
Calc Guide 7.4
Kapitola 13
Aplikace Calc jako databáze
Tento dokument je chráněn autorskými právy © 2023 týmem pro dokumentaci LibreOffice. Přispěvatelé jsou uvedeni níže. Dokument lze šířit nebo upravovat za podmínek licence GNU General Public License (https://www.gnu.org/licenses/gpl.html), verze 3 nebo novější, nebo the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0/), verze 4.0 nebo novější.
Všechny ochranné známky uvedené v této příručce patří jejich vlastníkům.
|
Skip Masonsmith |
Kees Kriek |
|
|
Andrew Pitonyak |
Barbara Duprey |
Jean Hollis Weber |
|
Simon Brydon |
Kees Kriek |
Zachary Parliman |
|
Steve Fanning |
Leo Moons |
Felipe Viggiano |
|
Rafael Lima |
|
|
Jakékoli připomínky nebo návrhy k tomuto dokumentu prosím směřujte do fóra dokumentačního týmu na adrese https://community.documentfoundation.org/c/documentation/loguides/ (registrace je nutná) nebo pošlete e-mail na adresu: loguides@community.documentfoundation.org.
Poznámka
Vše, co napíšete do fóra, včetně vaší e-mailové adresy a dalších osobních údajů, které jsou ve zprávě napsány, je veřejně archivováno a nemůže být smazáno. E-maily zaslané do fóra jsou moderovány.
Vydáno březen 2023. Založeno na LibreOffice 7.4 Community.
Jiné verze LibreOffice se mohou lišit vzhledem a funkčností.
Některé klávesové zkratky a položky nabídek jsou v systému macOS jiné než v systémech Windows a Linux. V následující tabulce jsou uvedeny nejdůležitější rozdíly, které se týkají informací uvedených v tomto dokumentu. Podrobnější seznam nalezneme v nápovědě k programu a v příloze A (Klávesové zkratky) této příručky.
|
Windows nebo Linux |
Ekvivalent pro macOS |
Akce |
|
Výběr v nabídce Nástroje > Možnosti |
LibreOffice > Předvolby |
Otevřou se možnosti nastavení. |
|
Klepnutí pravým tlačítkem |
Control + klepnutí a/nebo klepnutí pravým tlačítkem myši v závislosti na nastavení počítače |
Otevře se místní nabídka. |
|
Ctrl (Control) |
⌘ (Command) |
Používá se také s dalšími klávesami. |
|
F11 |
⌘ + T |
Otevře se postranní lišta Styly. |
V mnoha každodenních scénářích lze tabulky Calc použít k agregaci sad dat a provádění jejich analýz. Jelikož jsou data v tabulce rozložena v tabulkovém zobrazení, jasně viditelná a snadno upravitelná nebo rozšiřitelná, někteří uživatelé možná nebudou potřebovat komplexní prostředky relační databáze poskytované komponentou Base LibreOffice. Pro takové uživatele má Calc dostatečné funkce, aby fungoval jako jednoduchá, ale zároveň schopná platforma podobná databázi. V této kapitole je uveden přehled těchto možností.
Pro ty uživatele, kteří se zpočátku rozhodli spravovat svá data v tabulce Calc a následně se rozhodli, že potřebují použít komplexnější databázový systém, je migrace dat z aplikace Calc do aplikace Base přímočará. V opačném směru, pro uživatele aplikace Base, kteří chtějí využít některé funkce aplikace Calc k analýze nebo vizualizaci svých dat, lze Base použít k vytváření propojených datových rozsahů v souborech Calcu, k analýze kontingenčních tabulek nebo jako základ pro grafy. Více informací najdeme v příručce Průvodce aplikací Base.
Dřívější verze této kapitoly obsahovaly několik příkladů s makry LibreOffice Basic. Ty jsou nyní k dispozici na wiki nadace The Document Foundation na adrese https://wiki.documentfoundation.org/Macros/Calc. Většina informací o makrech na těchto stránkách je převzata nebo upravena z knihy Andrewa Pitonyaka OpenOffice.org Macros Explained (OOME) a z odkazu na rozhraní API LibreOffice na adrese https://api.libreoffice.org/docs/idl/ref/index.html.
V typické databázi jsou související data organizována do tabulek, které mají řádky a sloupce podobné tabulkám. Každý řádek tabulky představuje datový záznam, zatímco každý sloupec představuje pole v jednotlivých záznamech. Každá buňka v poli obsahuje samostatnou datovou položku nebo atribut, jako je např. jméno, zatímco každý záznam obsahuje související atributy, které odpovídají jediné entitě jako je např. osoba. Databázová tabulka má sklon mít pevný počet polí, ale může mít neurčitý počet záznamů.
Zatímco tabulka může mít stovky nebo tisíce řádků, jednotlivé záznamy lze snadno najít, získat a aktualizovat pomocí požadavků na informace, kterým se říká dotazy a které vyhledávají záznamy splňující zadanou sadu kritérií. Právě tento snadný přístup činí databázovou tabulku užitečnější než prosté vyplňování informací v neuspořádané tabulce.
Pro ilustraci tohoto konceptu databázové tabulky uvažujme příklad klasifikačního listu třídy (obrázek 1). V tomto listu představuje každý řádek jednoho studenta, který se účastní výuky, přičemž každý sloupec obsahuje jména a známky studenta. V této tabulce můžeme rychle vyhledávat známky jednotlivých studentů jednoduše pomocí hledání jména studenta a můžeme ručit, kteří studenti prospívají pomocí filtrování záznamů s horším než průměrným skóre.
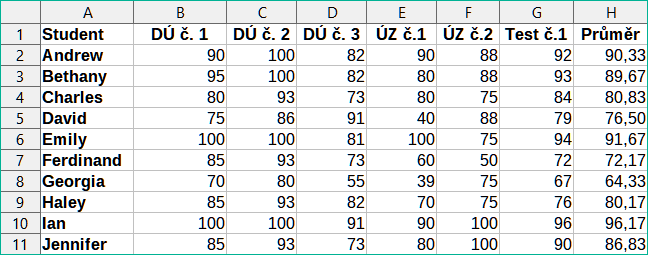
Obrázek 1: Příklad klasifikačního listu
Mnoho moderních systémů pro správu databází je založeno na relačním modelu databáze, v němž jsou data a vztahy reprezentovány řadou vzájemně propojených tabulek. Komponenta LibreOffice Base je plně vybavený systém správy relačních databází. Aplikace Calc nepodporuje relační databázový model.
List aplikace Calc je podobný ploché nerelační databázové tabulce a je možné, aby databázová tabulka byla obsažena v listu Calc. Data lze hloubkově analyzovat pomocí široké škály nástrojů a funkcí. Lze je třídit, filtrovat, otáčet a vizuálně prezentovat v 2-D/3-D grafech a grafikách. Calc nenahrazuje plnohodnotnou databázovou aplikaci, ale může být užitečný pro správu dat v mnoha malých osobních nebo profesních kontextech.
