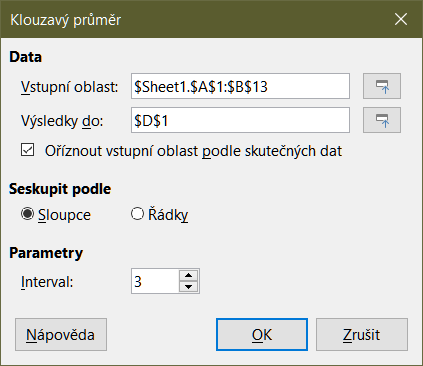
Obrázek 48: Dialog klouzavého průměru
Vstupní oblast
Výsledky do
Oříznout vstupní oblast podle skutečných dat
Sloupce/řádky
Interval
Tip
Pokud potřebujeme zmenšit dialog při výběru buněk pomocí myši, použijeme tlačítka Zmenšit/Rozbalit vedle polí Rozsah zadávání a Výsledky do.
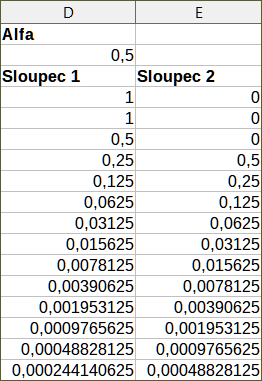
Pro ilustraci použití tohoto nástroje použijeme opět soubor dat z obrázku 46. Obrázek 49 zobrazuje klouzavé průměry vypočtené pro tato vstupní data s použitím nastavení uvedených na obrázku 48.
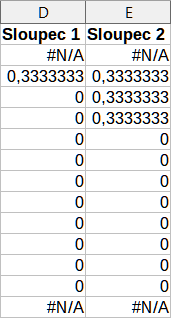
Obrázek 49: Vypočtené klouzavé průměry
Tip
Další informace o klouzavém průměru nalezneme v příslušném článku na Wikipedii na adrese https://en.wikipedia.org/wiki/Moving_average.
Nástroj Regrese provádí lineární, logaritmickou nebo mocninnou regresní analýzu souboru dat obsahujícího jednu závislou proměnnou a více nezávislých proměnných. Výběrem možnosti Data > Statistika > Regrese z hlavní nabídky otevřeme dialogové okno Regrese (obrázek 50).
Oblast nezávislých proměnných (X)
Oblast závislé proměnné (Y)
Oblasti X a Y mají popisky
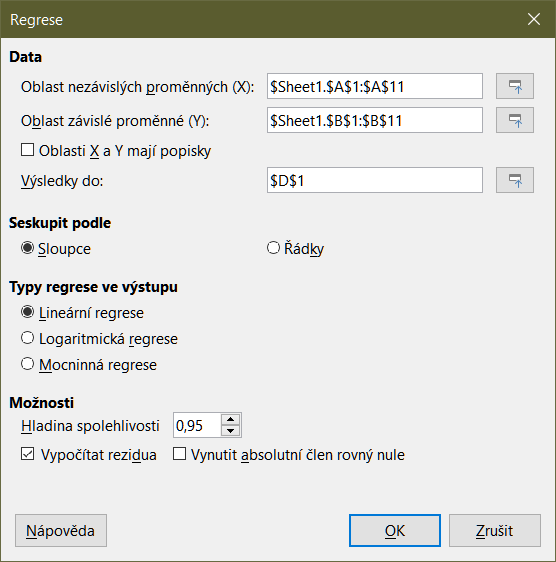
Obrázek 50: Dialogové okno Regrese
Výsledky do
Sloupce/řádky
Lineární regrese
Logaritmická regrese
Mocninná regrese
Hladina spolehlivosti
Vypočítat rezidua
Vynutit absolutní člen rovný nule
Tip
Při výběru buňky myší můžeme dočasně dialogové okno zmenšit pomocí tlačítek Zmenšit/Rozvinout vedle polí Oblast nezávislých proměnných (X), Oblast závislé proměnné (Y) a Výsledky do.