Pokud chceme nastavit databázovou tabulku v listu aplikace Calc, musíme nejprve nastavit oblast, ve které bude tabulka umístěna. Tento krok je nezbytný, protože některé z databázových funkcí aplikace Calc potřebují pro přístup nebo úpravu znát umístění tabulky. Takovou oblast představuje v aplikaci Calc oblast, což je souvislá skupina jedné nebo více buněk. Aby byla oblast tabulky snadno přístupná, můžeme ji přiřadit smysluplný název. To má čtyři konkrétní výhody:
Pojmenování oblasti usnadňuje identifikaci, především pokud pracujeme s více oblastmi v dokumentu.
Na pojmenovanou oblast lze odkazovat spíše podle jejího názvu než jen podle její adresy. Máte-li například oblast s názvem Skóre, můžeme na ni jednoduše odkázat v buňce pomocí vzorce, jako je =SUM(Skóre).
Název odkazů na pojmenované oblasti se automaticky aktualizuje při každé změně adresy oblasti. Tím se vyhneme nutnosti měnit jednotlivé odkazy při každé změně umístění oblasti.
Všechny pojmenované oblasti jsou rychle zobrazitelné a přístupné pomocí Navigátoru, který otevřeme volbou Zobrazit > Navigátor v hlavní nabídce, stisknutím klávesy F5 nebo klepnutím na ikonu Navigátor
Aplikace Calc nabízí dva typy pojmenovaných oblastí: databázové oblasti, které ukládají nastavení pro databázové operace a standardní pojmenované oblasti, které ho neukládají.
Technicky vzato je pojmenovaná oblast pojmenovaným výrazem vzorce a její obsah je vždy nastaven jako řetězec. Běžně používaným typem výrazu je absolutní oblast buněk, například „$List1.$A$1:$E$15“. Jsou však možné i jiné typy výrazů. Například výraz „$List1.$A$1:$A$4~$List1.$B$1:$B$4“ zahrnuje dvě samostatné oblasti buněk (znak tilda je operátor spojování odkazů). Alternativně lze definovat výraz vzorce, například „PI()*B1*B1“, který vypočítá plochu kruhu s daným poloměrem. Ve zbývající části této kapitoly se budeme zabývat pouze pojmenovanými oblastmi definovanými jako jedna maticová oblast buněk.
Novou pojmenovanou oblast vytvoříme rychle tak, že vybereme příslušné buňky v listu a pak jednoduše začneme psát název do pole Název, které se nachází vlevo od Lišty vzorců. Všimneme si nápovědy „Zadejte název pro oblasti“, která se zobrazí při psaní, a po dokončení psaní stiskneme klávesu Enter.
Pojmenované oblasti jsou také vytvářeny pomocí dialogového okna Definovat oblast (obrázek 2), které otevřeme výběrem List > Pojmenované oblasti a výrazy > Definovat v hlavní nabídce nebo kliknutím na tlačítko Přidat v dialogovém okně Spravovat názvy (obrázek 3).
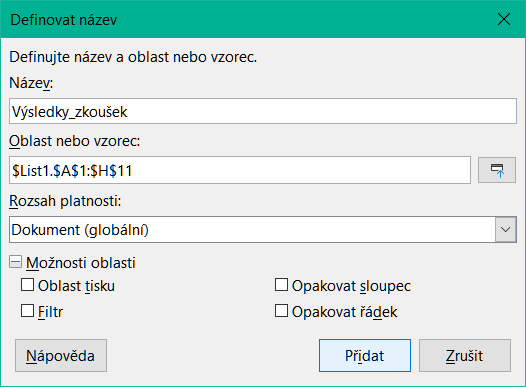
Obrázek 2: Dialogové okno Definovat název
Chceme-li vytvořit pojmenovanou oblast, vybereme oblast buněk v listu a otevřeme dialogové okno Definovat název. Poté oblast smysluplně pojmenujeme a klepnutím na Přidat jej přidáme do seznamu pojmenovaných rozsahů aktuálního dokumentu. K těmto oblastem pak můžeme přistupovat a spravovat je pomocí dialogového okna Spravovat názvy (obrázek 3), které otevřeme pomocí volby List > Pojmenované oblasti a výrazy > Spravovat v hlavní nabídce nebo stisknutím kombinace kláves Ctrl + F3 nebo výběrem Spravovat názvy v Poli názvu vlevo na liště Vzorec.
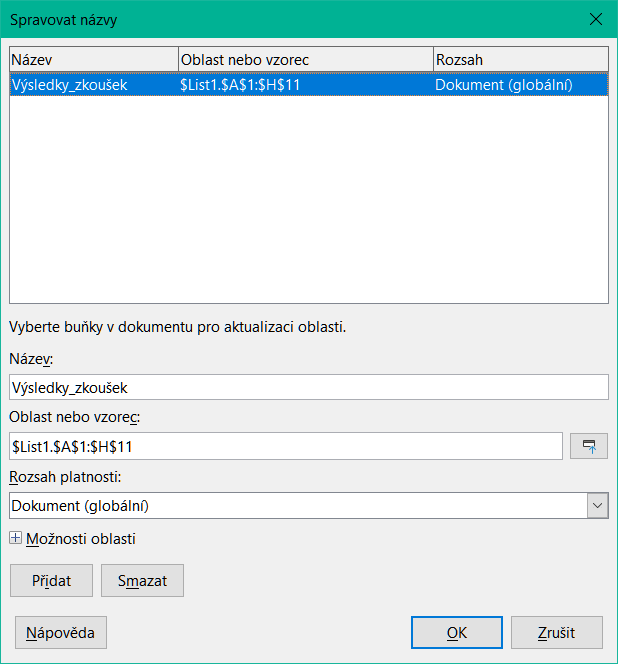
Obrázek 3: Dialogové okno Spravovat názvy
Pokud chceme omezit psaní při odkazování na pojmenovanou oblast, můžeme dialogové okno Vložit názvy (obrázek 4) otevřít výběrem možnosti Vložit > Pojmenované oblasti a výrazy nebo List > Pojmenované oblasti a výrazy > Vložit v hlavní nabídce. Vybereme položku příslušné pojmenované oblasti a klepnutím na tlačítko Vložit vložíme vybranou pojmenovanou oblast na aktuální pozici kurzoru.
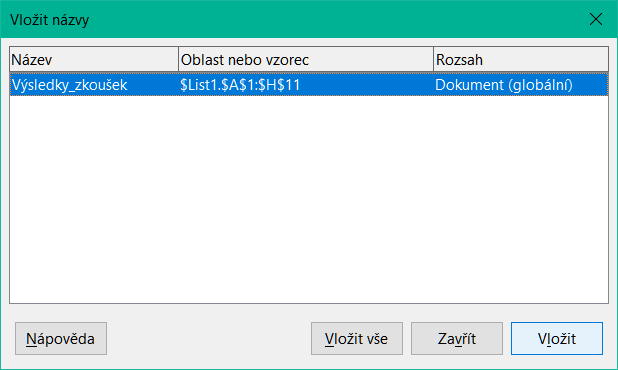
Obrázek 4: Dialogové okno Vložit názvy
Podrobnější informace o vytváření a správě oblastí najdeme v kapitole 6, Tisk, export, odesílání e-mailů a podepisování, a v kapitole 7, Použití vzorců a funkcí.
Pomocí nástroje Vytvořit názvy, ke kterému se dostaneme pomocí volby List > Pojmenované oblasti a výrazy > Vytvořit v hlavní nabídce (obrázek 5) můžeme ze záhlaví tabulky vytvořit více pojmenovaných oblastí současně. Tato záhlaví lze přebírat z okrajů tabulky – horní a dolní řádky a levé a pravé sloupce – a každý řádek nebo sloupec, kterému odpovídá záhlaví, se použije k vytvoření pojmenovaných oblastí. Pokud se například rozhodneme vytvořit oblasti ze záhlaví obsažených v horním řádku tabulky, bude každá oblast vygenerována z jednoho sloupce odpovídající označení záhlaví.
Poznámka
Buňky záhlaví nejsou zahrnuty do pojmenovaných oblastí generovaných pomocí nástroje Vytvořit názvy. Důvodem je to, že popisky v každé z těchto buněk se používají k pojmenování oblastí.
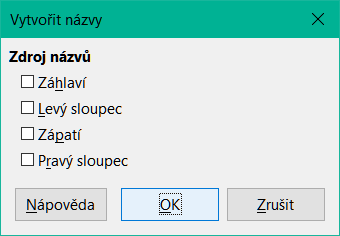
Obrázek 5: Dialogové okno Vytvořit názvy
Chceme-li použít nástroj Vytvořit názvy:
V listu vybereme tabulku, ze které chceme vytvořit pojmenované oblasti. Nezapomeňme do výběru zahrnout záhlaví řádků nebo sloupců.
Otevřeme dialogové okno Vytvořit názvy pomocí volby Pojmenované oblasti a výrazy > Vytvořit z hlavní nabídky.
Calc automaticky identifikuje, které řádky nebo sloupce obsahují záhlaví a označí odpovídající zaškrtávací pole – Záhlaví, Levý sloupec, Zápatí, Pravý sloupec. Pokud však chceme tento výběr změnit, můžeme v tomto kroku ručně označit nebo odznačit kteroukoliv volbu.
Klepnutím na tlačítko OK zavřeme dialogové okno a vytvoříme nové pojmenované oblasti.
Tip
Musíme se vyhnout tomu, aby více řádků nebo sloupců mělo stejný popisek, protože oblasti z nich generované by pak sdílely stejný název a mohly by při další práci působit problémy.
Ačkoli ji lze používat jako běžnou pojmenovanou oblast, databázová oblast je určena k použití jako databázová tabulka, přičemž každý řádek představuje záznam a každá buňka pole v rámci záznamu. Konkrétně se databázová oblast liší od pojmenované oblasti následovně:
Databázová oblast nemůže být výrazem vzorce, ale pouze jedním obdélníkovým rozsahem buněk. Tuto oblast lze formátovat jako tabulku, přičemž první řádek je vyhrazen pro záhlaví a poslední řádek pro mezisoučty. Formátování buněk lze také zachovat pro každé pole v tabulce.
Na databázovou oblast se nelze odkazovat vzhledem k základní adrese v rámci listu, což je možné u pojmenované oblasti.
Databázová oblast ukládá nastavení třídění, filtrování, mezisoučty a importu dat do tzv. datových struktur nazývaných deskriptory, které lze získat a přistupovat k nim pomocí maker. Všechny deskriptory databázové oblasti jsou aktualizovány, když je provedena operace databáze s oblastí buněk rozsahu databáze.
Na rozdíl od pojmenované oblasti lze databázovou oblast připojit k externímu zdroji dat, odkud lze data načíst do dokumentu tabulkového procesoru.
Databázové oblasti lze vytvářet, upravovat a odstraňovat pomocí dialogového okna Definovat databázovou oblast (obrázek 6).
Vytvoření databázové oblasti:
Pokud chceme, aby Calc automaticky určil celou oblast naší databázové tabulky, vybereme jednu buňku v její oblasti. Pokud chceme explicitně definovat oblast databázové tabulky, vybereme všechny příslušné buňky.
Otevřeme dialogové okno Definovat databázovou oblast pomocí Data > Definovat oblast.
Do pole Název zadáme název oblasti. Pro název oblasti můžeme použít pouze písmena, čísla a podtržítka; mezery, spojovníky a další znaky nejsou povoleny.
Klepnutím na symbol rozbalení (obvykle plus nebo trojúhelník) vedle popisku Možnosti rozbalíme tuto část a zobrazíme a vybereme následující možnosti:
Obsahuje popisky sloupců – Označuje, zda je horní řádek vyhrazen pro záhlaví polí.
Obsahuje řádek součtů – Označuje, zda je spodní řádek vyhrazen pro součty.
Vložit nebo smazat buňky – Je-li tato možnost aktivní, vloží se do databázové oblasti, po přidání nových záznamů do zdroje, nové řádky a sloupce. Relevantní pouze v případě, že je s obsahem propojen externí databázový zdroj. Pro manuální aktualizaci databázové oblasti použijeme volbu Data > Obnovit oblast v hlavní nabídce.
Ponechat formátování – použijeme existující formáty buněk prvního datového řádku na celou databázovou oblast.
Neukládat importovaná data – Pokud je vybrána tato možnost, uloží pouze odkaz na zdrojovou databázi; obsah buněk oblasti není zachován.
Zdroj – Zobrazuje informace o aktuální zdroji databáze, pokud existuje. Například „Seznam použité literatury / biblio“.
Operace – Označuje, jaké operace (pokud nějaké) byly použity na databázovou oblast. Například „Seřadit“, „Filtrovat“ nebo „Mezisoučty“.
Klepnutím na tlačítko Přidat přidáme novou oblast do seznamu oblastí pod polem Název.
Pokud chceme zavřít dialogové okno a uložit databázovou oblast, klepneme na tlačítko OK.
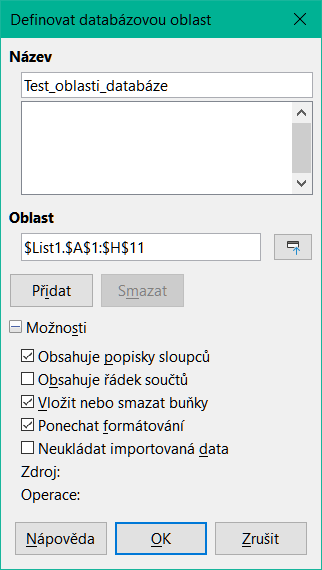
Obrázek 6: Dialogové okno Definovat databázovou oblast
Úprava existující databázové oblasti:
Otevřeme dialogové okno Definovat databázovou oblast pomocí Data > Definovat oblast.
Vybereme oblast ze seznamu oblastí pod polem Název nebo napíšeme jméno oblasti do pole Název. Tlačítko Přidat se změní na tlačítko Změnit.
Provedeme potřebné úpravy v poli Oblast a v části Možnosti.
Klepnutím na tlačítko Upravit aktualizujeme databázovou oblast.
Pokud chceme zavřít dialogové okno a uložit upravenou databázovou oblast, klepneme na OK.