Tip
Aplikace Calc využívá malou, jinak prázdnou oblast, nad tlačítky Nápověda, OK a Storno, aby poskytl zpětnou vazbu o chybných výběrech v dialogovém okně. Například se zobrazí text "Oblast nezávislých proměnných není platná.", když nezadáme platnou oblast buněk v poli Oblast nezávislých proměnných (X). V tomto případě tlačítko OK zešedne.
Pro ilustraci použití tohoto nástroje použijeme sadu dat zobrazenou na obrázku 51. Tato tabulka obsahuje měření prováděná v intervalech 1 s.
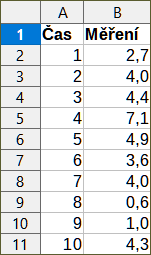
Obrázek 51: Vstupní soubor dat pro regresní analýzu
Na obrázku 52 jsou zobrazeny regresní výstupy vypočtené pro tato vstupní data s použitím nastavení uvedených na obrázku 50.
Tip
Další informace o regresní analýze nalezneme v příslušném článku na Wikipedii na adrese https://en.wikipedia.org/wiki/Regression_analysis.
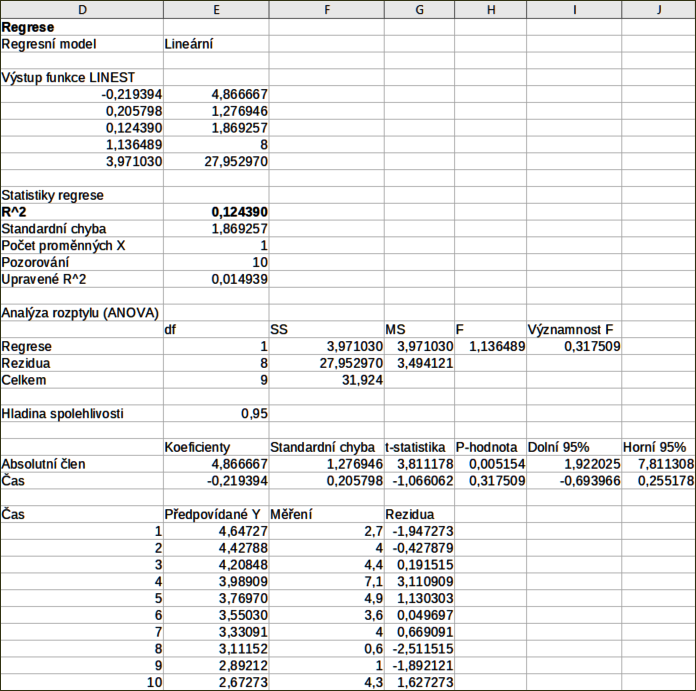
Obrázek 52: Výstupy lineární regrese
Nástroj Párový t-test porovnává průměry populací dvou souvisejících sad vzorků a určuje rozdíl mezi nimi. Výběrem možnosti Data > Statistika > Párový t-test z hlavní nabídky otevřeme dialogové okno Párový t-test (obrázek 53).
Oblast proměnné 1
Oblast proměnné 2
Výsledky do
Sloupce/řádky
Tip
Při výběru buňky myší můžeme dočasně dialogové okno zmenšit pomocí tlačítek Zmenšit / Rozvinout, které najdeme vedle polí Oblast proměnné 1, Oblast proměnné 2 a Výsledky do.
Obrázek 53: Dialog párového t-testu
Jako příklad použití tohoto nástroje použijeme sadu vstupních dat zobrazenou na obrázku 54. Datové sady ve sloupcích A a B představují dvě sady párových hodnot označovaných jako Proměnná 1 a Proměnná 2.
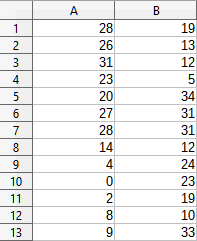
Obrázek 54: Vstupní data pro příklad párového t-testu
Obrázek 55 zobrazuje výsledky párového t-testu vypočtené pro tato vstupní data s použitím nastavení uvedených na obrázku 53.