Odstranění existující databázové oblasti:
Otevřeme dialogové okno Definovat databázovou oblast pomocí Data > Definovat oblast.
Vybereme oblast, kterou chceme smazat ze seznamu v horní části dialogového okna.
Klepneme na tlačítko Odstranit a poté klepneme na tlačítko Ano v zobrazeném potvrzovacím dialogu.
Klepnutím na OK zavřeme dialogové okno Definovat databázovou oblast.
Chceme-li vybrat existující oblast databáze z aktuálního dokumentu, otevřeme dialogové okno Vybrat oblast databáze výběrem možnosti Data > Vybrat oblast v hlavní nabídce (obrázek 7). Dále vybereme oblast v seznamu Oblasti a klepneme na OK. Dalším způsobem, jak vybrat existující oblast databáze, je použití nabídky Navigátor na postranní liště. Aplikace Calc automaticky zvýrazní polohu oblasti v listu, ve kterém je umístěna.
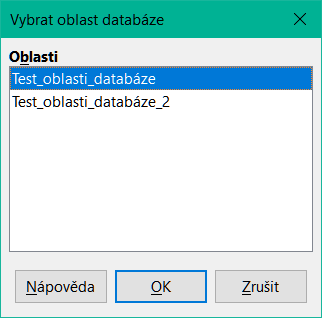
Obrázek 7: Dialogové okno Vybrat oblast databáze
Chceme-li načíst data ze zdroje dat a vytvořit novou oblast databáze, provedeme následující kroky:
Průzkumníka Zdroje dat otevřeme výběrem možnosti Zobrazit > Zdroje dat v hlavní nabídce nebo stisknutím kláves Ctrl + Shift + F4.
V levém podokně okna Průzkumník zdrojů dat klepneme na symbol rozbalení vlevo od názvu zdroje dat, který vás zajímá. Tato akce otevře strom a zobrazí tabulky nebo dotazy spojené se zdrojem dat.
Klepnutím na požadovanou tabulku nebo dotaz se v pravém podokně okna Průzkumník zdrojů dat zobrazí její složky.
Klepnutím na prázdnou obdélníkovou oblast v levém horním rohu pravého podokna okna Průzkumník zdrojů dat vybereme všechna data v zobrazené tabulce nebo dotazu.
Přetáhneme data do buňky, která má být v levém horním rohu dat v tabulce. Další informace o přetahování dat z Průzkumníka zdrojů dat najdeme v nápovědě pod heslem „drag and drop – data source view“.
Calc automaticky vytvoří nový databázovou oblast s výchozími parametry, zahrnující oblast buněk importovaných dat a s výchozím názvem ve tvaru Import1, Import2 atd.
V případě potřeby přejdeme do dialogového okna Definovat databázovou oblast (obrázek 6) a aktualizujeme nastavení nového rozsahu databáze.
Výběrem možnosti Data > Obnovit oblast v hlavní nabídce obnovíme oblast databáze, jakmile jsou aktualizována data v přidruženém zdroji dat. Údaje v listu se aktualizují tak, aby odpovídaly údajům v externí databázi. Registrace a propojení s externími databázovými zdroji je podrobněji vysvětleno v kapitole 10, Propojení dat.
Třídění je proces přeuspořádání dat v oblasti nebo listu podle zadaného pořadí řazení.
Nejjednodušší způsob, jak seřadit databázovou tabulku na základě obsahu jednoho sloupce, je použít nástroje Seřadit vzestupně a Seřadit sestupně, a to následujícím způsobem:
Vybereme libovolnou buňku ve sloupci.
Chceme-li řadit vzestupně, vybereme v hlavní nabídce možnost Data > Řadit vzestupně nebo klepneme na ikonu Řadit vzestupně na Standardní nástrojové liště. Pokud jsme povolili funkci Automatické filtry (viz následující část), můžeme také vybrat Řadit vzestupně v kombinovaném poli Automatické filtry příslušného sloupce.
Chceme-li řadit sestupně, vybereme v hlavní nabídce možnost Data > Řadit sestupně nebo klepneme na ikonu Řadit sestupně na Standardní nástrojové liště. Pokud jsme povolili funkci Automatické filtry, můžeme také vybrat Řadit sestupně v kombinovaném poli Automatické filtry příslušného sloupce.
Při použití nástrojů Seřadit vzestupně a Seřadit sestupně aplikace Calc automaticky identifikuje celý rozsah buněk, který tabulka zabírá, a seřadí celou oblast pouze na základě hodnot v uvedeném sloupci. Zároveň však rozpozná první řádek jako řádek záhlaví a vyloučí jej z třídění.
Pro komplexní třídění použijeme dialogové okno Řadit (obrázek 8), které je dostupné pomocí volby Data > Řadit v hlavní nabídce nebo klepnutím na ikonu Řadit na Standardní nástrojové liště. Pokud před přístupem k dialogovému oknu Řadit vybereme pouze jednu buňku v databázové tabulce, zobrazí se při zobrazení dialogového okna celá tabulka jako vybraná.
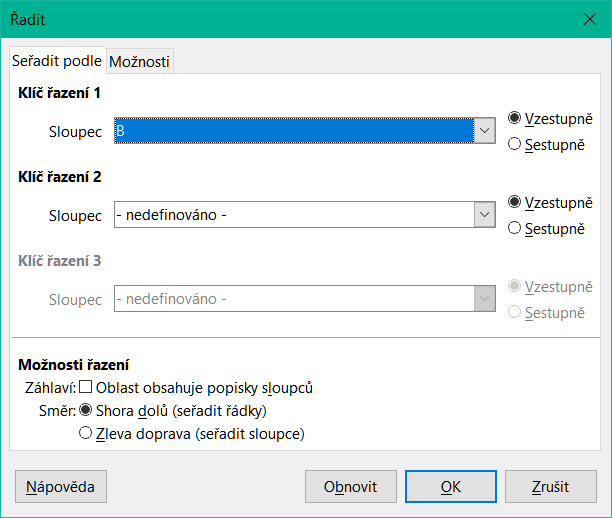
Obrázek 8: Dialogové okno Řadit
Na kartě Seřadit podle dialogového okna můžeme zadat tři úrovně třídění. Data jsou nejprve řazena pomocí hodnot ve sloupce vybraném v rozevíracím seznamu Klíč řazení 1, potom podle hodnot ve sloupci vybraném v rozevíracím seznamu Klíč řazení 2 a nakonec podle hodnot ve sloupci vybraném v rozevíracím seznam Klíč řazení 3. Zaškrtnutím možnosti Záhlaví vyloučíme první řádek (pro třídění podle sloupců) nebo sloupec (pro třídění podle řádků) z třídění se zbytkem dat.
Karta Možnosti dialogového okna Řadit poskytuje další možnosti třídění. Další informace o používání tohoto dialogového okna a jeho možností nalezneme v kapitole 2, Zadávání, úpravy a formátování dat, a v nápovědě.
Filtr je nástroj, který skrývá nebo zobrazuje záznamy v listu na základě sady kritérií filtrování. Podobně jako třídění jsou filtry užitečné pro zkrácení dlouhých seznamů dat, aby bylo možné najít konkrétní datové položky. V aplikaci Calc existují tři typy filtrů:
Automatický filtr
Standardní filtr
Rozšířené filtry
Pokud chceme odstranit filtrování použité na tabulku databáze, jednoduše vybereme Data > Další filtry > Odstranit filtr v hlavní nabídce.
Filtry jsou také popsány v kapitole 2, Zadávání, úpravy a formátování dat
Automatické filtry jsou ze všech tří typů filtrů nejjednodušší. Fungují tak, že umožňují přístup k poli se seznamem prostřednictvím tlačítka se šipkou dolů umístěného v horní části jednoho nebo více datových sloupců (obrázek Chyba: zdroj odkazu nenalezen). Chceme-li přidat Automatický filtr do všech sloupců, klepneme na libovolnou buňku v tabulce a v hlavní nabídce vybereme Data > Automatický filtr, klepneme na ikonu Automatický filtr na Standardní nástrojové liště nebo stiskneme Ctrl + Shift + L. Je také možné přidat Automatický filtr do jednotlivých sloupců pomocí výběru těchto sloupců a následným výběrem Data > Automatický filtr, klepnutím na ikonu Automatický filtr nebo stisknutím Ctrl + Shift + L, ale toto není v databázové tabulce běžně potřeba. Chceme-li otevřít pole se seznamem Automatický filtr pro sloupec, klepneme na tlačítko se šipkou dolů v buňce záhlaví daného sloupce.
Chceme-li odstranit Automatický filtr ze všech sloupců databázové tabulky, klepneme na libovolnou buňku v oblasti tabulky a zvolíme Data > Automatický filtr v hlavní nabídce, vybereme Data > Další filtry > Skrýt automatický filtr v hlavní nabídce, klepneme na ikonu Automatický filtr na Standardní nástrojové liště nebo stisknutím Ctrl + Shift + L. Tlačítka se šipkou dolů v horní části sloupců zmizí.
Tip
Výběrem Data > Automatický filtr, klepnutím na ikonu Automatický filtr a stisknutím Ctrl + Shift + L Automatický filtr zapínáme a vypínáme.
Každé pole se seznamem Automatického filtru nabízí následující možnosti:
Pro základní řazení lze použít možnosti Řadit vzestupně nebo Řadit sestupně.
Filtrování podle barvy má možnosti Barva textu a Barva pozadí pro filtrování řádků na základě barvy textu nebo pozadí použité na buňkách. Klepnutím na jednu z těchto možností otevřeme podnabídku obsahující možnost pro každou aktuálně používanou barvu a poté vybereme barvu požadovanou pro filtrování. Příklad na obrázku Chyba: zdroj odkazu nenalezen odpovídá případu, kdy sloupec A obsahuje buňky, které mají barevné pozadí červené, zelené nebo žluté barvy.
Filtrovat podle podmínky má možnost filtrovat podle prázdných nebo neprázdných řádků.
Filtrovat podle podmínky také umožňuje filtrovat Horních 10 nebo Dolních 10 výsledků. Filtr Horních 10 způsobí, že se zobrazí deset řádků s největšími hodnotami. Pokud je ve sloupci více než deset instancí největší hodnoty, může se zobrazit více než deset řádků. Například pokud existuje jedenáct studentů s dokonalým skóre 100, zobrazí se ve filtru všech jedenáct instancí. Podobně pokud existuje 6 studentů se skóre 100 a šest dalších studentů se skóre 99, pak filtr zobrazí 12 instancí. Filtr Dolních 10 pracuje stejným způsobem, ale s nejnižšími 10 hodnotami. Pokud je v nejnižších hodnotách opět více hodnot, zobrazí se ve výsledcích více než 10 řádků.
Volba Standardní filtr otevře dialogové okno Standardní filtr (obrázek 10) a automaticky nastaví aktuální pole jako pole pro první podmínku v dialogu.
Zaškrtnutí volby Vše zobrazí nebo skryje všechny hodnoty v aktuálním sloupci.
Vedle pole Vše jsou k dispozici tlačítka Zobrazit pouze aktuální položku a Skrýt pouze aktuální položku. V kontextu těchto tlačítek se výraz „aktuální“ vztahuje na položku zvýrazněnou v sadě zaškrtávacích políček pod tlačítky (například „1“ na obrázku 9).
Pokud byl pro sloupec použit nějaký filtr, použijeme volbu Odstranit filtr pro odstranění všech filtrů definovaných pro daný sloupec.
Pole se seznamem Automatický filtr obsahuje zaškrtávací políčka pro každou jedinečnou hodnotu v aktuálním sloupci. Pokud není políčko zaškrtnuto, nezobrazí se řádky tabulky databáze, které obsahují danou hodnotu v tomto sloupci. Změníme stav filtrování určité hodnoty označením nebo odstraněním značky z příslušného zaškrtávacího políčka.
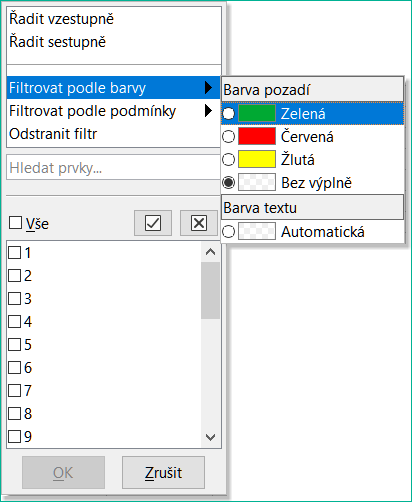
Obrázek 9: Pole se seznamem Automatický filtr
Standardní filtry jsou komplexnější než automatické filtry a umožňují definovat až osm filtračních podmínek. Výkonné filtry lze nastavit pomocí regulárních výrazů. Na rozdíl od automatických filtrů používají standardní filtry dialogové okno (obrázek 10), které je přístupné výběrem možnosti Data > Další filtry > Standardní filtr v hlavní nabídce nebo Standardní filtr v poli se seznamem Automatický filtr.
Další informace o použití tohoto dialogového okna a jeho možnostech najdeme v kapitole 2, Zadávání, úprava a formátování dat.
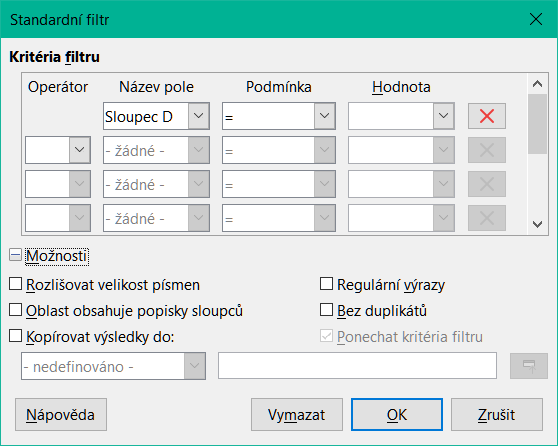
Obrázek 10: Dialogové okno Standardní filtr
Kritéria pro rozšířený filtr jsou uložena v listu, nikoliv zadávána do dialogového okna. Před použitím dialogového okna Rozšířený filtr je proto nutné nejprve nastavit rozsah buněk, který obsahuje kritéria (obrázek 11).