Do výsledné tabulky je možné vložit různé hodnoty pro Alfa a Rozdíl středních hodnot v hypotéze. T hodnoty (Statistika, Kritická jednostranná a Kritická dvoustranná) budou aktualizovány automaticky.
Tip
Další informace o párových t-testech nalezneme v příslušném článku na Wikipedii na adrese https://en.wikipedia.org/wiki/Student's_t-test.
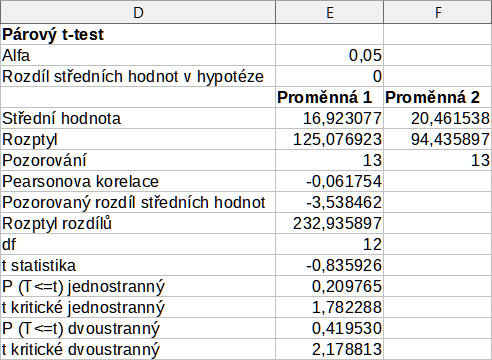
Obrázek 55: Výsledky párového t-testu
Nástroj F-test vypočítá F-test ze dvou vzorků dat. Nástroj se používá k testování hypotézy, že rozptyl dvou populací je stejný. Kliknutím na Data > Statistika > F-test v hlavní nabídce otevřeme dialogové okno F-test zobrazené na obrázku 56 a definujeme požadované vstupy nástroje.
Obrázek 56: Dialogové okno F-testu
Oblast proměnné 1
Oblast proměnné 2
Výsledky do
Sloupce/řádky
Tip
Použijte Zmenšit / Rozbalit tlačítka vedle tlačítka Rozsah proměnné 1 , Rozsah proměnné 2 , a Výsledky do pole, pokud potřebujete zmenšit dialog při výběru buněk pomocí myši.
Pro ilustraci použití tohoto nástroje použijeme opět soubor dat z obrázku 54. V tomto případě představují údaje ve sloupcích A a B dvě nezávislé sady vzorků, označované jako Proměnná 1 a Proměnná 2. Obrázek 57 zobrazuje výsledky F-testu vypočtené pro tato vstupní data s použitím nastavení uvedených na obrázku 56.
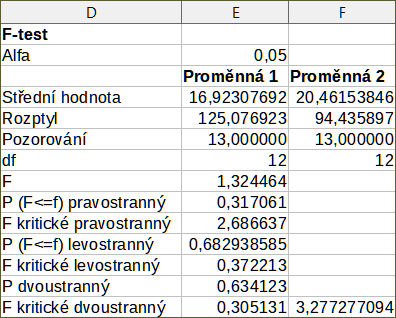
Obrázek 57: Výsledky nástroje F-test
Do výsledné tabulky je možné vložit různé hodnoty pro symbol Alfa. F kritické hodnoty (pravostranný, levostranný a oboustranná) budou aktualizované automaticky.
Tip
Další informace o F-testech nalezneme v příslušném článku na Wikipedii na adrese https://en.wikipedia.org/wiki/F-test.
Nástroj Z-test vypočítá Z-test dvou vzorků dat. Nástroj provede Z-test dvou vzorků pro testování nulové hypotézy, že neexistuje žádný rozdíl mezi průměrem těchto dvou datových sad. Z-test pracuje lépe pro větší množinu vzorků (n > 30); pokud máme menší množinu vzorků, bude vhodnější použít nástroj Párový t-test. Kliknutím na Data > Statistika > Z-test v hlavní nabídce otevřeme dialogové okno z-testu zobrazené na obrázku 58 a definujeme požadované vstupy nástroje.
Oblast proměnné 1
Oblast proměnné 2
Výsledky do
Sloupce/řádky
Tip
Při výběru buňky myší můžeme dočasně dialogové okno zmenšit pomocí tlačítek Zmenšit/Rozvinout vedle polí Oblast proměnné 1, Oblast proměnné 2 a Výsledky do.
Obrázek 58: dialogové okno z-testu
Jako příklad použití tohoto nástroje použijeme opět sadu vstupních dat zobrazenou na obrázku 54. V tomto případě představují údaje ve sloupcích A a B dva soubory dat, označované jako Proměnná 1 a Proměnná 2. Obrázek 59 zobrazuje výsledky Z-testu vypočtené pro tato vstupní data s použitím nastavení uvedených na obrázku 58.