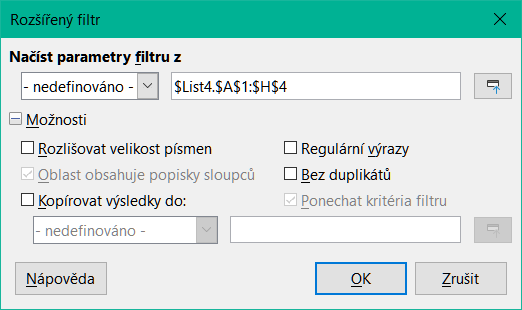
Obrázek 11: Dialogové okno Rozšířený filtr
Pro nastavení oblasti kritérií postupujeme následovně:
Zkopírujeme záhlaví sloupců oblasti, kterou chceme filtrovat, na prázdné místo v listu. Nemusí to být stejný list, kde se nachází zdrojová oblast.
V oblasti kritérií zadáme kritéria filtru pod záhlaví sloupců. Každé jednotlivé kritérium ve stejném řádku je spojeno pomocí AND, zatímco skupiny kritérií jednotlivých řádků jsou spojeny pomocí OR. Prázdné buňky jsou ignorovány. Pro filtr lze definovat až osm řádků kritérií.
Tip
Ačkoli je možné, aby oblast kritérií obsahovala pouze záhlaví sloupců s definovanými kritérii filtru, můžeme se pro zjednodušení rozhodnout zkopírovat do oblasti kritérií všechna záhlaví vaší databázové tabulky.
Po vytvoření oblasti s kritérii nastavíme rozšířený filtr takto:
Vybereme oblast buněk, kterou chceme filtrovat. V případě databázové tabulky můžeme jednoduše klepnout na buňku v oblasti tabulky a Calc automaticky vybere celou tabulku, když otevře dialogové okno v kroku 2) .
Přejdeme na Data > Další filtry > Rozšířený filtr v hlavní nabídce a otevřeme dialogové okno Rozšířený filtr (obrázek 11).
V poli Načíst parametry filtru z zadáme adresu pro pojmenovanou oblast buď výběrem pojmenované oblasti z rozevíracího seznamu, zadáním odkazu nebo výběrem buněk z listu. Při výběru buněk můžeme dočasně dialogové okno zmenšit pomocí tlačítka Zmenšit/Rozšířit.
Klepnutím na tlačítko OK použijeme filtr a zavřeme dialogové okno.
Poznámka
Pro jednotlivé pojmenované oblasti je možné zaškrtnout políčko Filtr v dialogových oknech Definovat název a Spravovat názvy (obrázky 2 , respektive 3 ). V rozevíracím seznamu v oblasti Načíst parametry filtru z dialogového okna Rozšířený filtr lze vybrat pouze pojmenované oblasti označené pro filtrování tímto způsobem. Databázové oblasti nelze vybrat v rozevíracím seznamu.
Možnosti rozšířeného filtru jsou stejné jako možnost standardního filtru a jsou podrobněji popsány v kapitole 2, Zadávání, úprava a formátování dat.
Obrázek 12 ukazuje příklad oblasti kritérií pro příklad klasifikačního listu na obrázku 1.

Obrázek 12: Oblast kritérií rozšířeného filtru (v listu 2)
V této oblasti jsou dvě skupiny kritérií: první zobrazuje záznamy studentů, kteří v každém domácím úkolu dosáhli více než 75 %, a druhá zobrazuje záznamy všech studentů se jménem „Ferdinand“. Obrázek 13 zobrazuje výsledek této operace filtrování podle těchto kritérií.
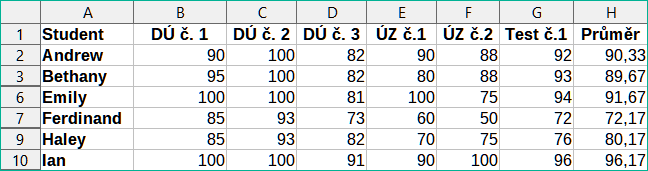
Obrázek 13: Příklad klasifikačního listu filtrovaného pomocí rozšířeného filtru
Dvanáct funkcí v kategorii Databáze nám má pomoci analyzovat jednoduchou databázi, která zabírá obdélníkovou plochu tabulky tvořenou sloupci a řádky, přičemž data jsou uspořádána tak, že každý záznam má jeden řádek. V buňce záhlaví každého sloupce se zobrazuje název sloupce a tento název obvykle odráží obsah každé buňky v daném sloupci.
Funkce v kategorii Databáze přijímají tři následující argumenty:
Databáze. Oblast buněk databáze.
Pole databáze. Sloupec obsahující data, která se mají použít při výpočtech funkce.
Kritéria vyhledávání. Oblast buněk samostatné oblasti tabulky obsahující kritéria vyhledávání.
Tyto argumenty jsou podrobněji popsány níže.
Všechny funkce mají stejnou jednoduchou koncepci ovládání. Prvním logickým krokem je použití zadaných Vyhledávacích kritérií k určení podmnožiny záznamů v Databázi, které mají být použity při následných výpočtech. Druhým krokem je získání hodnot dat a provedení výpočtů spojených s konkrétní funkcí (průměr, součet, součin atd.). Zpracovávají se hodnoty ve sloupci Pole databáze vybraných záznamů.
Následující definice argumentů platí pro všechny funkce kategorie Databáze:
Argument databáze
Argument Pole databáze
Zadáním odkazu na buňku záhlaví v oblasti Databáze. Pokud byla buňka pojmenována jako pojmenovaná oblast nebo oblast databáze, zadáme tento název. Pokud se název neshoduje s názvem definované oblasti, Calc zobrazí chybu #NAME?. Pokud je název platný, ale neodpovídá pouze jedné buňce, Calc ohlásí chybu Err:504 (chyba v seznamu parametrů).
Zadáním čísla určíme sloupec v oblasti Databáze, počínaje číslem 1. Pokud například Databáze obsadil oblast buněk D6:H123, pak zadáním 3 označíme buňku záhlaví na F6. Calc očekává celočíselnou hodnotu, která leží mezi 1 a počtem sloupců definovaným v rámci Databáze, a ignoruje jakékoli číslice za desetinnou tečkou. Pokud je hodnota menší než 1, Calc ohlásí Err:504 (chyba v seznamu parametrů). Pokud je hodnota větší než počet sloupců v Databáze, Calc ohlásí #VALUE!.
Zadáním doslovného názvu záhlaví sloupce z prvního řádku oblasti Databáze a umístěním uvozovek kolem názvu záhlaví; například „Vzdálenost do školy“. Pokud řetězec neodpovídá jednomu z nadpisů sloupců oblasti Databáze, Calc ohlásí chybu Err:504 (chyba v seznamu parametrů). Můžeme také zadat odkaz na libovolnou buňku (ne v oblastech Databáze a Kritéria vyhledávání), která obsahuje požadovaný řetězec.
Argument Kritéria vyhledávání
Počet sloupců, které zabírá oblast Kritéria vyhledávání, nemusí být stejný jako šířka oblasti Databáze. Všechny nadpisy, které se objeví v prvním řádku Kritéria vyhledávání, musí být totožné s nadpisy v prvním řádku Databáze. Ne všechny nadpisy v Databázi se však musí objevit v prvním řádku Kritéria vyhledávání, zatímco nadpis v Databázi se může v prvním řádku Kritéria vyhledávání objevit vícekrát.
Kritéria vyhledávání se zadávají do buněk druhého a následujících řádků oblasti Kritéria vyhledávání pod řádek obsahující nadpisy. Prázdné buňky v oblasti Kritéria vyhledávání jsou ignorovány.
Vytvoříme kritéria v buňkách oblasti Kritéria vyhledávání pomocí operátorů porovnání <, <=, =, <>, >= a >. = se předpokládá, pokud buňka není prázdná, ale nezačíná operátorem porovnání.
Pokud napíšeme několik kritérií do jednoho řádku, jsou spojena pomocí AND. Pokud napíšeme několik kritérií do různých řádků, jsou spojeny pomocí OR.
Kritéria lze vytvářet pomocí zástupných znaků, pokud jsou zástupné znaky povoleny pomocí možnosti Povolit zástupné znaky ve vzorcích v dialogovém okně Nástroje > Možnosti > LibreOffice Calc > Výpočty. Pokud je pro naši tabulku důležitá interoperabilita s programem Microsoft Excel, měla by být tato možnost povolena.
Ještě silnější kritéria lze vytvořit pomocí regulárních výrazů, pokud jsou regulární výrazy povoleny pomocí možnosti Povolit regulární výrazy ve vzorcích v dialogovém okně Nástroje > Možnosti > LibreOffice Calc > Výpočty.
Tip
Při použití funkcí, kde řetězec kritéria vyhledávání může být regulárním výrazem, se nejprve provede převod řetězce kritéria na čísla. Například ".0" se převede na 0.0 a tak dále. V případě úspěchu se nebude jednat o regulární výraz, ale o číselnou shodu. Při přepnutí na lokální prostředí, kde desetinný oddělovač není tečka, však převod regulárního výrazu funguje. Chceme-li vynutit vyhodnocení regulárního výrazu namísto číselného výrazu, použijeme nějaký výraz, který nelze chybně přečíst jako číselný, například ".[0]" nebo ".\0" nebo "(?i).0".
Dalším nastavením, které ovlivňuje způsob zpracování kritérií vyhledávání, je volba Kritéria vyhledávání = a <> musí platit pro celé buňky v dialogovém okně Nástroje > Možnosti > LibreOffice Calc > Výpočet. Tato možnost určuje, zda se kritéria vyhledávání nastavená pro funkce Databáze musí přesně shodovat s celou buňkou. Pokud je pro naši tabulku důležitá interoperabilita s programem Microsoft Excel, měla by být tato možnost povolena.
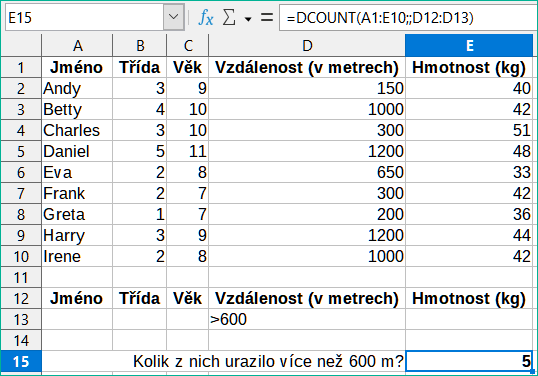
Obrázek 14 – Příklad použití funkce Databáze
Obrázek 14 představuje jednoduchý příklad použití jedné z funkcí v kategorii Databáze. Vzorec ve vybrané buňce E15 je vidět na liště vzorců a obsahuje volání funkce DCOUNT. Argumenty volání této funkce jsou následující:
Argument databáze. Databázová tabulka použitá pro tento příklad se rozprostírá v oblasti buněk A1:E10.
Argument Pole databáze. Protože funkce DCOUNT počítá záznamy, které vyhovují kritériím, bez dalšího výpočtu, není nutné uvádět hodnotu tohoto argumentu, ačkoli je třeba uvést příslušné oddělovače argumentů (v tomto případě čárky).
Argument Kritéria vyhledávání. Oblast vyhledávacích kritérií použitá v tomto příkladu zasahuje do oblasti buněk A12:E13. Podmínka v buňce D13 („>600“) způsobí, že DCOUNT spočítá všechny záznamy, které mají ve sloupci Vzdálenost (metry) hodnotu větší než 600 metrů. V mnoha případech může být vhodné kopírovat záhlaví sloupců databázové tabulky v oblasti kritérií vyhledávání, jak je znázorněno na obrázku 14. To však není podstatné a vzorec =DCOUNT(A1:E10,,D12:D13) by dal přesně stejnou hodnotu 5.
Mnoho dalších příkladů nalezneme po vyhledání „databázových funkcí“ v systému nápovědy nebo na příslušné stránce každé funkce ve Wiki o funkcích Calc na adrese https://wiki.documentfoundation.org/Documentation/Calc_Functions.
Poznámka
Calc bude při výpočtech pomocí těchto funkcí považovat data a logické hodnoty (například TRUE nebo FALSE) za číselné.
DAVERAGE
DCOUNT
DCOUNTA
DGET
DMAX
DMIN
DPRODUCT
DSTDEV
DSTDEVP
DSUM
DVAR
DVARP
Program Calc obsahuje více než 500 funkcí, které nám pomohou analyzovat a odkazovat na data. Některé z těchto funkcí jsou určeny pro použití s tabulkovými daty (například HLOOKUP a VLOOKUP), zatímco jiné lze použít v jakémkoli kontextu. Tato část obsahuje seznam některých funkcí, které mohou být užitečné, pokud hodláme pro svou databázi používat tabulky v Calcu. Mnohé z nich budou známé jako typické funkce tabulkového procesoru používané v jiných kontextech, zatímco některé mohou být méně často používané, ale jsou obzvláště užitečné při práci s databázovými tabulkami.