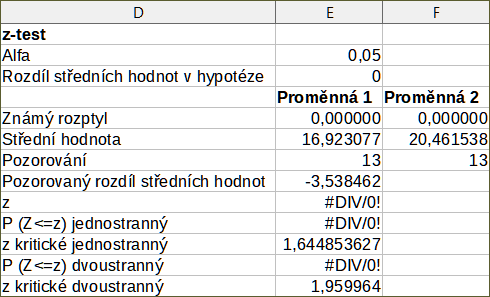
Obrázek 59: Výsledky z nástroje Z-test
Aby nástroj Z-testu fungoval správně, musí být do příslušné buňky vložena známá odchylka pro každý vzorek. V příkladu ukázaném na obrázku 59, hodnoty rozptylu (125,076923 a 94,435897) vložíme pomocí vzorce =VAR(A1:A13) do buňky E5 a pomocí vzorce =VAR(B1:B13) do buňky F5. Následné hodnoty z a P budou automaticky aktualizovány.
Je možné vložit různé hodnoty pro Alfa (buňka E2 v uvedeném příkladu) a Rozdíl středních hodnot v hypotéze (buňka E3 v uvedeném příkladu). Stejně jako u výše popsaných známých změn odchylek, po změně Alfa a předpokládaného Rozdílu středních hodnot v hypotéze budou automaticky aktualizovány následující hodnoty z a P.
Tip
Při analýze výsledků Z-testu porovnáme vybranou hladinu Alfa s příslušnou vypočítanou hodnotou P (podle toho, zda je vyžadován jednostranný nebo dvoustranný test). Pokud je vypočtená hodnota P menší než úroveň Alfa, měla by být odmítnuta hypotéza (která v uvedeném příkladu spočívá v tom, že prostředky obou datových souborů jsou stejné).
Tip
Další informace o Z-testech nalezneme v příslušném článku na Wikipedii na adrese https://en.wikipedia.org/wiki/Z-test.
Nástroj Test chí-kvadrát vypočítá test chí-kvadrát vzorku dat, který určuje, jak dobře odpovídá soubor naměřených hodnot odpovídajícímu souboru očekávaných hodnot. Výběrem Data > Statistika > Chi-kvadrát test v hlavní nabídce se dostaneme do dialogového okna Test nezávislosti (Chi-kvadrát) (obrázek Chyba: zdroj odkazu nenalezen).
Vstupní oblast
Výsledky do
Sloupce/řádky
Obrázek 60: Dialogové okno testu nezávislosti (chí-kvadrát)
Tip
Pokud potřebujeme zmenšit dialog při výběru buněk pomocí myši, použijeme tlačítka Zmenšit/Rozbalit vedle polí Rozsah zadávání a Výsledky do.
Jako příklad použití tohoto nástroje použijeme opět sadu vstupních dat zobrazenou na obrázku 54. V tomto případě jsou data ve sloupci A pozorovaná data, zatímco data ve sloupci B jsou odpovídající očekávané hodnoty. Obrázek 61 zobrazuje výsledky chí-kvadrát testu vypočtené pro tato vstupní data při použití nastavení uvedených na obrázku Chyba: zdroj odkazu nenalezen.
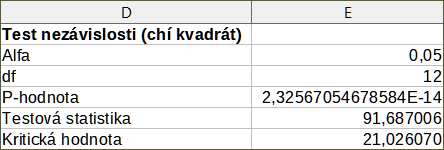
Obrázek 61: Výsledky chí-kvadrát testu
Do výsledné tabulky je možné vložit různé hodnoty pro symbol Alfa. Kritická hodnota bude aktualizována automaticky.
Tip
Další informace o testech chí-kvadrát nalezneme v příslušném článku na Wikipedii na adrese https://en.wikipedia.org/wiki/Chi-squared_test.
Nástroj Fourierova analýza provádí Fourierovu analýzu datového souboru výpočtem diskrétní Fourierovy transformace (DFT) vstupního pole komplexních čísel pomocí algoritmů rychlé Fourierovy transformace (FFT). Výběrem možnosti Data > Statistika > Fourierova analýza v hlavní nabídce otevřeme dialogové okno Fourierova analýza (obrázek 62).
Obrázek 62: Dialog Fourierova analýza
Vstupní oblast
Výsledky do
Vstupní oblast má popisek
Sloupce/řádky
Inverzní
Výstup v polárním tvaru
Minimální velikost pro výstup v polárním tvaru
Tip
Pokud potřebujeme zmenšit dialog při výběru buněk pomocí myši, použijeme tlačítka Zmenšit/Rozbalit vedle polí Rozsah zadávání a Výsledky do.
Tip
Aplikace Calc využívá malou, jinak prázdnou oblast, nad tlačítky Nápověda, OK a Storno, aby poskytl zpětnou vazbu o chybných výběrech v dialogovém okně. Například se zobrazí text "Neplatná adresa výstupu.", když nezadáme platnou oblast buněk v poli Výsledky do. V tomto případě tlačítko OK zešedne.
Jako příklad použití tohoto nástroje použijeme sadu vstupních dat uvedenou ve sloupcích B (reálné hodnoty) a C (imaginární hodnoty) tabulky na obrázku 63. Údaje uvedené ve sloupcích E (reálné hodnoty) a F (imaginární hodnoty) tabulky jsou výsledky Fourierovy transformace vypočtené nástrojem pro tato vstupní data s použitím nastavení uvedených na obrázku 62.
Poznámka
Pro ty, kteří mají technický zájem o algoritmy používané nástrojem Fourierova analýza, radix-2 decimation-in-time FFT se používá, pokud je délka vstupní sekvence sudá mocnina 2, zatímco Bluesteinův FFT algoritmus se používá, když délka vstupní sekvence není sudá mocnina 2.
Tip
Další informace o Fourierově analýze nalezneme v příslušném článku na Wikipedii na adrese https://en.wikipedia.org/wiki/Fourier_analysis.
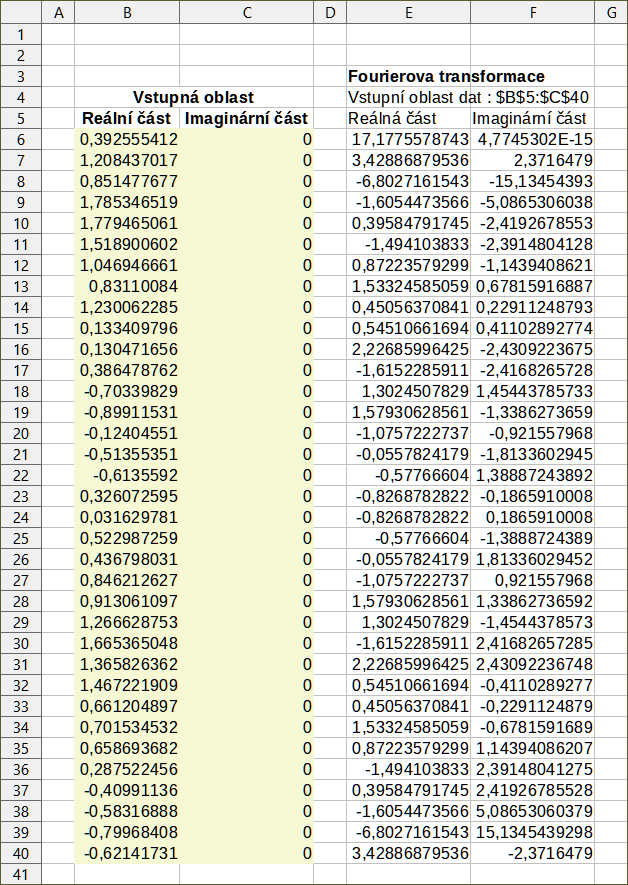
Obrázek 63: Nástroj pro Fourierovu analýzu – příklad vstupních dat a výsledků