Další referenční materiály ke všem funkcím Calcu najdeme v nápovědě a v oblasti Funkce Calc (Calc Functions) na wiki The Document Foundation na adrese https://wiki.documentfoundation.org/Documentation/Calc_Functions.
|
Funkce |
Kategorie |
Popis |
|
AGGREGATE |
Matematické |
Vrátí celkový výsledek vypočtený použitím vybrané agregační funkce na zadaná data. K dispozici je devatenáct volitelných agregačních funkcí, včetně průměru, počtu, velkého počtu, maxima, mediánu, minima, módu, percentilu, součinu, kvartilu, malého počtu, směrodatné odchylky, součtu a rozptylu. |
|
AVERAGE |
Statistické |
Vrátí aritmetický průměr zadaných dat, přičemž ignoruje prázdné buňky a buňky obsahující text. |
|
AVERAGEA |
Statistické |
Vrátí aritmetický průměr zadaných dat, přičemž ignoruje prázdné buňky, ale každé buňce obsahující text přiřadí hodnotu 0. |
|
AVERAGEIF |
Statistické |
Vrátí aritmetický průměr všech buněk v rozsahu, které splňují dané kritérium. |
|
AVERAGEIFS |
Statistické |
Vrátí aritmetický průměr všech buněk v rozsahu, které splňují více kritérií ve více rozsazích. |
|
CHOOSE |
Sešit |
Vrátí jednu hodnotu ze zadaných dat vybranou podle indexu předaného jako argument. |
|
COUNT |
Statistické |
Vrátí počet číselných hodnot v zadaných datech, přičemž ignoruje prázdné buňky a buňky obsahující text. |
|
COUNTA |
Statistické |
Vrátí počet číselných a textových hodnot v zadaných datech, přičemž ignoruje prázdné buňky. |
|
COUNTBLANK |
Statistické |
Vrací počet prázdných buněk v zadaných datech. |
|
COUNTIF |
Statistické |
Vrátí počet buněk v rozsahu, které splňují dané kritérium. |
|
COUNTIFS |
Statistické |
Vrátí počet buněk, které splňují více kritérií ve více oblastech. |
|
HLOOKUP |
Sešit |
Vyhledá zadanou hodnotu v prvním řádku tabulky (často záhlaví sloupce) a vrátí hodnotu získanou ze stejného sloupce, ale z jiného řádku. HLOOKUP znamená horizontální vyhledávání. |
|
INDEX |
Sešit |
Vrátí obsah jedné buňky tabulky. Pozice této buňky je určena posunem řádku a sloupce. Lze jej použít také v kontextu vzorce pole pro získání dat z více buněk. |
|
INDIRECT |
Sešit |
Vrací platný odkaz vytvořený ze zadané řetězcové reprezentace odkazu. Tato funkce je výkonná, protože umožňuje uživateli vytvářet dynamické odkazy. |
|
LOOKUP |
Sešit |
Vyhledá zadanou hodnotu v jednom řádku nebo sloupci a vrátí hodnotu ze stejné pozice v druhém řádku nebo sloupci. Není nutné, aby vyhledávací a výsledková oblast sousedily. |
|
MATCH |
Sešit |
Vrátí relativní pozici hledané položky v jednom řádku nebo sloupci. |
|
MAX |
Statistické |
Vrátí maximální hodnotu v zadaných datech, přičemž ignoruje prázdné buňky a buňky obsahující text. |
|
MAXA |
Statistické |
Vrátí maximální hodnotu v zadaných datech, přičemž ignoruje prázdné buňky, ale každé buňce obsahující text přiřadí hodnotu 0. |
|
MAXIFS |
Statistické |
Vrátí maximální hodnotu všech buněk v rozsahu, které splňují více kritérií ve více rozsazích. |
|
MEDIAN |
Statistické |
Vrátí mediánovou hodnotu zadaných dat. Medián konečného seznamu čísel je "prostřední" číslo, pokud jsou tato čísla seřazena od nejmenšího po největší. |
|
MIN |
Statistické |
Vrátí minimální hodnotu v zadaných datech, přičemž ignoruje prázdné buňky a buňky obsahující text. |
|
MINA |
Statistické |
Vrátí minimální hodnotu v zadaných datech, přičemž ignoruje prázdné buňky, ale každé buňce obsahující text přiřadí hodnotu 0. |
|
MINIFS |
Statistické |
Vrátí minimální hodnotu všech buněk v oblasti, které splňují více kritérií ve více oblastech. |
|
MODE MODE.SNGL |
Statistické |
Vrací hodnotu režimu zadaných dat. Režim je nejběžnější hodnota v seznamu hodnot. Pokud existuje několik hodnot se stejnou frekvencí, je vrácena nejmenší hodnota. |
|
MODE.MULT |
Statistické |
Vrací vertikální pole hodnot režimu zadaných dat. Režim je nejběžnější hodnota v seznamu hodnot. Funkce vrací více než jednu hodnotu, pokud existuje více režimů se stejnou četností výskytu. |
|
OFFSET |
Sešit |
Vrátí upravený odkaz na jednu buňku nebo oblast buněk posunutý o určitý počet řádků a sloupců od daného referenčního bodu. |
|
PRODUCT |
Matematické |
Vrátí součin číselných hodnot v zadaných datech, přičemž ignoruje prázdné buňky a buňky obsahující text. |
|
STDEV STDEV.S |
Statistické |
Vrátí výběrovou směrodatnou odchylku zadaných dat, přičemž ignoruje prázdné buňky a buňky obsahující text. |
|
STDEVA |
Statistické |
Vrátí výběrovou směrodatnou odchylku zadaných dat, přičemž ignoruje prázdné buňky, ale každé buňce obsahující text přiřadí hodnotu 0. |
|
STDEVP STDEV.P |
Statistické |
Vrátí směrodatnou odchylku populace zadaných dat, přičemž ignoruje prázdné buňky a buňky obsahující text. |
|
STDEVPA |
Statistické |
Vrátí směrodatnou odchylku populace zadaných dat, přičemž ignoruje prázdné buňky, ale každé buňce obsahující text přiřadí hodnotu 0. |
|
SUBTOTAL |
Matematické |
Vrátí celkový výsledek vypočtený použitím vybrané součtové funkce na zadaná data. K dispozici je jedenáct volitelných součtových funkcí, včetně průměru, počtu, maxima, minima, součinu, směrodatné odchylky, součtu a rozptylu. Tuto funkci použijeme spolu s funkcí Automatický filtr, abychom brali v úvahu pouze filtrované záznamy. |
|
SUM |
Matematické |
Vrátí součet zadaných dat, přičemž ignoruje prázdné buňky a buňky obsahující text. |
|
SUMIF |
Matematické |
Vrátí součet všech buněk v oblasti, které splňují dané kritérium. |
|
SUMIFS |
Matematické |
Vrátí součet všech buněk v oblasti, které splňují více kritérií ve více oblastech. |
|
VAR VAR.S |
Statistické |
Vrátí variantu vzorku zadaných dat, přičemž ignoruje prázdné buňky a buňky obsahující text. |
|
VARA |
Statistické |
Vrátí variantu vzorku zadaných dat, přičemž ignoruje prázdné buňky, ale každé buňce, která obsahuje text, přiřadí hodnotu 0. |
|
VARP VAR.P |
Statistické |
Vrátí populační odchylku zadaných dat, přičemž ignoruje prázdné buňky a buňky obsahující text. |
|
VARPA |
Statistické |
Vrátí populační variaci zadaných dat, přičemž ignoruje prázdné buňky, ale každé buňce, která obsahuje text, přiřadí hodnotu 0. |
|
VLOOKUP |
Sešit |
Vyhledá zadanou hodnotu v prvním sloupci tabulky (často v záhlaví řádku) a vrátí hodnotu získanou ze stejného řádku, ale z jiného sloupce. VLOOKUP znamená vertikální vyhledávání. |